はじめに
2026年に入り、 Claude Code がローカルLLMで動かせる時代 がやってきました。Anthropic 公式が ANTHROPIC_BASE_URL という環境変数を介して、自前のLLMサーバへの接続をネイティブサポートしています。
LM Studio や Ollama も Anthropic 互換APIを実装し、「ローカル版 Claude Code」のセットアップは劇的に簡単になりました。
ただ、ここで素朴な疑問が浮かびます。
「実際、Opus 4.7 と比べてどうなの?速度は?精度は?本当に実務で使い物になるの?」
ネット上には「セットアップしてみた」「動いた」という日本語記事は多数あります。Opus と並べた検証記事もすでにいくつか公開されています。 にもかかわらず、結論が記事ごとに大きく異なる ..「ローカルは数百倍遅い」と断ずる記事もあれば、「Cloud と互角まで来た」と評する記事もあるのが現状です。
そこで本記事では、 自宅の Mac Studio M5 Pro Max 128GB で実際にローカル LLM を立ち上げ、 Opus 4.7 と並べて手元で検証 しました。
検証したのは以下です:
5 種類のローカルモデル (Qwen3.6-35B-A3B、Qwen3.6-27B、Gemma 4 26B-A4B、Gemma 4 31B、Qwen3-Coder)の Cold / Warm 応答時間
ツール呼び出し (Read / Bash / WebSearch)の動作確認と Opus との応答比較
Google Sheets クローンを Opus / Qwen3.6-35B-A3B / Qwen3.6-27B dense / Qwen3-Coder の 4 モデル で作成して、実用アプリ生成力を比較
「動いた、で終わらない。 実際に並べて触ってみて、 Opus と並べて使えるラインはどこか を、データで答える」のが本記事のスタンスです。
本記事の前提知識(既存AGIラボ記事へのリンク)
本記事は以下の3部作の続編・実検証編として位置づけられます。基本的な内容はそちらを参照ください。
最初に結論
推奨構成(2026年5月時点)
3 行で結論
モデル : Qwen3.6-35B-A3B-bf16 (warm 4.5 秒、ツール連鎖が安定)
サーバ : oMLX 直結 (ccr / YaRN / 自作プロキシは不要、設定 4 行)
覚悟しておくこと : WebSearch は MCP 追加が必要 。 大規模コーディングを伴う作業は 27B (dense) や Qwen3-Coder に切替
上記結論に至った具体的な実証結果を以下で詳しく紹介していきます。
メインサーバー:oMLX
🖥️ サーバは何を使うべきか:oMLX / Ollama / LM Studio 比較
サーバーで主要なものは上記の3種類です。違いは以下です。

一言で言うと、 oMLXはApple Silicon 最速の MLX、Ollamaは全 OS 対応の定番、LM Studioはフル GUIで初心者最強。
記事によって採用されているサーバーの種類は様々ですが、選択によって速度がかなり変わってくるので、一番メジャーなoMLX と Ollama について比較検討しました。
Ollama vs oMLX
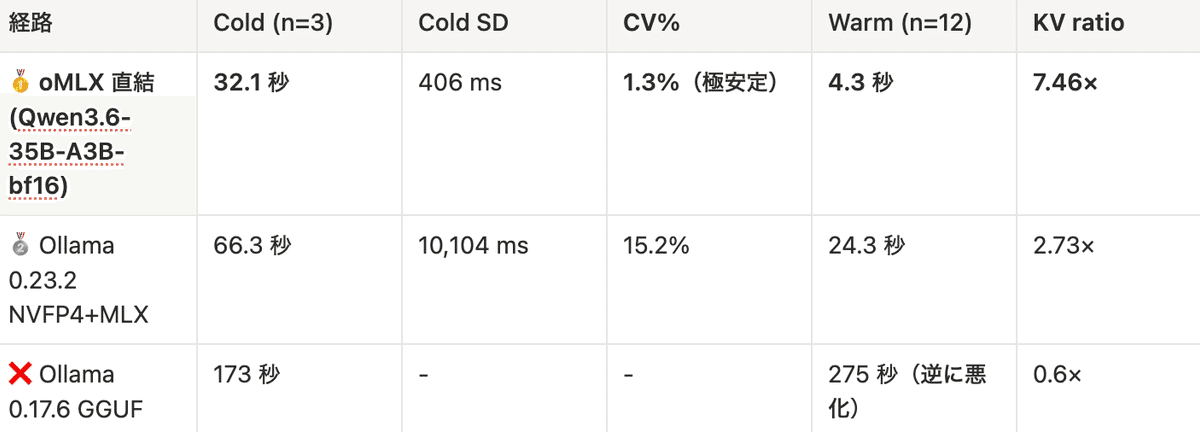
結論
検証では、Apple Silicon でコーディングに本気で使うなら oMLX が最適な結果となりました 。
oMLXはKV キャッシュにより、2回目以降プロンプトを共有し、レスポンス速度がかなり早くなります。ただし、セッティングの複雑さを考えるとOllamaやLM Studioも一考の余地はあります。
続いてはモデル選択です。
メインモデル:Qwen3.6-35B-A3B-bf16
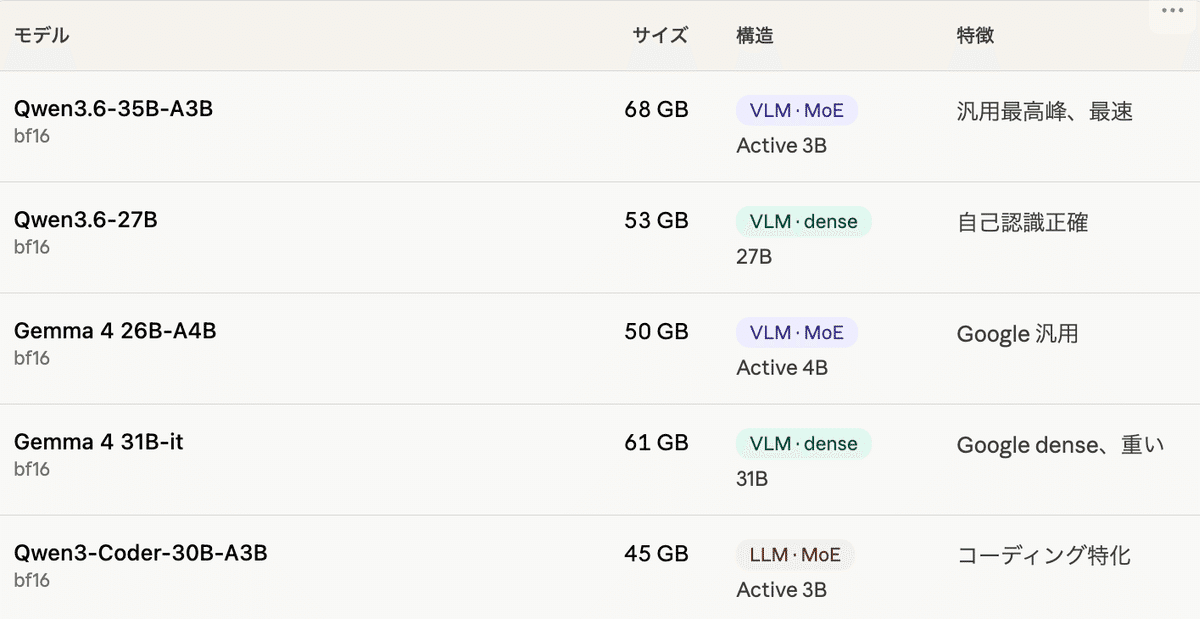
サーバが決まったところで、次は どのモデルを動かすか です。oMLX 上で動かせる主要 5 モデルを、 Mac Studio M5 Pro Max 128GB で同条件比較しました。
検証対象 5 モデル
Cold / Warm レスポンス時間(実測)
ローカル LLM の速度を測るとき、 「Cold-start」 (サーバ再起動直後=KV キャッシュ空)と 「Warm」 (cache hit、2回目以降)で 大きく違う ことを押さえる必要があります。
検証に使ったプロンプト
各モデルで以下の 5 タスク を順番に投げて、その所要時間を測定しました。
Task 1: Reply: pong
Task 2: What is two plus two. Reply with just the number.
Task 3: Write a Python one-liner that returns sum of list 1 2 3 4 5. Just code. Task 4: What model are you. Briefly.
Task 5: Pythonでフィボナッチ数を計算する関数を1行で書いて
Cold / Warm の定義
Cold = Task 1 (サーバ完全再起動 + KV cache 削除直後の 初回応答 )
Warm = Task 2-5 の 4 タスクから中央値 (cache hit が効いた状態の安定値)
注目すべきは Warm 中央値 です。 Qwen3.6-35B-A3B-bf16 は warm 4.4 秒 で、Cloud Opus とほぼ同じ体感速度を実現しています。一方、 dense モデル(Qwen 27B / Gemma 31B)は 14〜43 秒 と、明確に重い。
実際にローカルで動かしてみる
理論値だけでなく、 実機で動いているところ をお見せします。
理論値だけでなく、 読者の手元でも再現できる手順 を最短ルートで紹介します。
Step 1:oMLX をインストール
# Homebrew(推奨)
brew install ggozad/tap/omlx
# または GitHub Releases から .pkg をダウンロード
# https://github.com/ggozad/omlx/releases
Step 2:モデルをダウンロード
oMLX は HuggingFace の MLX 形式モデルをそのまま利用できます。
# Qwen3.6-35B-A3B-bf16(本記事の推奨モデル、約 71GB)
omlx pull mlx-community/Qwen3.6-35B-A3B-bf16
# 起動 + バックグラウンド常駐
omlx serve --host 0.0.0.0 --port 8087 &
Step 3:~/.omlx/settings.json に Claude Code 向け設定を追記
ここが 本記事のキモ 。 claude_code セクションが Anthropic 互換 API + 長コンテキスト対応を有効化します。
{
"claude_code": {
"enabled": true,
"mode": "local",
"context_scaling_enabled": true,
"max_context_window": 262144,
"opus_model": "Qwen3.6-35B-A3B-bf16",
"sonnet_model": "Qwen3.6-35B-A3B-bf16",
"haiku_model": "Qwen3.6-35B-A3B-bf16"
}
}context_scaling_enabled: true がないと、Claude Code の system prompt(約 51k トークン)が入らず即エラーになります。 これを設定するかしないかが分岐点 。
Step 4:Claude Code をローカル接続で起動
環境変数 4 つを claude の前に置くだけ。
env -u ANTHROPIC_API_KEY \
ANTHROPIC_BASE_URL=http://127.0.0.1:8087 \
ANTHROPIC_AUTH_TOKEN=dummy \
ANTHROPIC_DEFAULT_OPUS_MODEL=Qwen3.6-35B-A3B-bf16 \
ANTHROPIC_DEFAULT_SONNET_MODEL=Qwen3.6-35B-A3B-bf16 \
ANTHROPIC_DEFAULT_HAIKU_MODEL=Qwen3.6-35B-A3B-bf16 \
claude
claude の対話 UI がそのまま立ち上がり、 バックエンドだけが Qwen に差し替わった状態 で動きます。
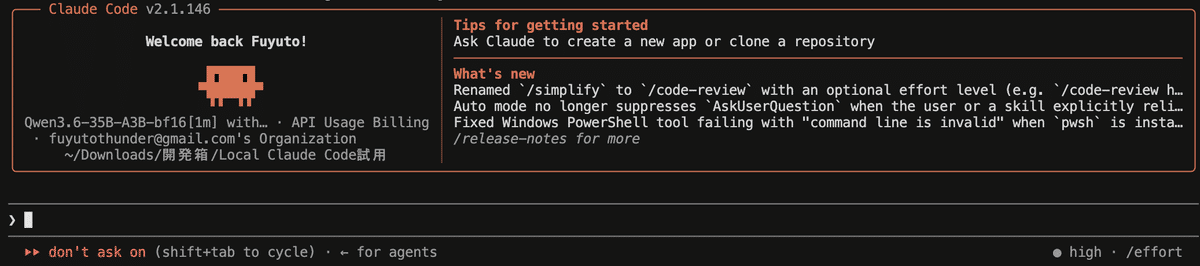
Claude Code 起動画面(バックエンドが Qwen3.6-35B-A3B に差し替わっている)
Step 5:実際に応答を確認
例えば「Pythonの GIL について 300 字で日本語で説明」と投げた結果:
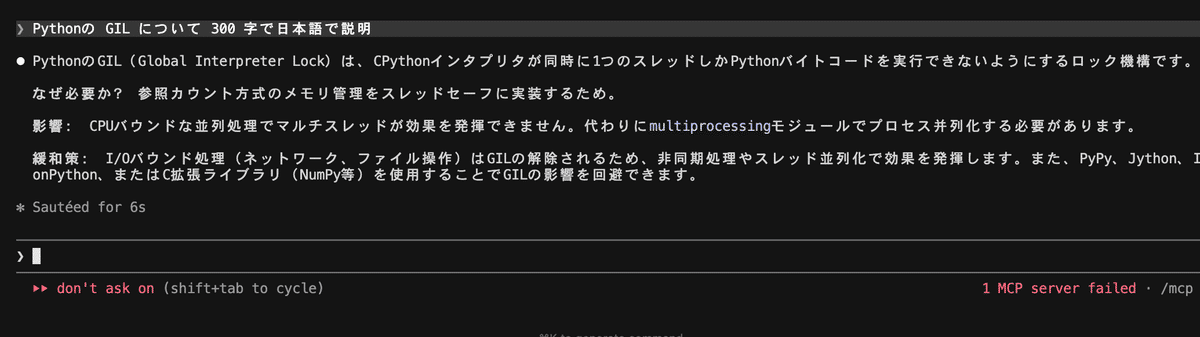

約 6.0 秒で応答完了 。一部漢字変換が誤っているものの内容は的確で、Cloud Opus と区別がつきません。
現在、note の AGIラボ メンバーシップでは、新規加入の受付を一時的に停止しています。
これから参加される方は、新サイト agi-labo.com からお申し込みください。(詳細)
※ 新サイトの詳細はこちらです。(Emailを設定するとnoteラボメンバーも新サイトにログイン可能です)