

はじめに
日本時間2026年3月、GitHubのGlobal Trendingで1位を獲得したプロジェクトがあります。その名は MiroFish 。
開発したのは、北京郵電大学の4年生・郭航江氏。わずか 10日間のVibe Coding でプロトタイプを完成させ、複数の中国語メディアの報道によると、公開から 24時間以内に盛大グループ創業者の陳天橋氏から約6億円(3,000万元)の出資 を獲得したとされています。

MiroFishは、ニュース記事や政策草案などの現実世界の情報を入力すると、数千〜最大 100万のAIエージェント が仮想のSNS空間で議論・投稿・フォローを自律的に行い、世論の変化を予測するという 群体智能(Swarm Intelligence)予測エンジン です。
「そんなことが本当にできるのか?」
この記事では、 MiroFish の技術的な仕組みを徹底的に解剖し、実際にどこまで使えるのか、正直に検証していきます。
MiroFishとは?
MiroFish は、現実世界の情報から高忠実度のデジタル並行世界を構築し、AIエージェントたちに社会シミュレーションを行わせる予測エンジンです。

例えば「新しいAI規制法案」というニュース記事を入力すると、こんなことが起きます。
記事から登場人物・組織・概念を抽出してナレッジグラフを構築
「保守的な投資家」「テック起業家」「ジャーナリスト」など多様なペルソナを持つAIエージェントを数千体生成
仮想のTwitterとRedditで、エージェントたちが自律的に投稿・議論・フォロー
世論がどう動いたかのレポートを自動生成
気になるエージェントに「なぜ意見を変えたの?」と質問できる
MiroFishの公式ドキュメントには「確率推定ではなく、妥当なシナリオを生成するシステム」と明記されています。
5ステップのパイプライン
MiroFishは、入力から予測レポートの出力まで5つのステップで動作します。
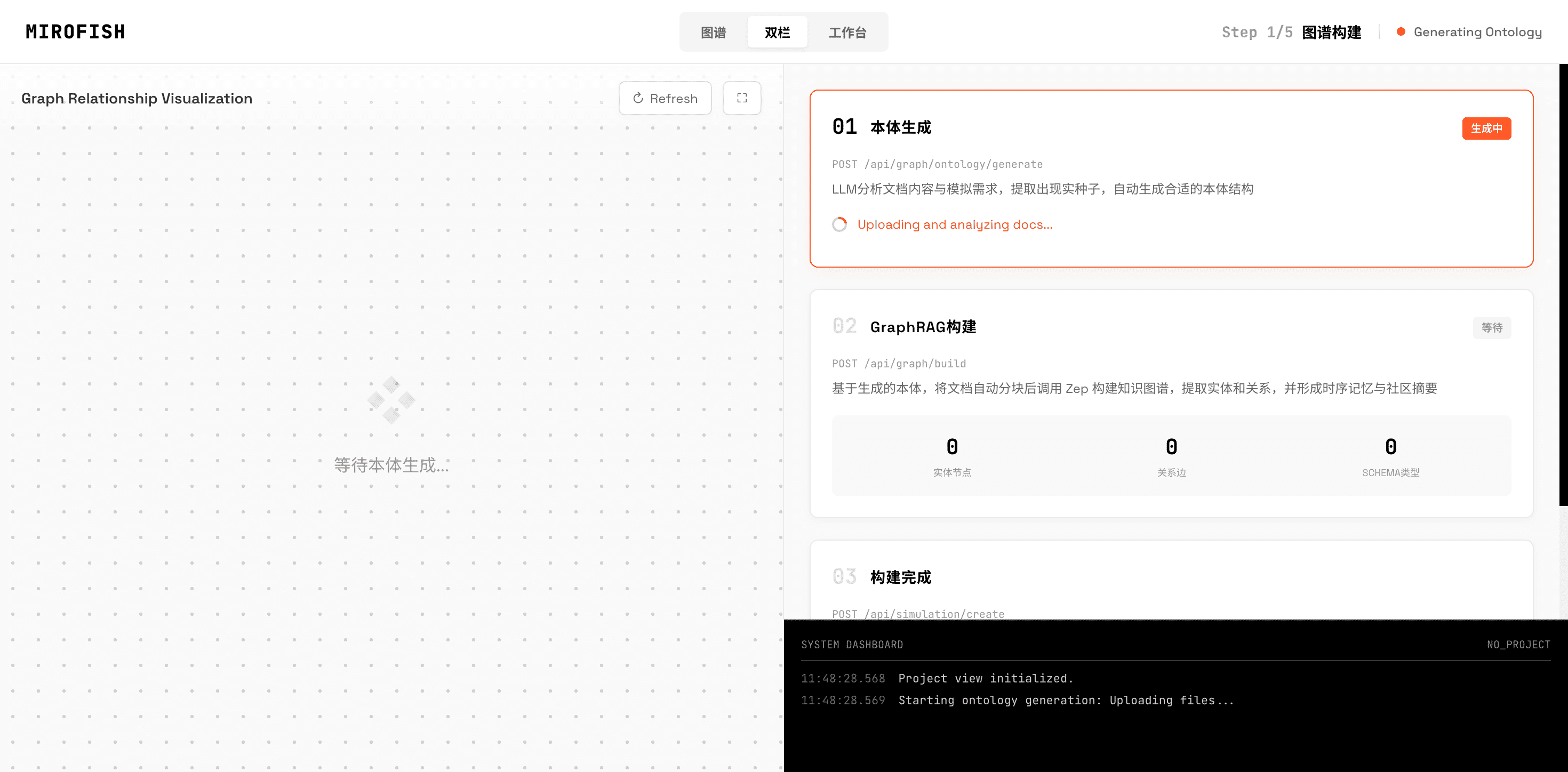
ステップ1:GraphRAGで知識グラフを構築する
最初のステップでは、入力テキスト(ニュース記事、金融レポートなど)から GraphRAG という技術で知識グラフを自動構築します。
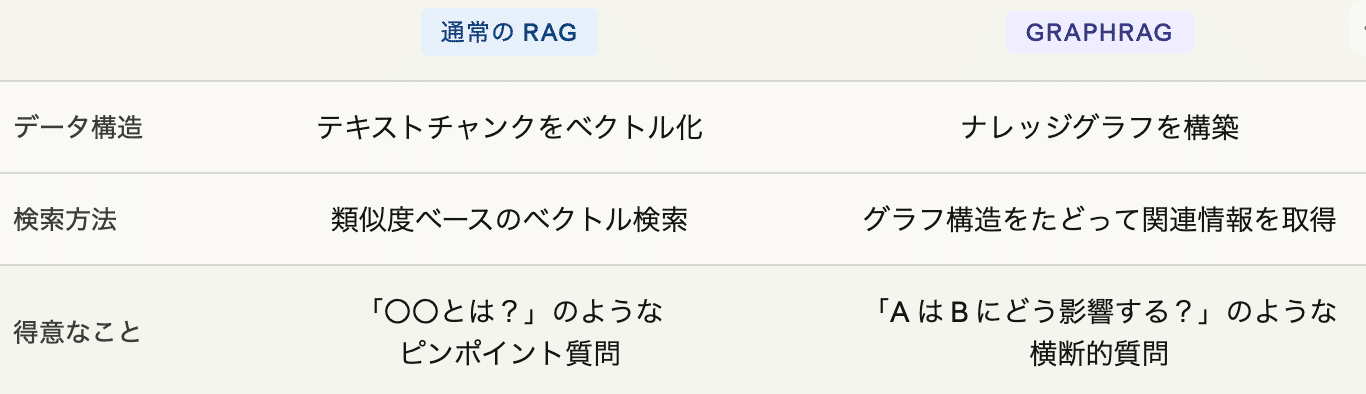
そもそもGraphRAGとは?
GraphRAGは、Microsoftが2024年2月に発表した技術です。通常のRAG(Retrieval-Augmented Generation)がテキストをチャンク(断片)に分割してベクトル検索するのに対し、GraphRAGはテキストからナレッジグラフ(エンティティと関係性の構造データ)を自動構築します。
GraphRAGなら、エンティティ間の関係をグラフとしてたどることで、この間接的なつながりを発見できます。MiroFishでは、入力テキストからこのナレッジグラフを自動構築し、シミュレーション世界の「土台」にしています。
ステップ2:エージェントに「個性」と「記憶」を与える
次に、ナレッジグラフの登場人物や概念をもとに、多様なAIエージェントを生成します。ポイントは3つの要素です。
固有の性格(ペルソナ):
例)
エージェントA: 60代、保守的な投資家、リスク回避傾向エージェント
B: 25歳、テック系スタートアップ起業家、楽観的エージェント
C: 40代、新聞記者、批判的思考、事実重視
Zep Cloudによる長期記憶: ここが技術的に最も重要な部分です。
なぜ「記憶」が必要なのか
LLMは本質的に ステートレス (状態を持たない)で、会話が終わると前回の内容を忘れてしまいます。しかしシミュレーションでは、エージェントが「3日前にAさんと議論して考えが変わった」ことを覚えている必要があります。
Zep Cloud は、この問題を解決する外部メモリサービスです。各エージェントの経験・意見変化を 時間軸付きのナレッジグラフ として記録します。
エージェントBの記憶(Zep Cloudに保存):
ラウンド3: AI規制に反対(イノベーション阻害を懸念)
ラウンド7: Aさんの安全性の指摘に一部納得 → 条件付き賛成に
ラウンド12: Cさんの海外事例で立場を微修正 → 規制範囲の限定を条件に賛成
これにより、100ラウンド以上のシミュレーションでも各エージェントが一貫した人格と記憶を持って行動し続けられます。
ステップ3:仮想SNSで並列シミュレーション
ここからがMiroFishの核心部分です。 OASIS (CAMEL-AIチーム開発)というオープンソースのSNSシミュレーターで、 Twitter風とReddit風の2つのプラットフォームを同時に稼働 させます。
なぜ「2つ」のプラットフォームなのか
Twitter風とReddit風では、情報の広がり方が根本的に異なるからです。
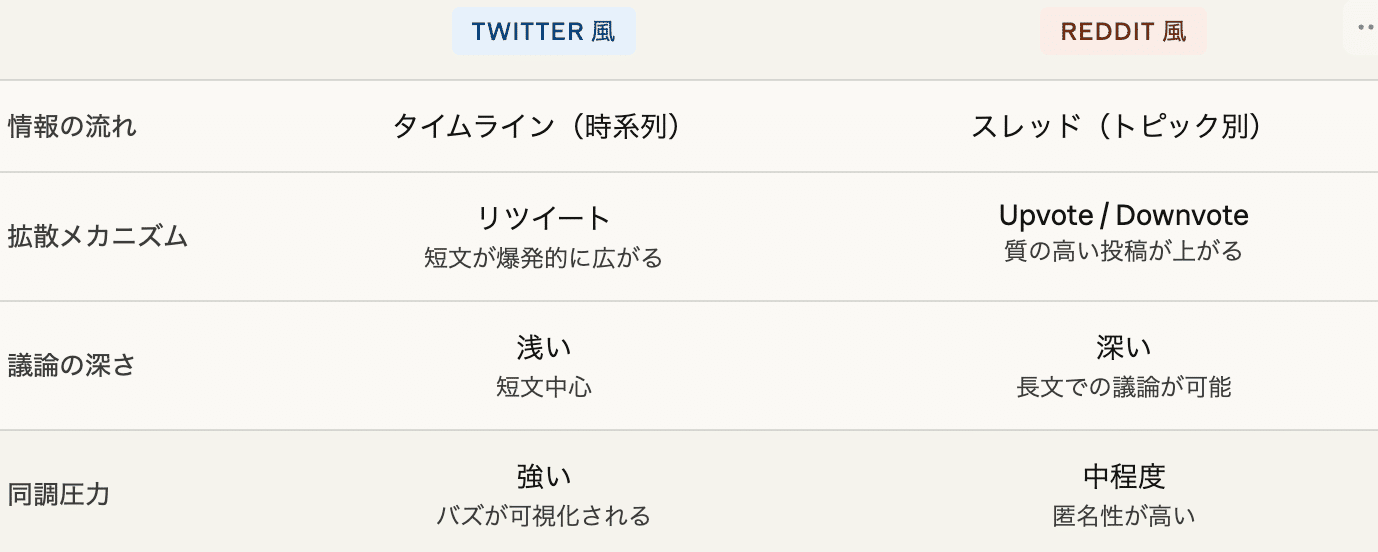
同じテーマでも、Twitter的な環境では 感情的・短絡的な意見が広がりやすく 、Reddit的な環境では 論理的な議論が深まりやすい 。両方を同時に走らせることで、多角的な予測が得られます。
エージェントができること
OASISでは、エージェントが 23種類のアクション を実行できます。投稿、リプライ、いいね、リツイート、Upvote/Downvote、フォロー、アンフォロー、ブロック、検索——通常のSNSで人がやることをほぼすべてシミュレートします。
ステップ4:ReportAgentが自動分析
シミュレーションが終わると、数千〜数万件の投稿・リプライ・フォロー関係の変化データが残ります。 ReportAgent がこれを3つの観点で自動分析します。
意見シフト: いつ、なぜ、どのくらい意見が動いたかを特定します。
提携形成: フォロー関係やリプライのパターンから、自然発生したグループとそのリーダーを検出します。
新興パターン: 入力データにはなかった、シミュレーション中に自然発生した新しい論点を検出します。これがMiroFishの「予測」の核心部分で、エージェントたちが自発的に生み出す予想外の展開を捉えます。
ステップ5:エージェントに質問し、シナリオを再実行
レポートを読んだ後、ユーザーは2つのことができます。
エージェントとの対話: 気になるエージェントに直接質問できます。
ユーザー → エージェント#142(法律家):
「なぜラウンド7で賛成に転じたのですか?」
エージェント#142:
「エージェント#089が共有したEUのAI Actの運用実績データを見て、 規制があっても技術革新は止まらないと判断しました」
実践:MiroFishを動かしてみよう
料金
MiroFish自体は無料のオープンソースですが、LLMのAPIを使用するため、そのコストが発生します。
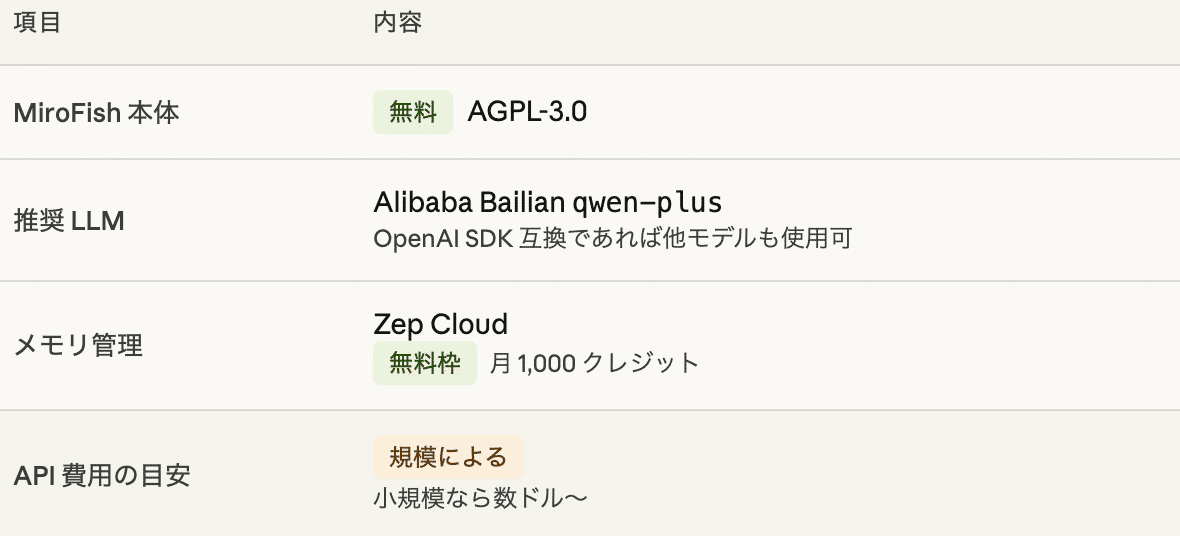
前提条件
Node.js 18以上
Python 3.11〜3.12
uv(Pythonパッケージマネージャ)
OpenAI SDK互換のAPIキー
Zep CloudのAPIキー
セットアップ手順
以下のようにClaude Codeに全部丸投げできますが、詳細解説も載せておきます。


詳細解説
1. リポジトリのクローンと環境設定
git clone https://github.com/666ghj/MiroFish.git cd MiroFish cp .env.example .env
2. APIキーの設定
`.env`ファイルを開き、LLMのAPIキーとZep CloudのAPIキーを設定します。
LLM_API_KEY=your_api_key_here ZEP_API_KEY=your_zep_api_key_here
3. 依存関係のインストールと起動
npm run setup:all npm run dev
フロントエンドは `http://localhost:3000`、バックエンドは `http://localhost:5001` で起動します。
Dockerを使う場合:
docker compose up -d
実際に使ってみます
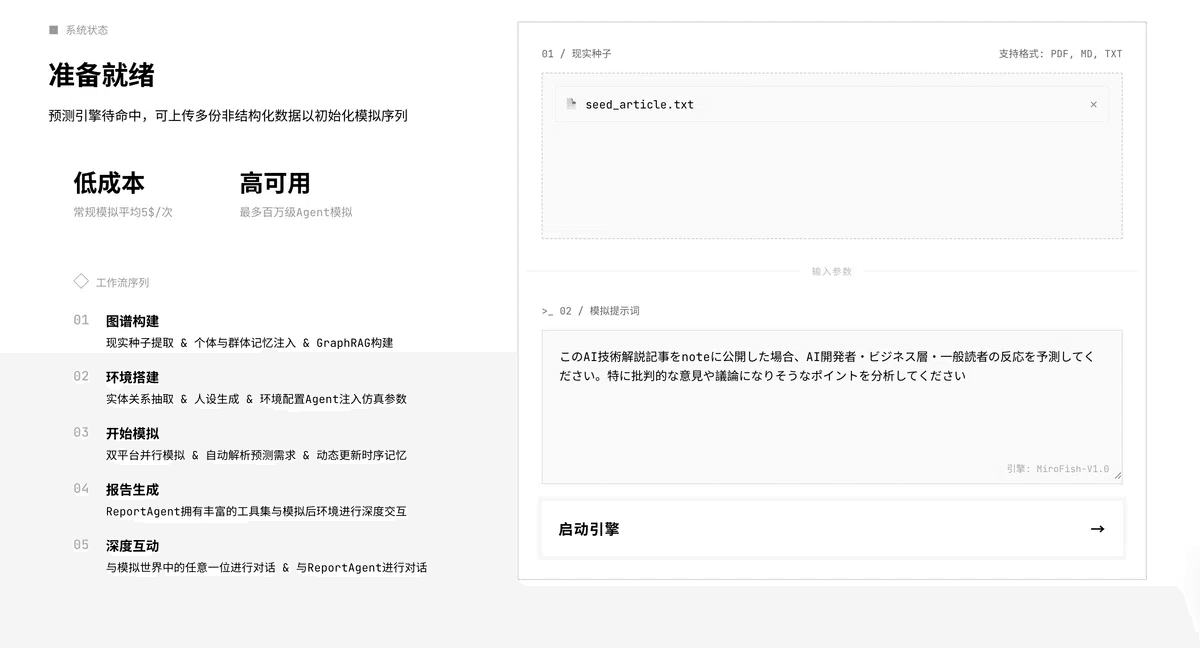
予測したいテーマに関するテキスト(ニュース記事など)を入力
使ってみる
ブラウザで `http://localhost:3000` にアクセス
予測したいテーマに関するテキスト(ニュース記事など)を入力
エージェント数やシミュレーションラウンド数を設定(初回は40ラウンド以下を推奨)
シミュレーションを実行
生成されたレポートを確認し、必要に応じてエージェントと対話





