

はじめに
2025年から2026年にかけて、AI業界に大きな地殻変動が起きています。
かつては「GPT-4を超えるには数億ドルの投資が必要」と言われていましたが、DeepSeek-V3がわずか600万ドルでGPT-4並みの性能を達成。Llama
4やQwen3といったオープンモデルも急速に進化しています。
さらに2026年に入り、Qwen3-TTS(音声合成)やPersonaPlex-7B(リアルタイム音声対話)など、テキスト以外の生成AIもオープンソース化が加速しています。
こうした流れの中で、LocalLLM(ローカルLLM)、クラウドではなく自社環境で動かす大規模言語モデル——に注目が集まっています。
セキュリティ:機密データを外部に送信しない
コスト削減:API従量課金から解放される
カスタマイズ:自社データで独自AIを構築できる
「とはいえ、ローカルで動かすAIは性能が落ちるのでは?」——そう思う方も多いかもしれません。
本記事では、2026年最新のLocalLLMモデルを徹底比較し、MacBook Air
M4で実際にビジネスメールを生成する実演を行いました。結論から言えば、軽量モデルでも数秒で実務レベルの文章が生成できます。
「まず試してみる」から「本格導入を検討する」まで、段階に応じた情報をお伝えしていきます。
LocalLLMとは?
LocalLLMとは、クラウド環境ではなく、自社のPCやオンプレミスサーバーで稼働する大規模言語モデルのことです。
ChatGPTやClaude APIのようなクラウドサービスでは、ユーザーの入力データが外部サーバーに送信されます。一方、LocalLLMはインターネット接続を必要とせず、すべてのデータ処理を手元で完結できるのが特徴です。
クラウドLLMとの違い

なぜ今LocalLLMなのか?
2025年以降、LocalLLMが急速に普及している背景には3つの要因があります。
オープンモデルの性能向上:DeepSeek-V3やQwen3がGPT-4oクラスの性能を達成
ハードウェアコストの低下:RTX 5090のデュアル構成がH100の25%の価格で同等性能に
規制強化への対応:個人情報保護法への対応でデータ国内保管のニーズ増
2026年 最新LocalLLMモデル徹底比較
2026年1月現在、注目すべきオープンモデルを解説します。
1. Qwen3(Alibaba)
Alibaba Cloudが開発する多言語対応モデルファミリー。日本語の性能が高いと評判です。Apache 2.0ライセンスで商用利用可能なのが強みです。

主なバリアント:
Qwen3(0.6B〜235B):汎用モデル、119言語対応、ハイブリッド思考モード搭載。4Bが72B級の性能を発揮
Qwen3-Coder-480B:エージェント型コーディングモデル、LiveCodeBench・SWE-benchで上位
Qwen3-Omni:テキスト+音声+画像+動画の統合マルチモーダル
強み:多言語、数学・コーディング、小型モデルの高性能、マルチモーダル
↓過去記事はこちら
https://agi-labo.com/articles/n7187c14e2ded
2. DeepSeekV3.2
中国・杭州のAIスタートアップが開発。MITライセンスで完全オープン、GPT-4.5超えの性能が特徴です。

主なバリアント:
V3.2:汎用モデル、IMO・IOIでゴールドメダルレベルの数学・推論性能
V3.2-Speciale:ツール非対応だが推論特化、競技プログラミング向け
VL2:ビジョン言語モデル、画像理解で最高効率(24GB+ VRAM)
強み:数学・推論、コード分析、長文処理、コスト効率
3. Llama 4(Meta)
Metaが開発するオープンウェイトモデル。MoEアーキテクチャでネイティブマルチモーダル対応、200言語をサポートしています。

主なバリアント:
Scout:軽量版、1,000万トークンの超長文コンテキスト
Maverick:マルチモーダル対応(テキスト+画像入力)
Behemoth(288B/2T):トレーニング中、GPT-4.5超えを予告
強み:超長文処理、マルチモーダル、多言語(200言語)
4. Mistral AI
フランス発のAIスタートアップ。Apache 2.0ライセンスでフロンティアレベルの性能を提供しています。

主なバリアント:
Mistral Large 3:汎用MoEモデル、40言語以上対応、画像理解可能
Devstral 2:コーディング特化、Dense構造で安定した推論、Claude 3.5 Sonnet代替
強み:推論、エージェントワークフロー、コーディング
参考:Mistral AI
5. Kimi K2(Moonshot AI)
北京のMoonshot AIが開発した1兆パラメータのMoEモデル。256Kトークンのコンテキストでリポジトリ全体を処理可能です。

主なバリアント:
K2:コーディング特化、コスト効率最高
(API: $0.60/$2.50 per M tokens(input/output))K2 Thinking:推論強化版、エージェントワークフローに最適化
強み:長文コード処理、コスト効率、推論
参考:Kimi-K2
6. GPT-OSS(OpenAI)
OpenAI初のオープンウェイトモデル。GPT-4レベルの推論性能とツール呼び出し機能を備えています。

強み:推論、ツール呼び出し、エージェントワークフロー
参考:OpenAI
7. Gemma 3(Google)
GoogleがGemini 2.0の技術を活かして開発。27Bモデルが405B級の性能を発揮し、軽量モデルでも高性能です。

強み:画像理解、軽量高性能、140言語対応
参考:Google Gemma
8. GLM-4.7(Zhipu AI)
清華大学発のZhipu AIが開発。10Bクラスながら大型モデルを上回る性能を発揮します。

強み:コーディング、ツール呼び出し、中国語タスク
https://x.com/Zai_org/status/2013261304060866758?s=20
参考:Zhipu AI
9. Phi 4(Microsoft)
Microsoft Research製。16Bパラメータで70B級の推論性能を実現し、高品質な合成データによる学習が特徴です。
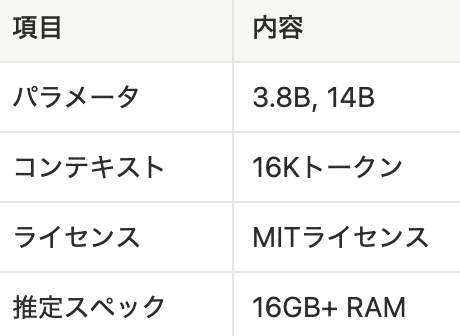
強み:推論タスク、コスト効率
10. Nemotron 3 Nano(NVIDIA)
NVIDIAが開発したハイブリッドMoEモデル。30Bから3Bのみをアクティベートし、1Mトークンのコンテキストと4倍のスループットを実現しています。

強み:高スループット、長文処理、マルチエージェントシステム
参考:NVIDIA
11. LFM2.5(Liquid AI)
従来のTransformerとは異なるLiquid Foundation Modelアーキテクチャを採用。アテンションを約20%に抑え、CPU上でもQwen3比で2倍高速に動作します。

主なバリアント:
LFM2.5-1.2B-Instruct:汎用チャット向け
LFM2.5-1.2B-JP:日本語に特化したモデル
LFM2.5-VL-1.6B:画像理解(Vision-Language)
LFM2.5-Audio-1.5B:音声入出力対応(前世代比8倍高速)
強み:エッジデバイス最適化、日本語特化、音声対応
参考:LFM2.5公式ブログ
テキスト以外のLocalAI
テキスト生成だけでなく、音声・動画・音楽の生成もローカルで実行できる時代になっています。
音声生成・クローン
・Qwen3-TTS: 10言語対応、声のデザイン・クローンが可能
お試し→https://huggingface.co/spaces/Qwen/Qwen3-TTS
・PersonaPlex-7B: リアルタイム音声→音声、OpenAI Realtime API代替
お試し→https://github.com/NVIDIA/personaplex#js-repo-pjax-container
Qwen3-TTSは0.6B〜1.8Bの軽量モデルで、わずか5秒の音声サンプルから自然なクローン音声を生成できます。ナレーションや電話対応の自動化に活用できそうです。
https://x.com/ui_nyan/status/2015250019918696671
NVIDIAのPersonaPlex-7Bはリアルタイム音声対話ができる軽量モデルです。
https://x.com/HuggingModels/status/2014788077924040729
動画生成
LTX-2はローカルマシンで4K・最大20秒の動画を生成できるオープンソースモデルです。音声付き動画の生成にも対応しています。
https://x.com/venturetwins/status/2010878914273697956?s=20
音楽生成
HeartMulaはSUNOのオープンソース代替として注目されています。完全オフラインで音楽生成が可能です。
https://x.com/aisearchio/status/2013457394789945763?s=20
日本語の生成事例:
https://x.com/k0ta0uchi/status/2013483380122468418?s=20
続いては、気になるLocalLLMの日本語性能を実際に検証していきます。MacBook Air M4で複数のモデルを動かし、ビジネスメール作成タスクで速度と品質を比較しました。





