皆さん、Claude Codeを日常的に使っていますか?
Sub-agent、Skills、Plan Mode、Memoryなど、Claude Codeにはここ1年で多くの機能が追加されてきました。AGIラボでもそれぞれの機能を個別に紹介してきましたが、今回はこれらの機能を 組み合わせて1つの開発ワークフローにする 使い方をご紹介します。
筆者が日常的に実践しているのは、「 Sub-agentで前調査 → Plan Modeで設計 → Skills/Memory/CLAUDE.md等を活かして実装 」という3ステップのフローです。本記事では、実際にアプリを1つ開発しながら、このワークフローの具体的な進め方を解説していきます。
各機能の基本的な使い方は以下の過去記事で詳しく解説していますので、あわせて参考にしてみてください!
https://agi-labo.com/articles/n89373dc9a9d3
https://agi-labo.com/articles/n072772f45d83
筆者のワークフロー全体像
まず、本記事で紹介するワークフローの全体像を示します。
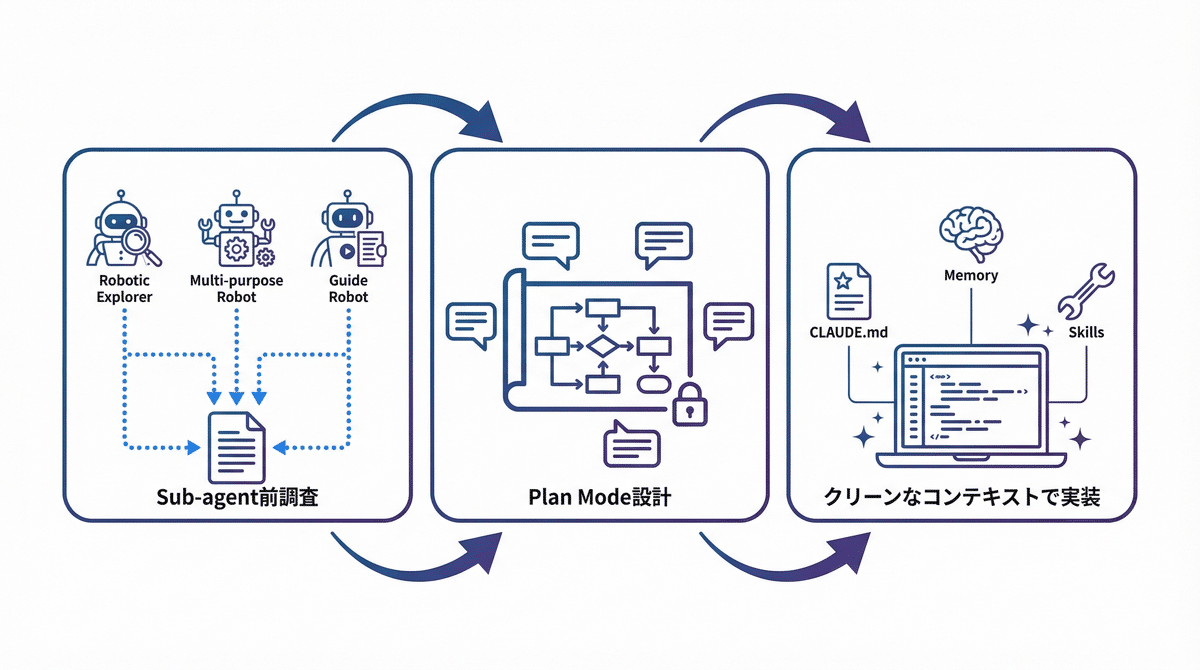
ステップ①: Sub-agentで前調査
複数のSub-agentを並列で起動して、コードベース探索・Web調査・技術選定などを同時に進めます。ポイントは、Sub-agentが内部でどれだけ大量の情報を読み込んでも、本体のコンテキストには 要約だけ が返ることです。本体のコンテキストはクリーンなままで、作業や計画に必要な情報だけメインのエージェントに渡されるためコンテキスト圧縮の頻度も減り記憶漏れで伝え直す必要や、実装ミスなどが減ります。
基本的にはここで次のPlan Modeで本格的に新機能の設計に入る前に必要な前情報やそのために必要な要求(どういう機能がほしいかなど実現したいこと)を明確にしておくことで、この後出来上がる機能の品質が決まるので全て伝えておくのが重要です。
※Sub-agentを用いた調査はかなりトークンを使うので使い方には注意が必要です。重い調査だと 一回で100Kトークン を平気で超えてくるので、軽量なモデルで調査を行っているとはいえ使用量やAPI料金などに注意して使ってください。
ステップ②: Plan Mode + 本体で壁打ち
前調査の結果を踏まえて、Plan Modeで設計計画を立て、本体で方針を議論・確定します。基本的にはそこまでの会話内容を元に実装計画を立てるために必要な情報をエージェントが追加調査を行い、 実装計画を確認して承認するだけ です。
基本的には実装計画のみを引き継いで次に進めて、 そこまでのコンテキストは無くしたほう が途中でコンテキスト圧縮が挟まったりして実装が破綻することが減るのでお勧めです。
公式も実装作業の際は余計なコンテキストは無くすことを推奨しているため、Plan Modeから実行に移る際もその前提で設計されているように感じます。
ステップ③: クリーンなコンテキストで実装
新しいセッションを開始し、実装を開始します。調査で消費したコンテキストは一切残っていませんが、CLAUDE.md・Auto Memory・Skills等が自動的に読み込まれるので、前のセッションで決めたことはしっかり引き継がれます。
なぜこのフローなのか
従来の「全部1セッションでやる」やり方だと、調査段階で大量のファイル内容を読み込むため、実装フェーズでは途中でコンテキストが圧縮されて重要な情報が消えてしまうことがありました。セッションが長くなるほど精度が落ちる、という経験をされた方も多いのではないでしょうか。
3ステップに分けることで、調査はSub-agentに任せてコンテキストをクリーンに保ち、意思決定はMemory(もしくはADRやAI用のmemoフォルダなど)に残して新セッションに引き継ぐ。これにより、実装時に精度が落ちる問題を解消できます。
Sub-agentについて
Sub-agent自体は自分で指示やツールを渡して実行する機能を指すことが多いですが、今回は 「Sub-agentで調査して」などと伝えて起動するTask・Exploreで動作するデフォルトで備わっているSub-agentのこと を指しています。
なので、基本的には メインの会話スレッドとは独立したコンテキストで活動し、活動の結果集めた情報の要約をメインの会話スレッドに提供するエージェント という位置づけで話していきます。
実際にそのワークフローで開発してみる
ワークフローの実演として、1つアプリを開発していきます。
今回作るのは 「AIモデル性能比較ダッシュボード」 です。LLMの学術ベンチマーク(MMLU等)を自分の環境で実行し、モデル間の性能を比較・可視化できるWebアプリです。
主な機能
・ベンチマーク実行: OSSツール「lm-evaluation-harness」を使い、MMLUなどの学術ベンチマークを各モデルで実行
・モデル比較: GPT / Claude / Gemini の結果をチャートで比較表示
・プロンプト管理: ベンチマーク用のプロンプトテンプレートを保存・バージョン管理
・コスト記録: 各ベンチマーク実行にかかったAPIコストを記録・グラフ表示
大手AIベンダー(OpenAI、Anthropic、Google等)はそれぞれ自社独自の評価基盤を持っていて、公式に発表されるベンチマーク数値は各社の方法で計測されたものです。OSSの lm-evaluation-harness (EleutherAI開発、GitHub Stars 11,500+)を使えば、 同じ条件で公平にモデルを比較 できます。