

Google I/O の季節がやってきた!
日本時間5月21日深夜2時より、Googleの開発者向けイベントが開催されました。
Geminiを中心に、衝撃的な発表が相次ぎました。
本記事では、初日に行われたKeynoteの発表内容をすべてまとめています!
主要な発表内容
イベントは、最新の動画生成モデル 「Veo 3」によるものと思われる圧巻の映像でスタート。

Pichai CEO基調講演:AIファーストの未来を加速
はじめに登壇したのは、Google CEOのSundar Pichai氏。
Pichai氏は、これまでのAI開発の進捗と、Gemini時代における製品リリースの加速について触れ、AIがGoogleの核であることを強調しました。

新サービス・新機能
Google Beam
Googleは、以前「Project Starline」として発表されていた3Dビデオコミュニケーション技術を、新たに「Google Beam」として正式に発表しました。これは、AIを活用した新しいビデオコミュニケーションプラットフォームです。
Google Beamは、複数のカメラ(デモでは6台使用)で捉えた映像をAIがリアルタイムで処理し、専用の3Dライトフィールドディスプレイに立体的な映像として表示します。これにより、遠隔地にいる相手とも、まるで同じ部屋にいるかのような自然で没入感のあるコミュニケーション体験を目指しています。

このGoogle Beamデバイスは、HPとの協業により、2025年後半に早期顧客向けに提供が開始される予定です。詳細については、数週間以内にHPから発表があるとのことです。
Google Meet リアルタイム音声翻訳
Google Meetに、リアルタイムでの音声翻訳機能が導入されることが発表されました。この機能は、会話の遅延を最小限に抑えつつ、異なる言語を話す人同士のコミュニケーションをサポートしてくれます。

特徴として、単に言葉を翻訳するだけでなく、話者の声のトーンや話し方のパターン、さらには表情までも再現しようと試みており、より自然でスムーズな会話体験を目指しています。
このリアルタイム音声翻訳機能は、まず英語とスペイン語の翻訳がGoogle Meetのサブスクライバー向けに本日から提供開始されます。今後数週間で対応言語はさらに拡大される予定です。また、企業向けのエンタープライズ版については、2025年後半の提供開始を予定しています。


Gemini Live (Project Astra)
GoogleのAIアシスタントの将来像を探る研究プロジェクト「Project Astra」で開発された機能が、「Gemini Live」に統合され、提供が開始されることが発表されました。
https://twitter.com/ctgptlb/status/1924883964994756632
Gemini Liveは、スマートフォンのカメラや画面共有機能を通じて、ユーザーが見ているものや表示している内容をAIがリアルタイムで理解し、それについて対話することを可能にします。
これにより、例えば目の前にある物について質問したり、画面に表示された情報について説明を求めたりといった、よりインタラクティブな利用が期待されます。
この新しいGemini Liveの機能は、本日よりAndroidおよびiOSのGeminiアプリを通じて、45以上の言語、150以上の国で無料提供が開始されます。
また、今後数週間以内には、Googleカレンダー、Googleマップ、Google Keep、Google Tasksといった他のGoogleアプリとの連携機能も追加される予定です。


Agent Mode (Project Mariner)
Googleは、ウェブサイトと対話し、ユーザーに代わってタスクを実行できるAIエージェント技術「Project Mariner」の進化形として、「Agent Mode」を発表しました。

Agent Modeは、高度なAIモデルの知能とツールへのアクセスを組み合わせることで、ユーザーの指示に基づき、自律的に行動を起こすシステムです。
発表された主な機能としては、最大10個のタスクを同時に処理できる「マルチタスク機能」や、一度ユーザーがタスクの実行方法を示すと、AIがその手順を学習し、類似のタスクに応用できる「Teach and Repeat機能」があります。

このAgent Modeの基盤となるコンピュータ利用機能は、本日よりGemini APIを通じて開発者に提供が開始されており、Automation AnywhereやUI Pathといった企業が既に利用を開始しています。より広範囲な提供は、2025年の夏を予定しています。
https://twitter.com/ctgptlb/status/1924886408222982202
また、エージェント同士が連携するための「Agent-to-Agentプロトコル」(既に60以上のテクノロジーパートナーがサポート)や、Anthropic社が提唱する「Model Context Protocol(MCP)」との互換性も発表され、エージェントエコシステムの構築に向けた取り組みが示されました。


このAgent Modeの実験的なバージョンが、Geminiアプリのサブスクライバー向けに提供される予定です。デモでは、複雑な条件を指定してアパートを探すといったタスクをAgent Modeが代行する様子が紹介されました。


Gmail パーソナライズドSmart Reply
Gmailに、AIがユーザーの文体や過去のやり取りを学習し、より自然でその人らしい返信文案を提案する「パーソナライズドSmart Reply」機能が導入されることが発表されました。
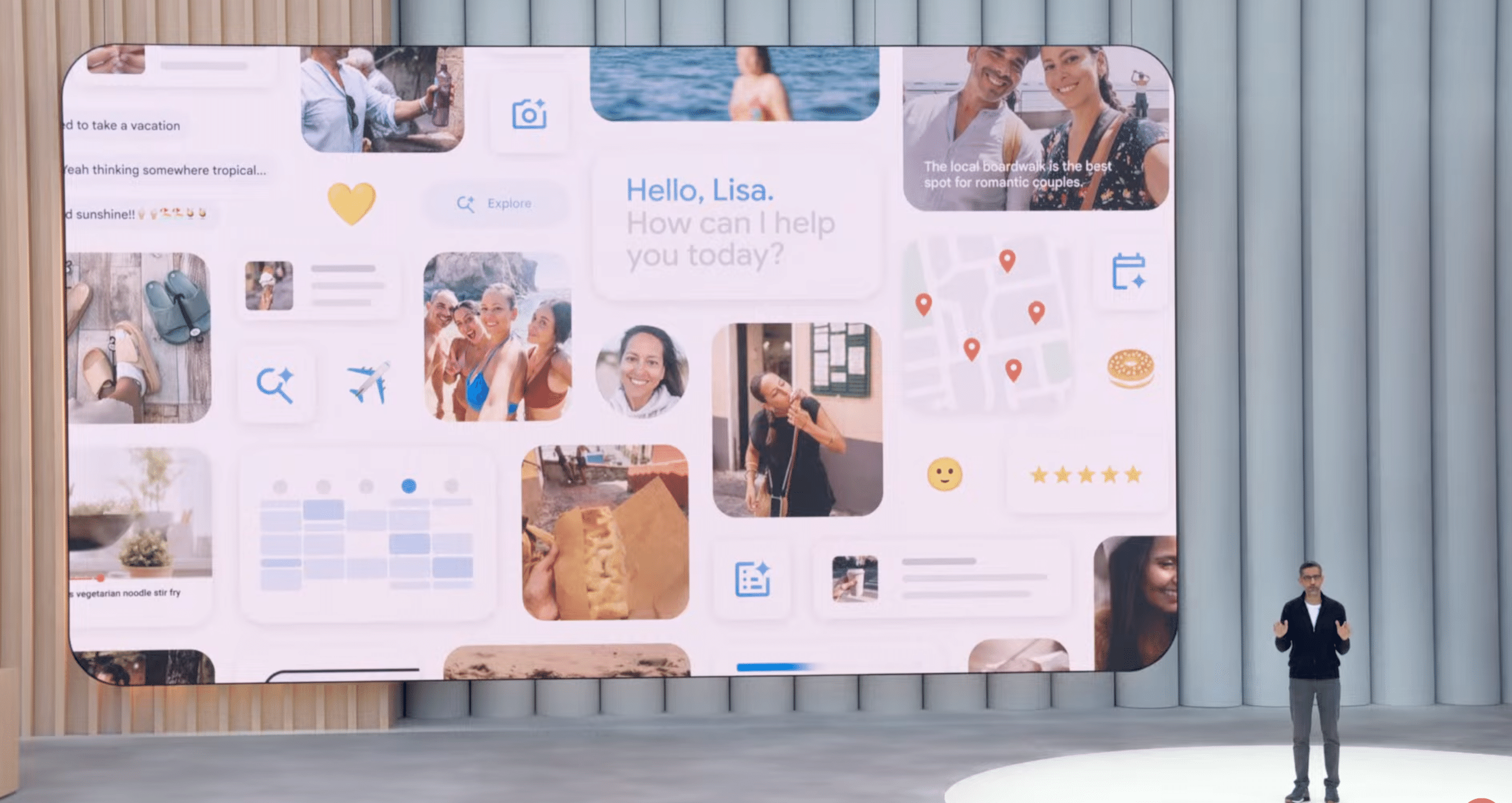

この機能は、ユーザーが許可した場合に、Gmail内の過去のメールだけでなく、Google DriveのメモやGoogle Docsの旅程といった関連情報を参照します。それらの情報から、ユーザー特有の挨拶の仕方、トーン、スタイル、頻繁に使う単語などを把握し、受信したメールに対して、まるでユーザー自身が書いたかのような返信文案を自動で生成します。

例えば、友人から過去の旅行についてアドバイスを求めるメールが来た場合、パーソナライズドSmart Replyは、ユーザーの過去の旅行計画やメモを基に、具体的な情報を盛り込んだ丁寧な返信文案を作成することができます。
これにより、ユーザーは返信作成の手間を大幅に削減しつつ、より人間味のあるコミュニケーションを維持できるようになります。
このパーソナライズドSmart Reply機能は、2025年の夏にGmailのサブスクライバー向けに提供が開始される予定です。

Geminiモデルの詳細とAPIの進化
ここで Google DeepMind Co-Founder Demis Hassabis にバトンタッチ!

まず2週間前にアップデートが発表されたGemini 2.5 Proが改めて紹介されました。Gemini 2.5 ProはGoogle史上最もインテリジェントなモデルであり、現時点で世界最高の基盤モデルとして紹介されました。
手描きのスケッチからインタラクティブなアプリケーションを生成したり、都市全体の3Dシミュレーションを構築したりといった活用事例が紹介されました。
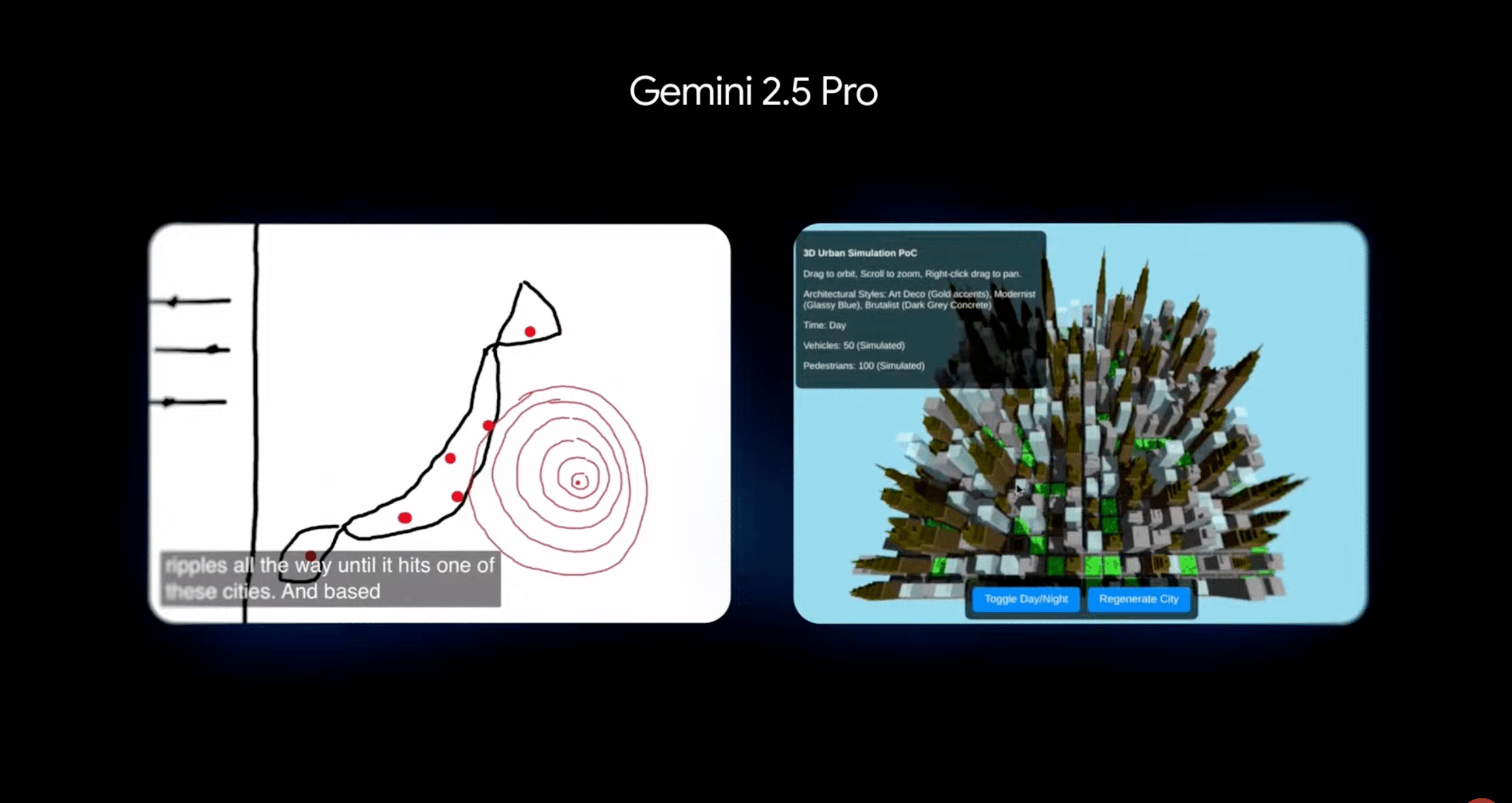
具体的な成果として、Gemini 2.5 Proは、AIモデルの性能を評価する主要なリーダーボードの一つであるLMArenaにおいて、全てのカテゴリで1位を獲得しています。また、コーディング能力においても、WebDev arenaでトップの成績を収めており、これは前バージョンから142 Eloポイント向上した結果です。主要なAIコードエディタであるCursor上では、Geminiは今年最も急速に成長しているモデルであり、毎分数十万行のコード追加が受け入れられています。
さらに、教育分野の専門家と共同で構築されたモデルファミリー「LearnLM」を統合したことにより、Gemini 2.5 Proは学習分野においても主要なモデルとなったと紹介されました。

このアップデートされたGemini 2.5 Proは、AI Studio、Vertex AI、およびGeminiアプリでプレビュー版が利用可能となっています。
Gemini 2.5 Flash アップデート
次に、Geminiファミリーの中で最も効率的な主力モデルとして「Gemini 2.5 Flash」のアップデートが発表されました。
このモデルは、その速度と低コストから開発者に非常に人気があるとしています。

今回のアップデートにより、Gemini 2.5 Flashは推論、コーディング、長文脈処理といった主要なベンチマークにおいて、ほぼ全ての側面で性能が向上しました。LMArenaリーダーボードでは、Gemini 2.5 Proに次ぐ第2位の評価を得ています。
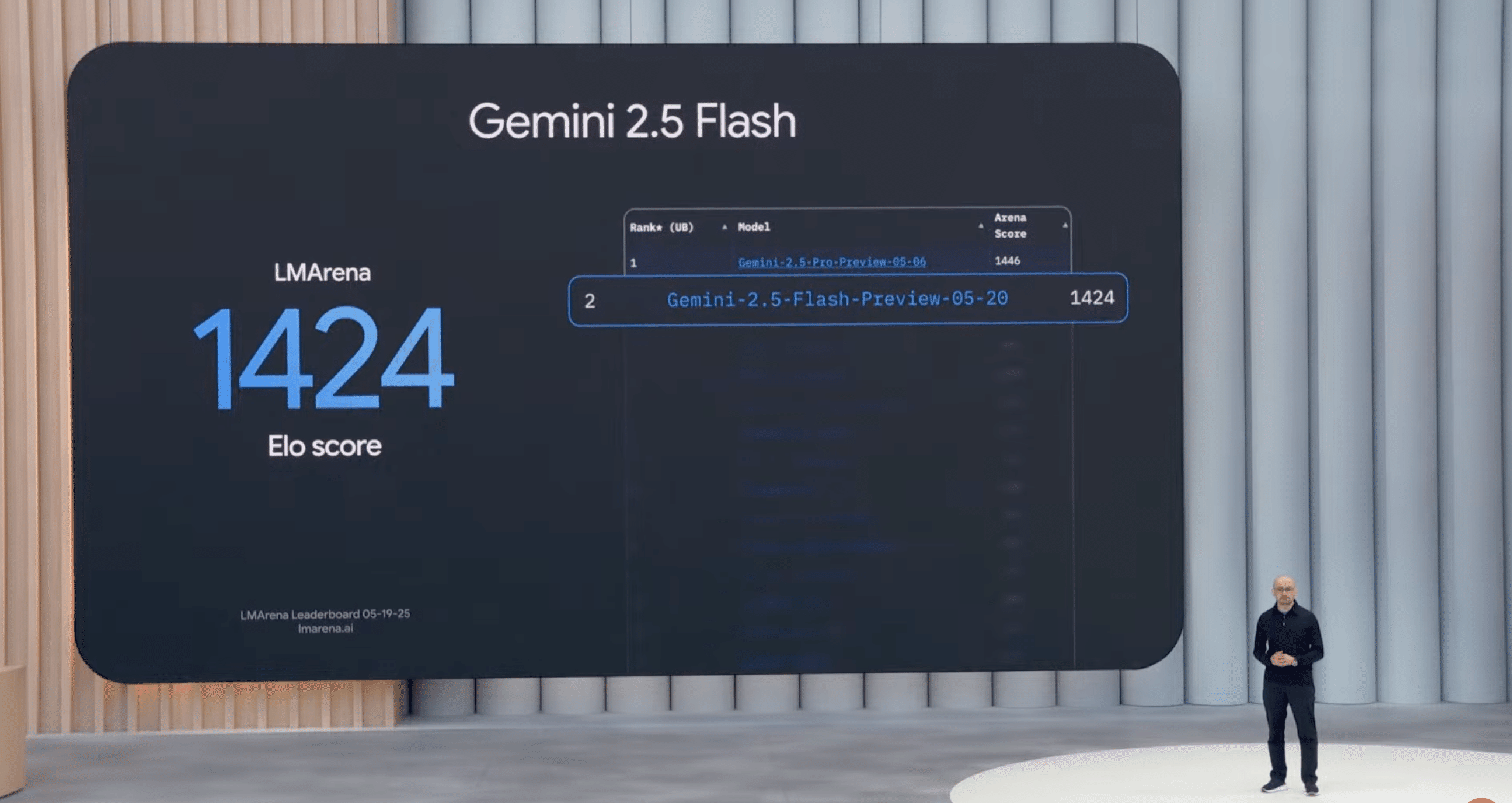
特筆すべき点として、新しいGemini 2.5 Flashは効率性がさらに向上しており、同等のパフォーマンスを発揮するために必要なトークン数を22%削減することに成功しています。
また、ユーザーがコスト、遅延、そして応答品質のバランスを細かく制御できる「Thinking Budgets」機能も引き続き提供されます。 このアップデートされたGemini 2.5 Flashは、2025年6月上旬に一般提供が開始される予定です。現在、AI Studio、Vertex AI、およびGeminiアプリでプレビュー版が利用可能となっています。

Gemini 2.5 APIの強化
Google DeepMindのTulsee Doshi氏より、開発者からのフィードバックに基づき、Gemini 2.5のAPIに関して、機能性、セキュリティ、透明性、コスト効率、そして制御性の向上が図られた複数のアップデートが発表されました。
一つずつみていきます。
Text-to-Speech マルチスピーカー対応
Gemini 2.5 APIの新機能として、Text-to-Speech(テキスト読み上げ)機能において、業界初となる2つの異なる声(マルチスピーカー)をネイティブ音声出力でサポートすることが発表されました。
これにより、モデルはより表現力豊かに会話することが可能になり、人間が話す際の微妙なニュアンスを捉えることができます。
例えば、デモでは通常の会話からささやき声へとシームレスに切り替えるといった表現が披露されてました。この機能は24以上の言語に対応しており、会話の途中で同じ声のまま異なる言語へスムーズに切り替えることもできます。

Thought Summaries
モデルがどのように結論に至ったかの透明性を高めるため、「Thought Summaries」機能がGemini APIおよびVertex AIに導入されます。
この機能は、モデルの内部的な思考プロセスを、ヘッダー、主要な詳細、そしてツール呼び出しといったモデルのアクションに関する情報を含んだ、分かりやすい形式に整理して表示します。これにより、特に処理に時間がかかるタスクにおいて、モデルが何を考えているのかを把握しやすくなり、デバッグも容易になります。

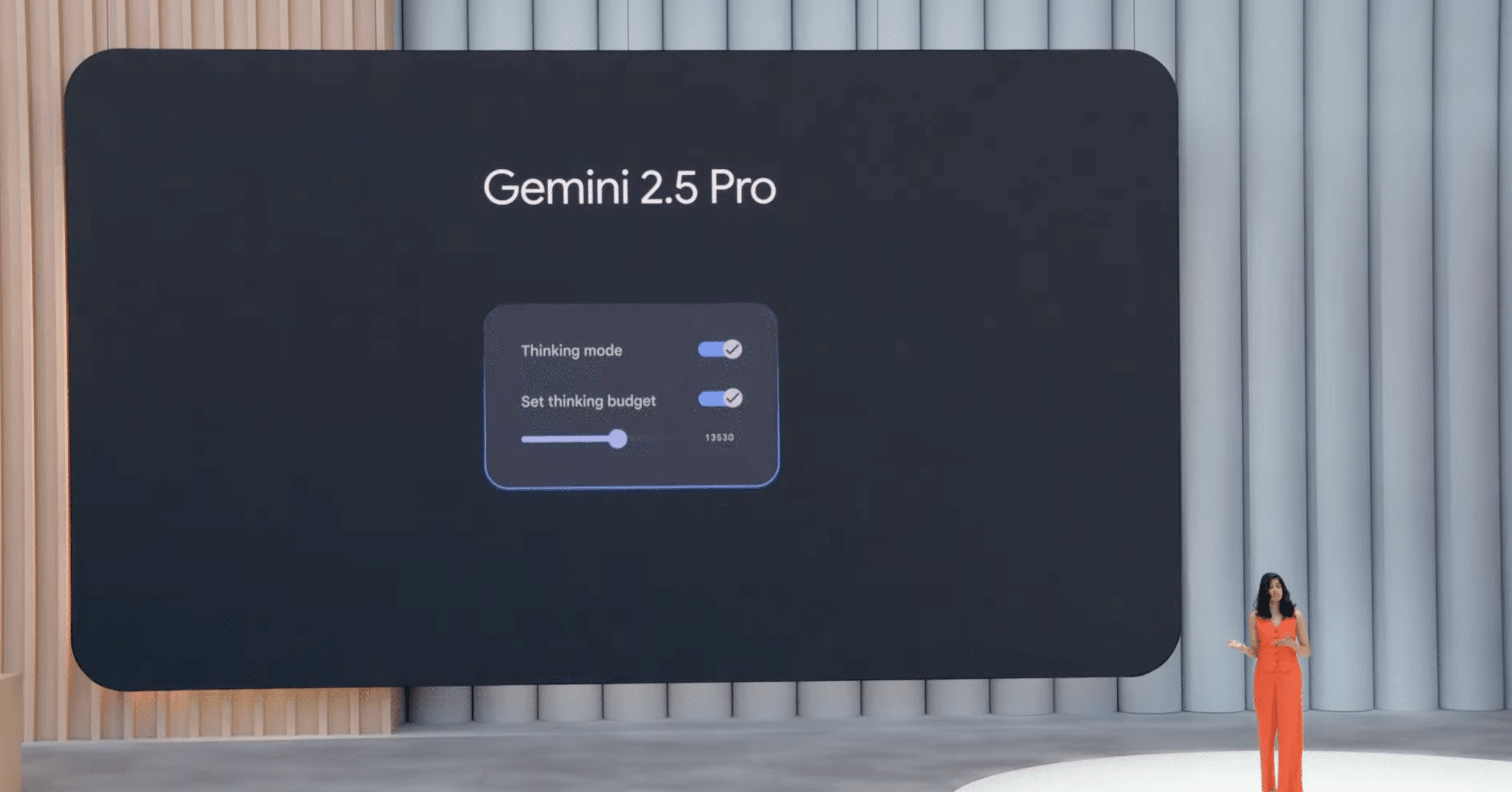
Thinking Budgets
開発者がモデルのコストと応答速度、そして品質のバランスをより柔軟に制御できるようにするため、「Thinking Budgets」機能がGemini 2.5 Proにも導入されます。この機能は既にGemini 2.5 Flashで提供され、好評を得ています。
Thinking Budgetsを利用することで、モデルが応答を生成する前に思考に使用するトークン数を調整したり、この機能を完全にオフにしたりすることが可能です。この機能は、Gemini 2.5 Proの一般提供(今後数週間以内)と同時にロールアウトされる予定です。

コーディングエージェント「Jules」
Gemini 2.5 Proの高度なコーディング能力を活用した、新しい非同期型コーディングエージェント「Jules」が発表され、パブリックベータ版の提供が開始されました。
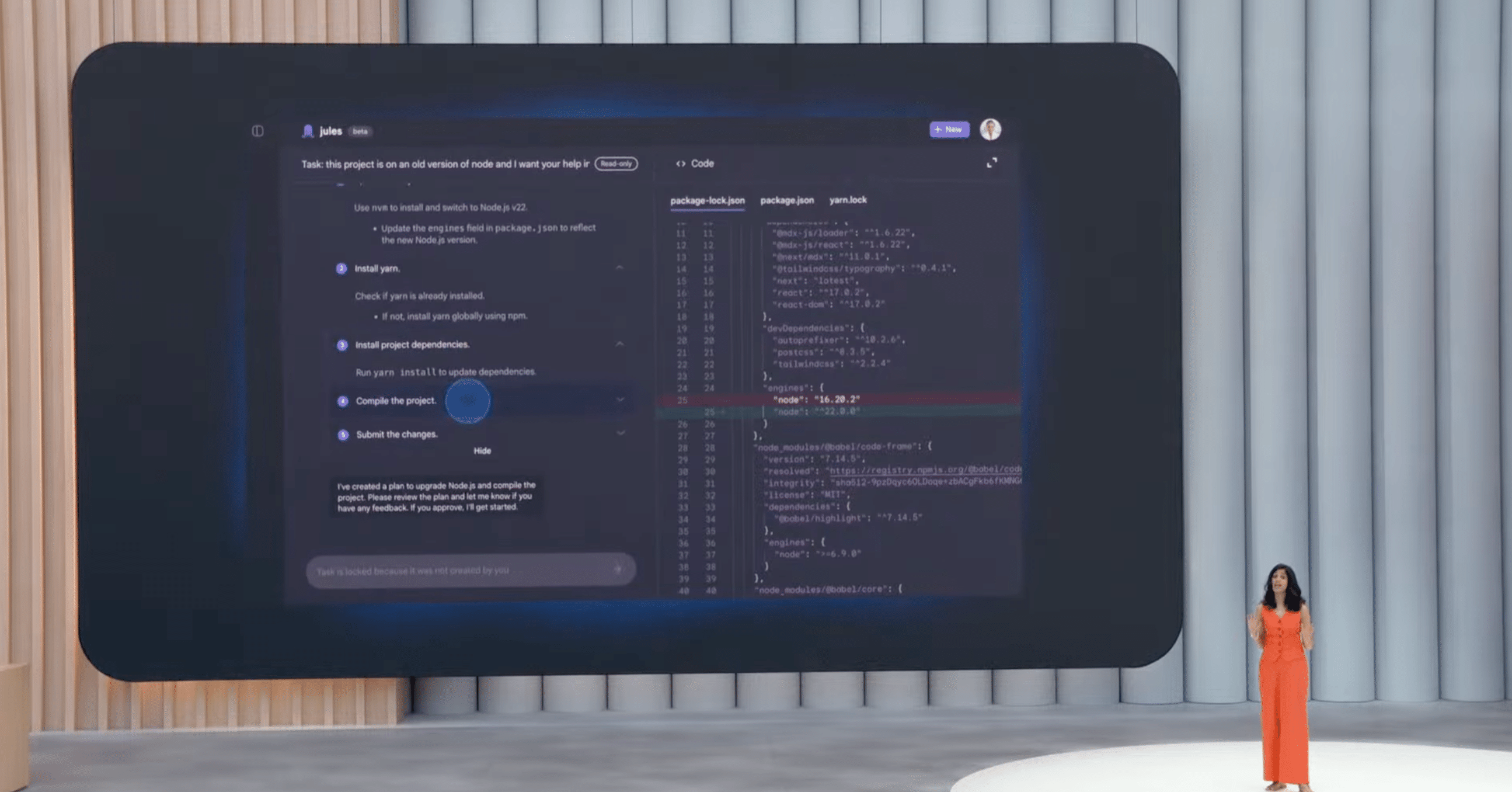
Julesは、バグ修正や機能アップデートといったタスクを指示するだけで、残りの作業(計画立案、ファイル修正など)を自律的に実行します。GitHubとの連携も可能で、従来は数時間かかっていたような大規模なコードベースでの複雑なタスク(例:古いNode.jsのバージョンアップ)も数分で処理できるとされています。関心のある開発者は、jules.google からサインアップできます。
https://twitter.com/ctgptlb/status/1924882165478916182
Gemini Diffusion
テキスト生成の分野において、拡散モデルの技術を応用した新しい実験的なモデル「Gemini Diffusion」が発表されました。

このモデルは、ノイズから段階的に出力を洗練させる拡散プロセスをテキスト生成に適用することで、特に編集タスク(数学やコードの文脈を含む)で優れた性能を発揮します。左から右へと一方的に生成するのではなく、生成プロセス中に迅速に反復処理を行い、エラー訂正が可能です。
本日発表されたバージョンのGemini Diffusionは、Googleの最速モデルである2.0 Flash Liteと比較して5倍高速にテキストを生成しつつ、同等のコーディング性能を維持しているとのことです。デモでは、数学の問題を瞬時に解く様子が披露されました。このモデルは現在、少人数のグループでテスト中です。
https://twitter.com/ctgptlb/status/1924885263618371972
Gemini 2.5 Pro DeepThinkモード
次に、Gemini 2.5 Proの性能をさらに引き出すための新しいモード「DeepThink」が発表されました。

DeepThinkモードは、モデルに思考のためのより多くの時間を与えることで応答の質を向上させるというAlphaGoなどでの知見に基づき、思考と推論に関するGoogleの最新かつ最先端の研究(並列処理技術などを含む)を活用しています。これにより、モデルのパフォーマンスを限界まで高め、画期的な結果をもたらすことを目指しています。
実際に、DeepThinkモードを適用したGemini 2.5 Proは、非常に難易度の高い数学ベンチマークであるUSAMO 2025で優れたスコアを達成したほか、競技プログラミングレベルのコーディング能力を測るLiveCodeBenchにおいてもトップの成績を収めています。また、Geminiが元来持つネイティブなマルチモーダル能力により、主要なマルチモーダルベンチマークであるMM-MUでも卓越した結果を示しています。
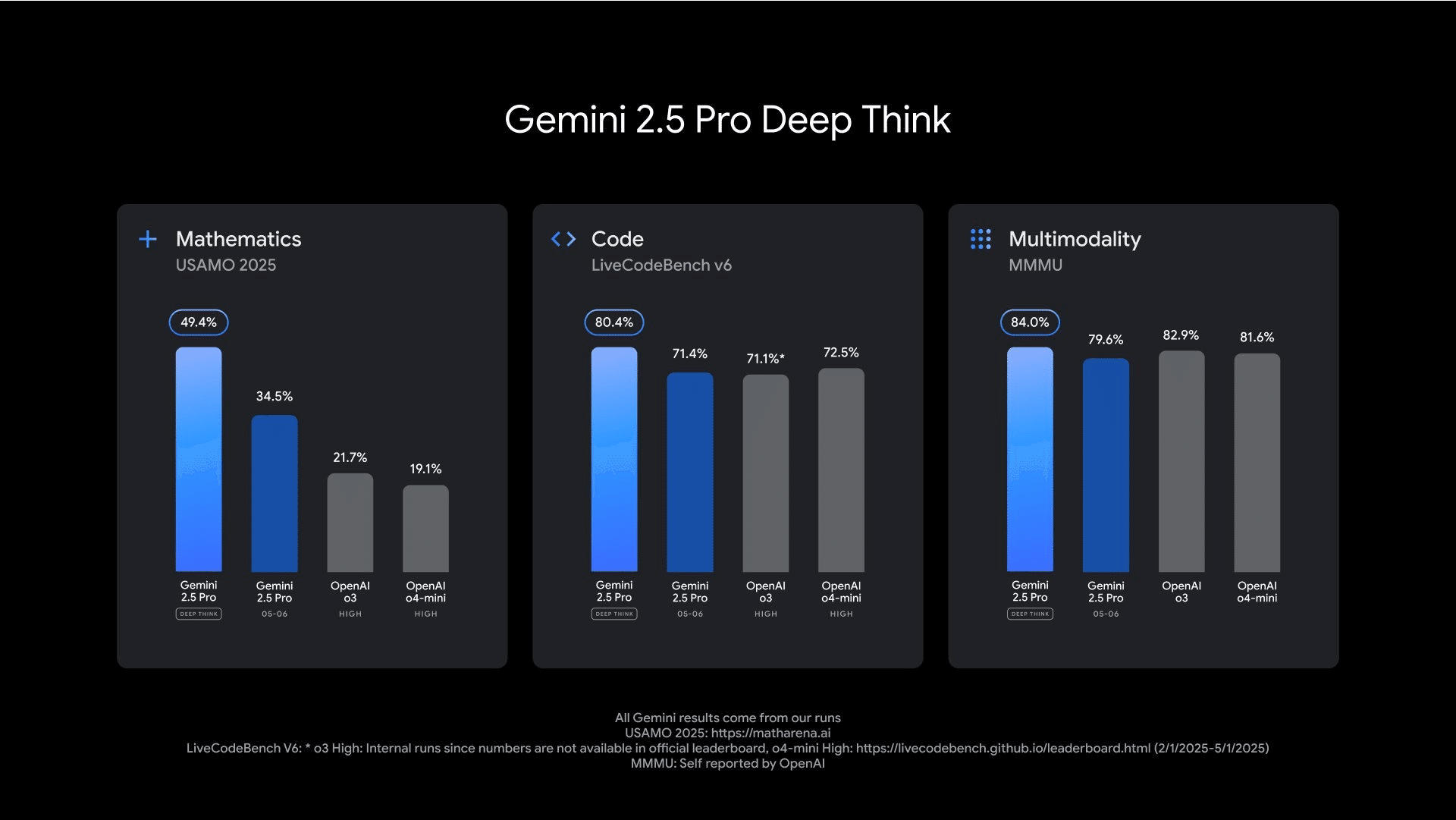
まずは信頼できるテスターに対してGemini API経由で提供され、広範な提供の前にフィードバックが収集される予定です。Google AI Ultraサブスクリプションプランの加入者は、準備が整い次第、GeminiアプリでこのDeepThinkモードにアクセスできるようになる見込みです。

World Model (Geminiの進化構想)
Google DeepMindのDemis Hassabis氏は、Geminiを単なるマルチモーダルモデルから、現実世界の側面をシミュレートすることで計画を立てたり、新しい体験を想像したりできる「World Model(ワールドモデル)」へと進化させるという長期的なビジョンを示しました。これは、人間の脳が世界を理解し予測する能力に近づくことを目指すものです。
この構想に関連する具体的な技術として、以下のものが挙げられました。
Genie 2: 単一の画像プロンプトから、ユーザーがインタラクション可能な3Dの仮想環境を生成できるモデル。

Veo: 最新の動画生成モデルであり、重力、光、物質の挙動といった直感的な物理法則を深く理解し、フレーム間の正確性と一貫性を保ちながら、創造的なプロンプトにも対応できる能力を持っています。

Gemini Robotics: ロボットが人間の指示を理解し、物を掴んだり、新しいタスクにその場で適応したりといった、実世界で役立つ行動を学習させるためにファインチューンされた専用モデル。

Universal AI Assistant (Geminiアプリの進化構想)
Googleは、Geminiアプリを、日常のタスクを実行し、ユーザーの状況を理解し、あらゆるデバイスでユーザーに代わって計画・行動できる「Universal AI Assistant(ユニバーサルAIアシスタント)」へと進化させるという究極のビジョンを掲げました。これは、AGIへの道における重要なマイルストーンの一つと位置付けられています。

このビジョンは、昨年発表された「Project Astra」で探求されてきた、ビデオ理解、画面共有、記憶といった能力を基盤として、これらの機能は既にGemini Liveに統合され始めており、さらに音声出力の自然化、記憶機能の向上、コンピュータ制御機能の追加といった進化が続けられています。
Google Searchの革新
次に Sundar Pichaiから、AIの進化がGoogle検索をどのように変革するのか、その具体的な姿が示されました。

AI Overviewsの進化
昨年導入された「AI Overviews」は、現在、月間15億人以上のユーザーに200以上の国と地域で利用されており、Google検索における最も成功したローンチの一つとされています。AI Overviewsが表示される種類のクエリは10%以上増加しており、特にビジュアル検索(Google Lens)の成長を65%(前年比)も牽引しています。
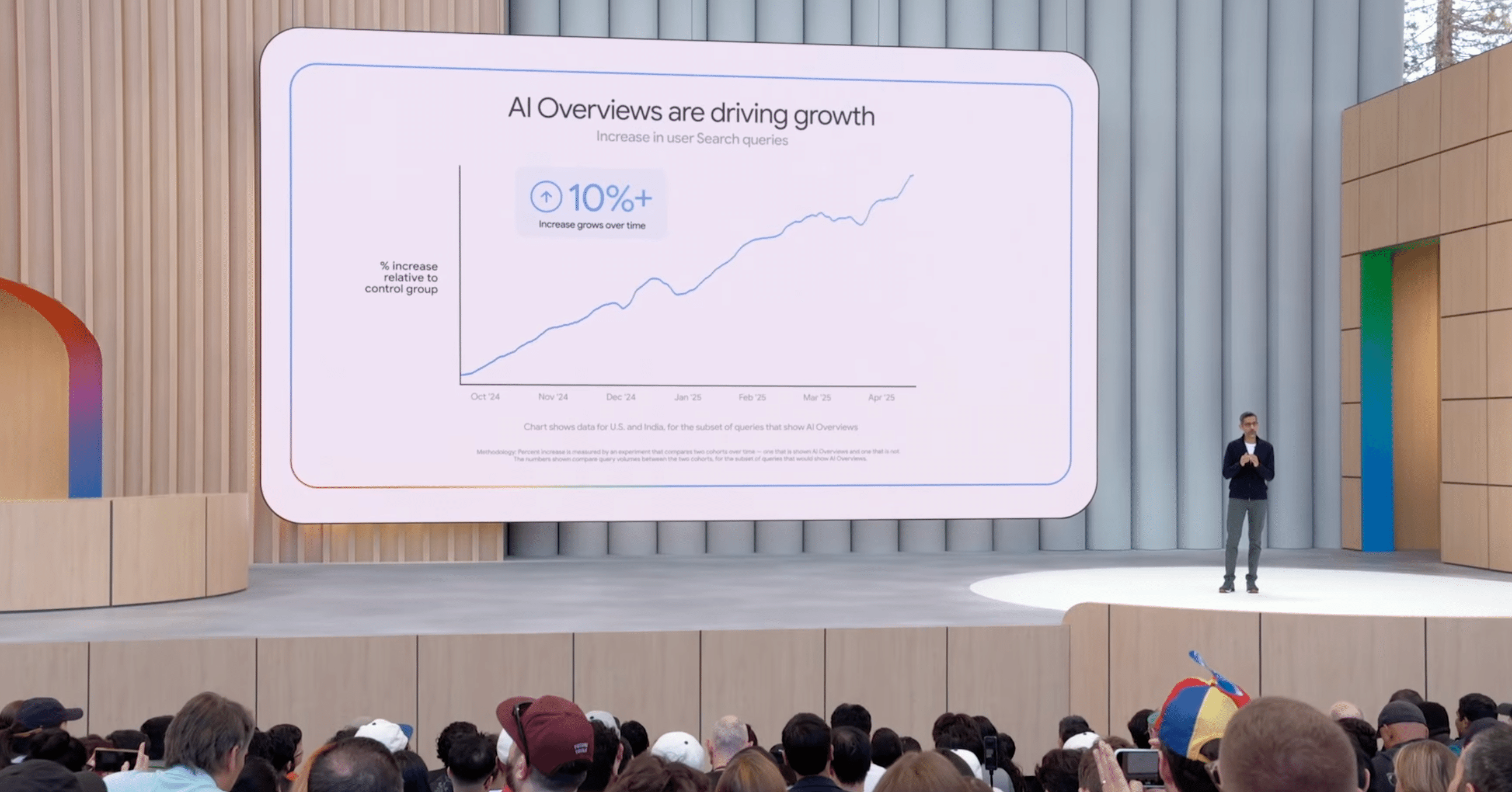
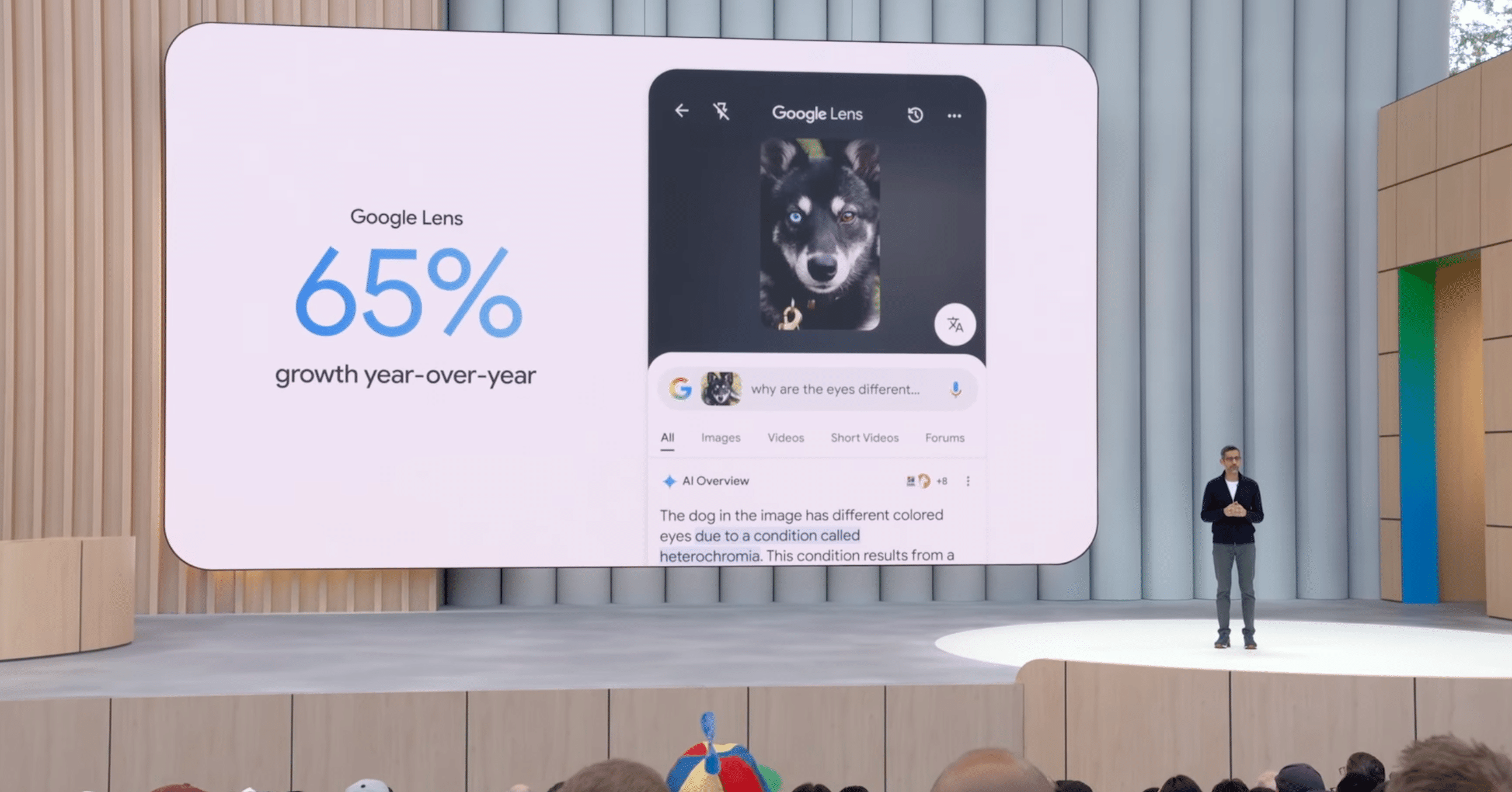
ユーザーはより複雑な質問をする傾向にあり、最新のGeminiモデルにより、AI Overviewsは業界最高水準の品質、精度、速度を実現していると述べられました。
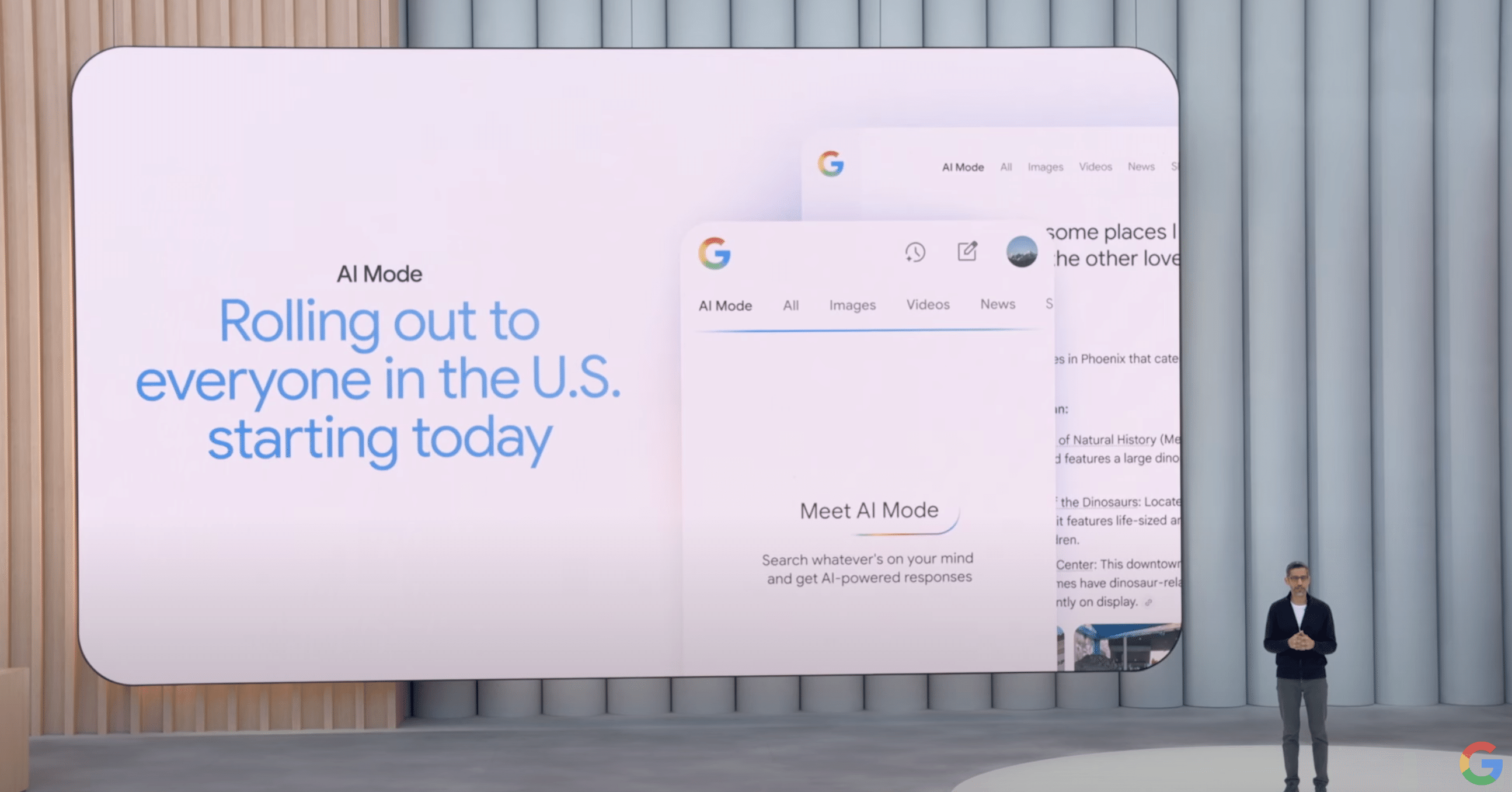
新機能「AI Mode」
Google検索の次なる大きなステップとして、全く新しいAI検索体験を提供する「AI Mode」が発表されました。米国の全ユーザーに対し、本日より提供が開始されます。
これは、検索結果ページに新しいタブとして表示され、Gemini 2.5を中核に据えた、より高度な推論能力を持つ検索機能です。
Query fan-out技術: 複雑な質問をAIが複数のサブトピックに分解し、ウェブ全体、ナレッジグラフ、ショッピンググラフ、ローカル情報などを横断的かつ同時に検索・統合して、包括的な回答を生成します。
パーソナルコンテキスト: ユーザーの許可に基づき、過去の検索履歴やGmailなどのGoogleアプリ情報を活用し、よりパーソナライズされた検索結果や提案を行います。この機能は今夏、AI Modeに導入予定です。

Deep Search: より詳細な調査が必要な質問に対し、AIが数十から数百の検索を代行し、専門家レベルの網羅的なレポート(引用付き)を数分で作成します。Labsを通じて近日提供開始予定です。

複雑なデータ分析と可視化: スポーツの統計データや金融関連の質問に対し、AIが自動的に表やグラフを生成して分かりやすく提示します。この機能は今夏より、スポーツと金融に関する質問に対応します。
エージェント機能: Project Marinerの技術を活用し、イベントチケットの検索・比較、レストランの予約、ローカルサービスの予約といったタスクをAI Mode内で実行できるようになります。近日提供開始予定です。
Search Live: Project Astraのリアルタイム認識技術をAI Modeに統合。スマートフォンのカメラを通して現実世界をAIに見せながら、対話形式で情報を得たり、質問したりすることが可能になります。
ショッピング機能の強化:
AI Mode内で、ユーザーの好みや入力した情報に基づいて、500億以上の商品リストから視覚的に魅力的な商品提案を行います。
バーチャルトライオン機能「Try On」: ユーザーがアップロードした自身の写真に、AIが衣料品をリアルに仮想試着させることができます。AI Labsで本日より利用可能です。
https://twitter.com/ctgptlb/status/1924891171480076338
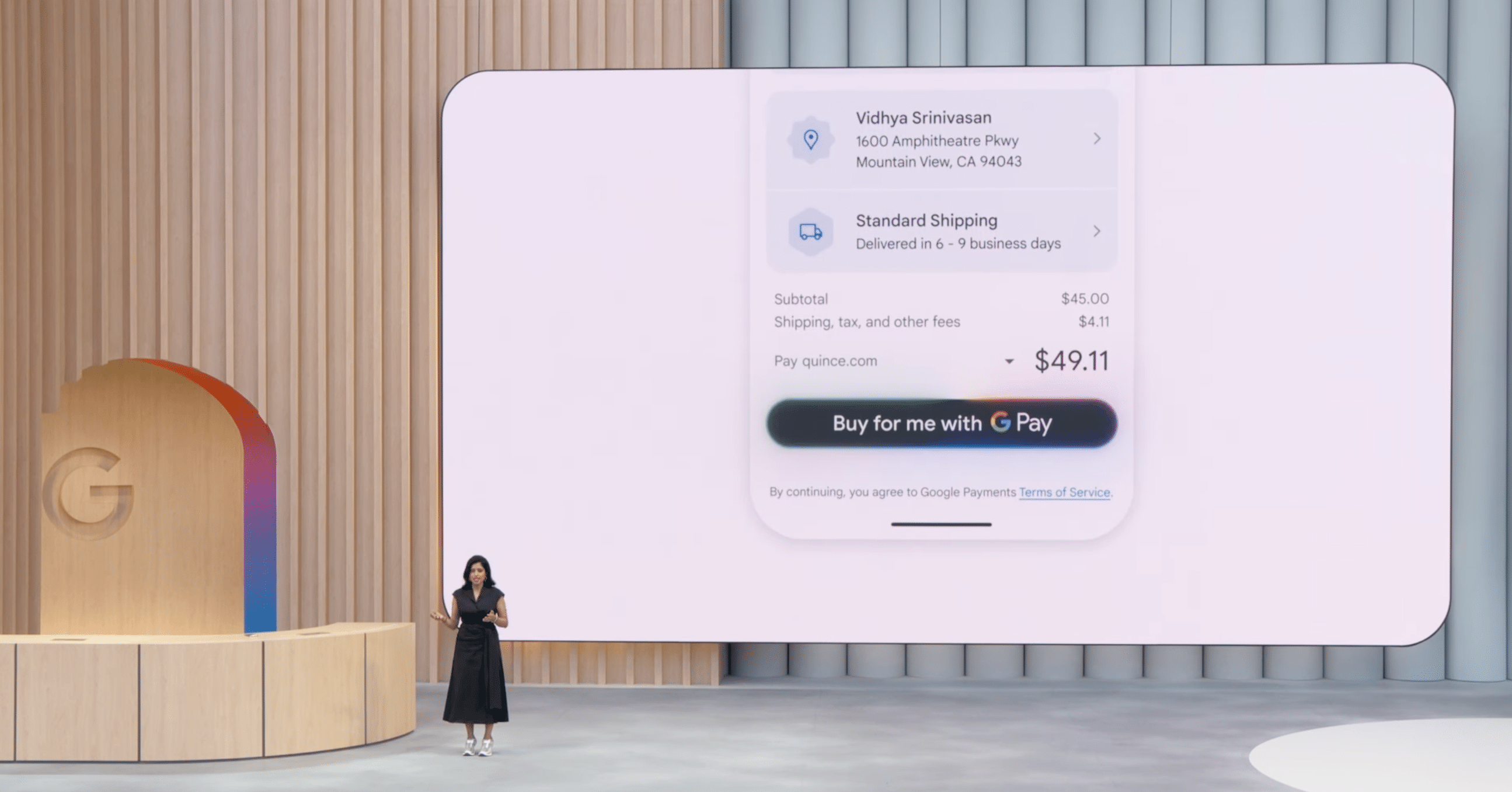
エージェントによる価格追跡・購入機能: 気になる商品の価格変動をAIが追跡し、設定価格になると通知。ユーザーの許可を得てGoogle Payで安全に代理購入まで行う機能も今後数ヶ月以内に展開されます。
Geminiアプリと生成AIツールの進化
Google I/O 2025では、Geminiアプリがより強力なAIアシスタントへと進化するとともに、クリエイティブな表現を支援する生成AIツール群の大幅なアップデートが発表されました。
Geminiアプリの進化
Googleは、Geminiアプリを「パーソナル(Personal)」「プロアクティブ(Proactive)」「パワフル(Powerful)」なAIアシスタントへと進化させることを目指していると強調されました。

パーソナルコンテキストの強化: 検索履歴に加え、ユーザーの許可に基づきGoogleカレンダー、Gmailなどの情報をGeminiが活用し、よりユーザーに最適化されたサポートを提供します。
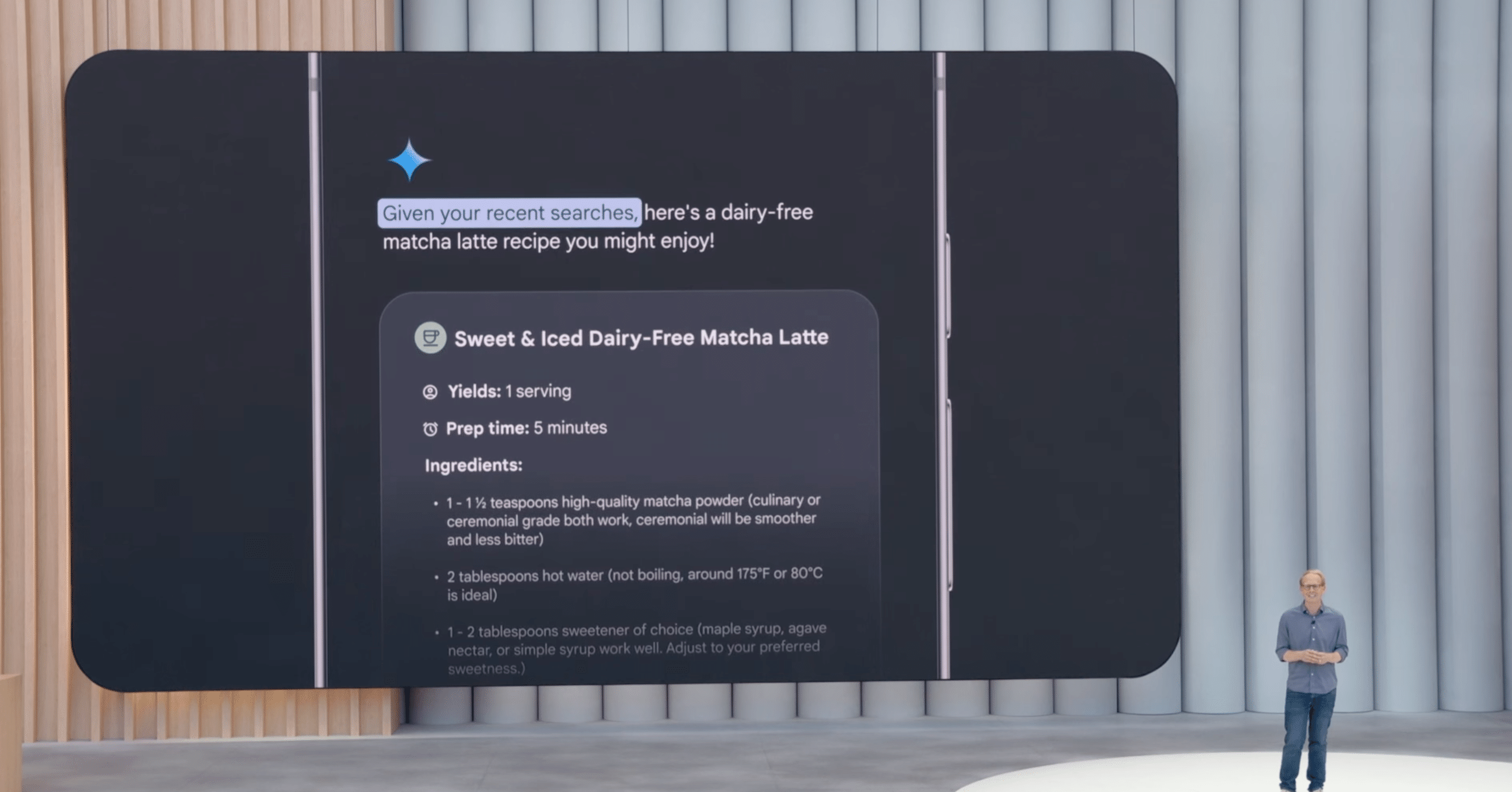
例えば、試験の予定を把握してカスタムクイズを生成したり、ユーザーの興味に合わせた解説動画を作成したりといったデモが紹介されました。
まさにただの指示待ちではなく、プロアクティブにAI側から行動を起こしてくれる体験です。。。
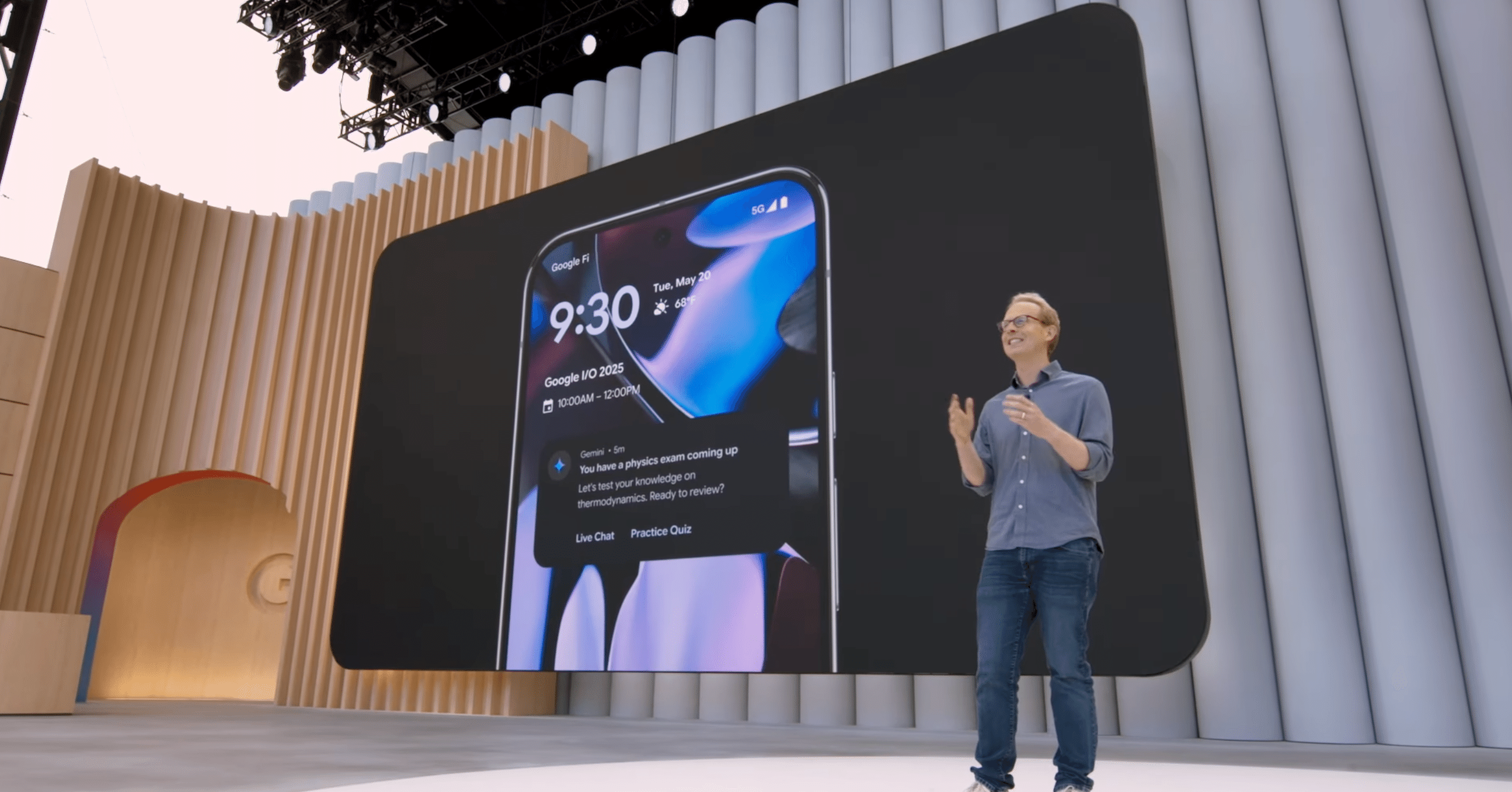

Gemini Liveの無料化と機能拡張: カメラや画面共有を通じたリアルタイム対話機能が、本日よりAndroidおよびiOSのGeminiアプリで45以上の言語、150以上の国で無料提供されます。会話の長さはテキストベースの5倍に達しているとのことです。今後数週間以内に、Googleカレンダー、マップ、Keep、Tasksといったアプリとの連携も追加予定です。
Deep Researchの強化: ユーザー自身が持つファイルをアップロードして、それを基に詳細な調査を行える機能が本日より追加されました。近日中にはGoogle DriveやGmail内の情報も調査対象に含められるようになります。
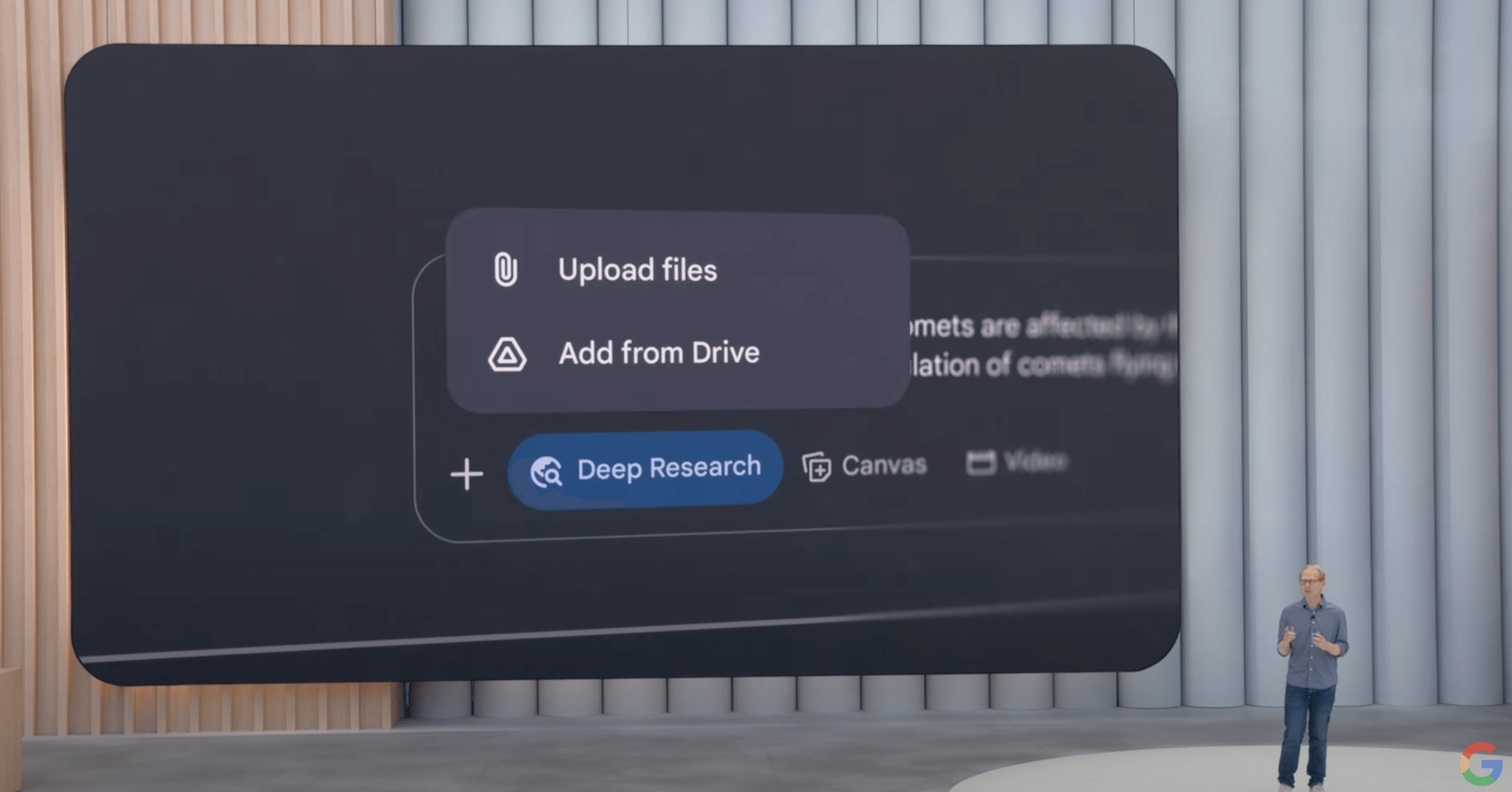
Canvasでのコンテンツ共同制作・変換: Geminiの共同制作スペースであるCanvasでは、レポートなどの情報を基に、ウェブページ、インフォグラフィック、クイズ、45言語対応のポッドキャストなどをワンタップで生成できるようになります。インタラクティブなシミュレーション作成なども可能です。

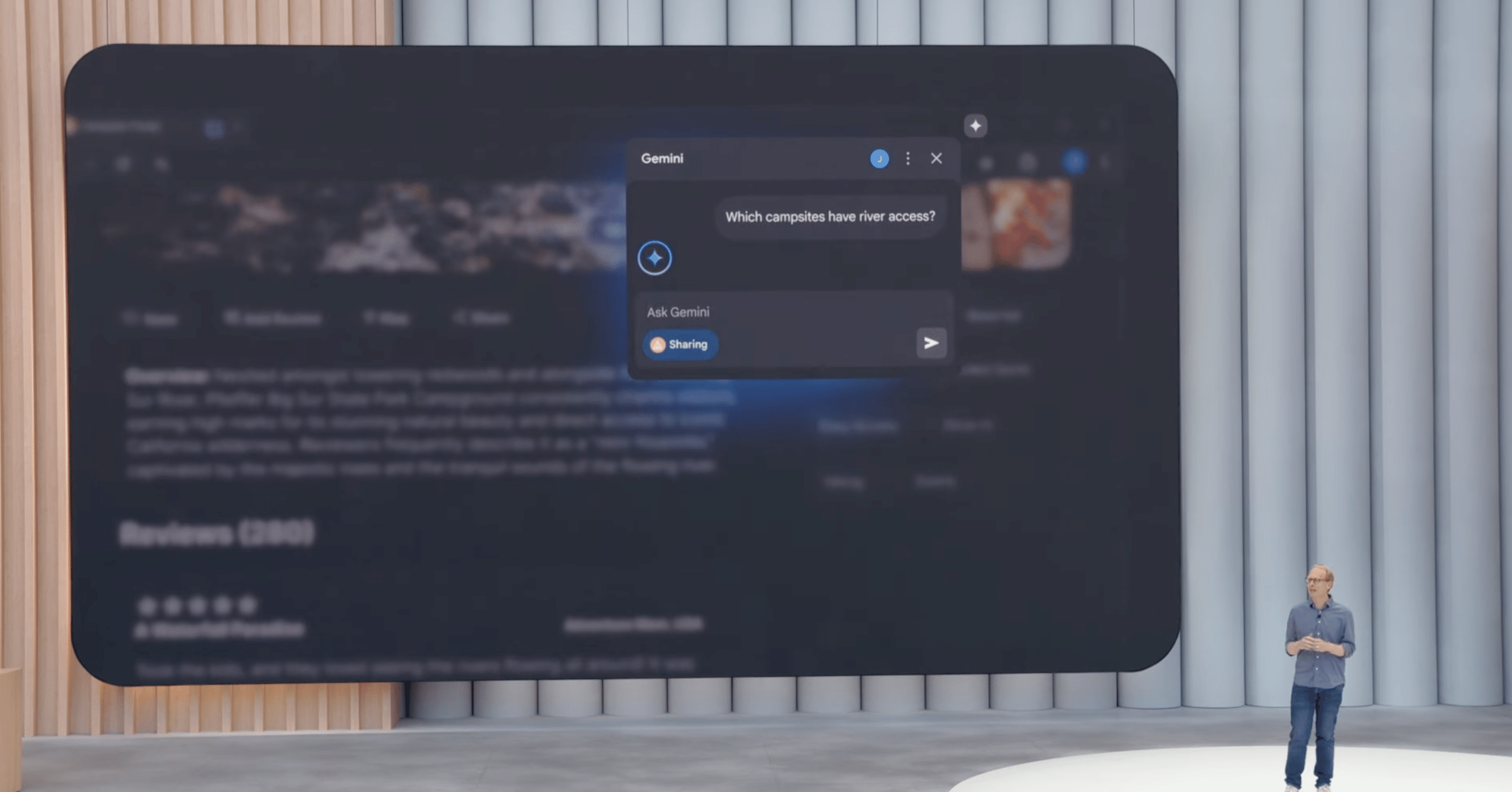
Gemini in Chrome: ChromeブラウザにGeminiが統合され、閲覧中のウェブページのコンテキストを理解し、質問応答や情報比較などをサポートします。今週より米国のGeminiサブスクライバー向けに提供が開始されます。
画像生成モデル「Imagen 4」
そして、いよいよ最新の画像生成モデル「Imagen 4」が発表されました。Geminiアプリに本日より搭載されます!!

品質向上: より豊かな色彩、繊細なディテール表現が向上し、特にテキストやタイポグラフィの生成精度が大幅に改善されました。デモでは、文脈に合わせたフォントデザイン(恐竜の骨を模したフォントなど)も披露されました。
高速化: 従来のモデルと比較して10倍高速に画像を生成できます。

https://twitter.com/GoogleDeepMind/status/1924892780876464362
動画生成モデル「Veo 3」
最先端の動画生成モデル「Veo 3」もGeminiアプリに本日より搭載されました。

品質と物理理解の向上: 映像のリアリティや、物理法則の理解度がさらに向上しています。
ネイティブ音声生成: さらに、Veo 3の大きな特徴として、動画と同時に効果音、背景音、キャラクターのセリフといった音声をネイティブに生成できる機能が追加されました。
Xでもすでに圧巻のデモが多く紹介されています。
https://twitter.com/GoogleDeepMind/status/1924893528062140417
Music AI Sandbox と Lyria 2
プロフェッショナル向けの音楽制作を支援するツールとして「Music AI Sandbox」が紹介され、その中核をなす音楽生成モデル「Lyria 2」が発表されました。

Lyria 2: 高品質な楽曲やボーカル(ソロ、コーラス)を含むプロフェッショナルグレードのオーディオを生成できます。
提供対象: Lyria 2は本日より、エンタープライズ、YouTubeクリエイター、ミュージシャン向けに提供が開始されます。
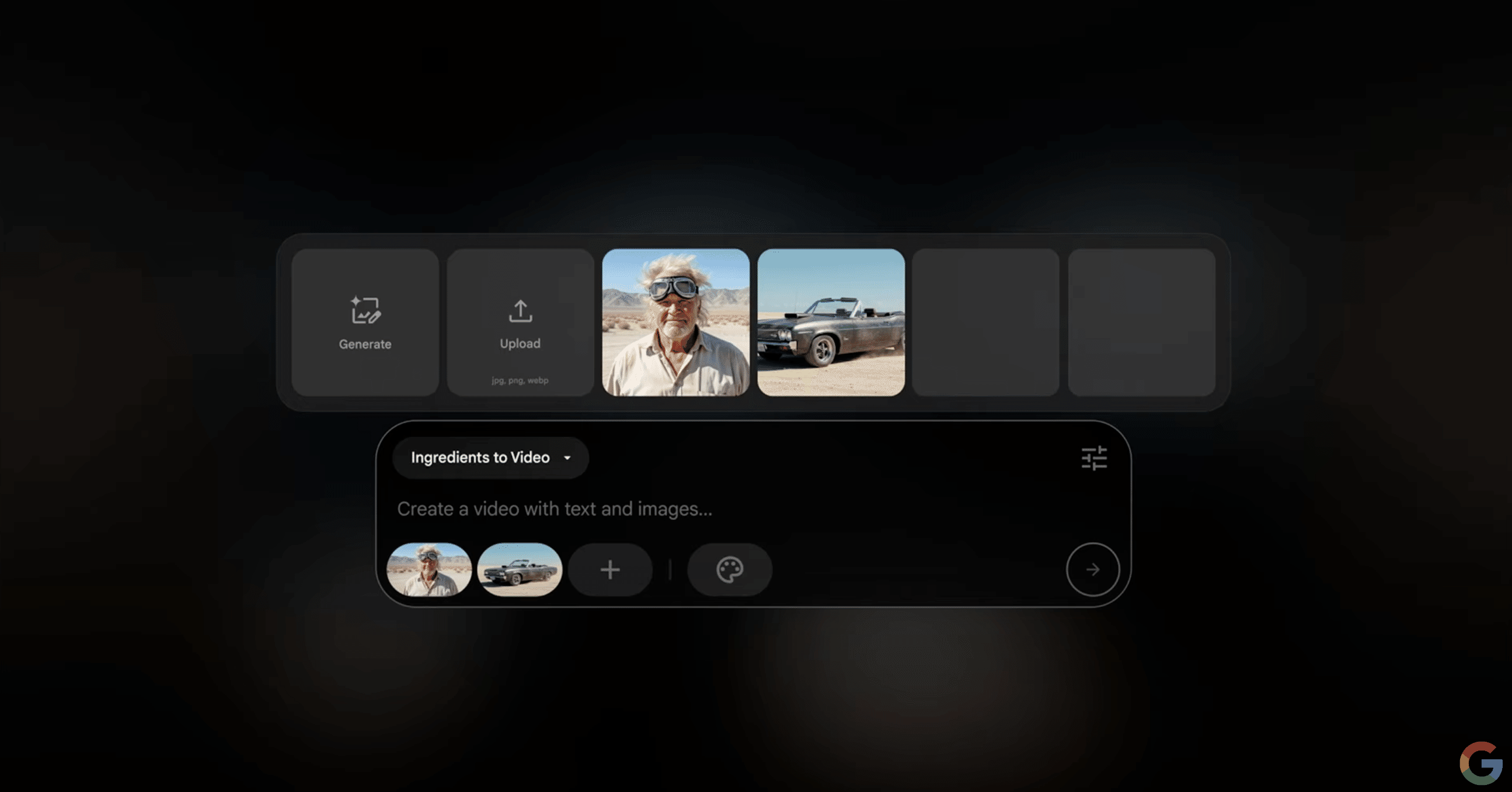
AIフィルムメイキングツール「Flow」
さらにVeo、Imagen、Geminiの技術を統合した、クリエイター向けの新しいAIフィルムメイキングツール「Flow」が発表され、本日より提供が開始されました(Google AI Ultraサブスクライバー向け)。

機能: ユーザーがアップロードした画像やImagenで生成した画像を基に、プロンプトによるシーン記述、正確なカメラコントロール指示、既存クリップの延長、Lyriaによる音楽追加などを行い、映像作品を制作できます。
AIサブスクリプションプランの刷新
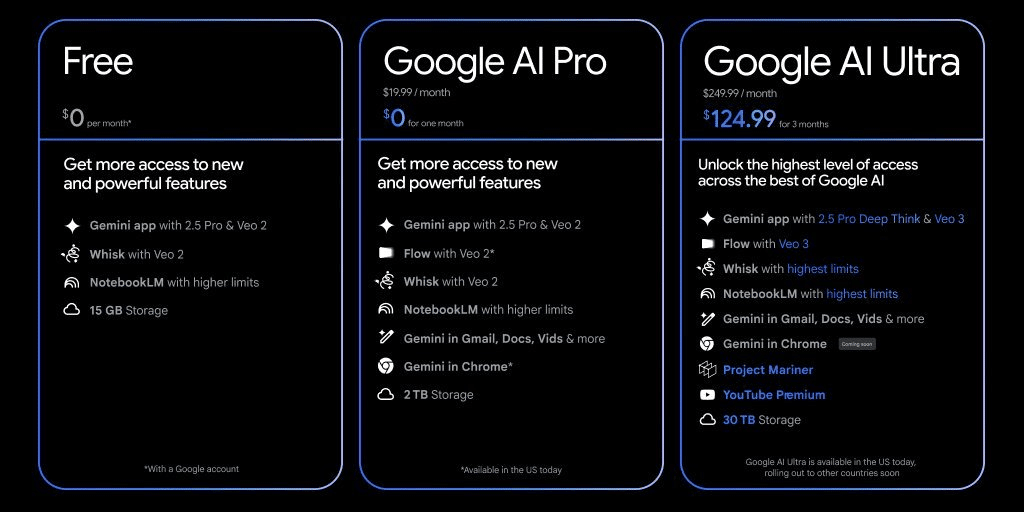
Googleは、AI機能をより多くのユーザーが利用できるように、既存のサブスクリプションプランを刷新し、新たに「Google AI Pro」と「Google AI Ultra」の2つの有料プラン、および無料プランを発表しました。最高価格の「Google AI Ultra」は日本で未展開であることに注意が必要です。
Google AI Pro ($19.99/月)
旧AI Premiumプラン後継、価格据え置き。
Geminiアプリ(2.5 Pro, Veo 2搭載)、Flow (Veo 2版)、2TBストレージ等を提供。
Google AI Ultra ($249.99/月)
Google AI最高峰へのアクセス、最高利用上限、新機能への早期アクセス権。
Geminiアプリ(2.5 Pro Deep Think, Veo 3搭載)、Flow (Veo 3版)、Project Mariner、YouTube Premium、30TBストレージ等。
米国で本日提供開始、日本含む他国も順次展開。初回3ヶ月50%オフ特典あり。
SynthID と SynthID Detector
また、AIによって生成されたコンテンツの透明性を高めるための取り組みとして、Googleは2年前に電子透かし技術「SynthID」を発表しました。これまでに100億以上のコンテンツにSynthIDが埋め込まれているとしています。
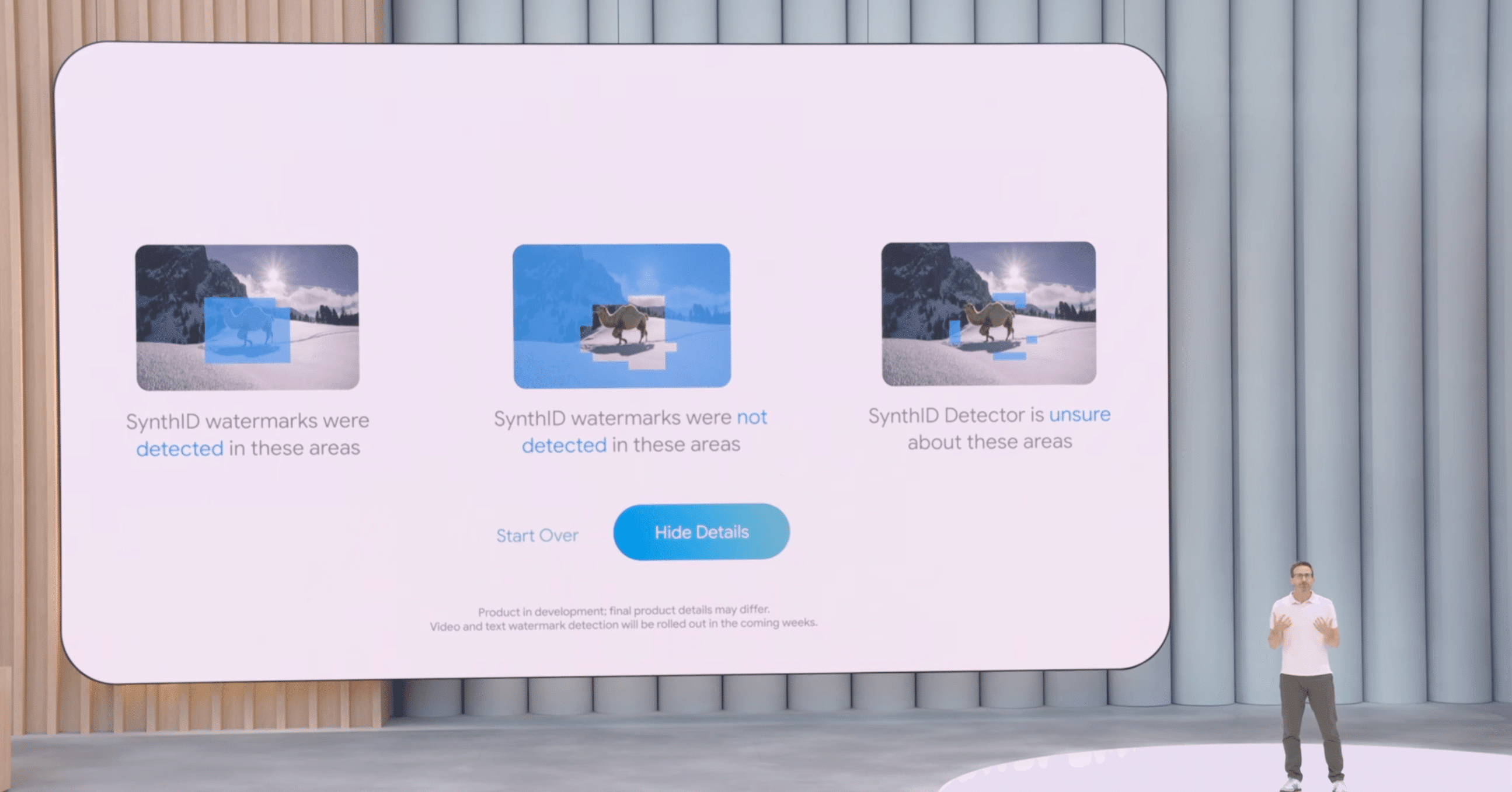
今回、この取り組みをさらに進め、AI生成コンテンツの識別を容易にするための新しいツール「SynthID Detector」が発表されました。この検出ツールは、画像、音声、テキスト、動画にSynthIDが含まれているかどうかを、全体だけでなく部分的な使用であっても識別できるとのことです。
SynthID Detectorは、本日より早期テスター向けに提供が開始されます。Googleはまた、SynthIDの普及と検出のため、パートナーシップを拡大していく方針も示しました。
AndroidとXRの未来
終盤では、Androidプラットフォームの進化と、AIを核とした次世代のXR(Extended Reality)体験のビジョンが示されました。
AndroidエコシステムとGeminiの統合
Androidは、スマートフォンだけでなく、スマートウォッチ(Wear OS)、自動車(Android Auto)、テレビといった多様なデバイスに搭載されるプラットフォームです。Googleは、これらのAndroidエコシステム全体にGeminiを深く統合し、ユーザーがどこにいても一貫して役立つAIアシスタント体験を提供することを目指しています。先週のAndroid Showでは、Android 16やWear OS 6に関するアップデートも発表されています。

Android XR プラットフォーム
AI時代に最適化された新しいプラットフォームとして「Android XR」が正式に発表されました。

これは、ヘッドセットから軽量グラスまで、様々なフォームファクタのXRデバイスをサポートすることを目指し、SamsungおよびQualcommとの協力のもとで開発されています。
既存のAndroidアプリもAndroid XR上で動作します。

Samsung「Project Moohan」ヘッドセット:
Android XRを搭載する最初のデバイスとして、SamsungのVRヘッドセット「Project Moohan」が紹介されました。
ユーザーは無限に広がる仮想スクリーンでアプリを操作でき、Geminiアシスタントと対話しながらGoogleマップで世界中を探索したり、MLBアプリでスタジアムにいるかのような臨場感で野球観戦を楽しんだりするデモが披露されました。
Project Moohanは、2025年後半に発売予定です。

Android XR グラス:
より日常的な利用を想定した、軽量な「Android XR グラス」のプロトタイプも発表されました。
これらのグラスは、カメラ、マイク、スピーカーを搭載し、オプションでレンズ内に情報を表示するディスプレイも備えています。スマートフォンと連携し、ハンズフリーでGeminiアシスタントを利用できます。

デモンストレーションでは、I/Oのバックステージでグラスを装着したGoogle社員が、周囲の状況についてGeminiに質問したり(例:写真のバンド名を尋ねる)、テキストメッセージを送信したり、通知をミュートしたり、さらには異なる言語(ヒンディー語とペルシャ語)を話す相手とリアルタイム翻訳を介して自然に会話したりする様子が披露されました。

NBA選手のヤニス・アデトクンボもこのグラスを装着して登場!!

最初のアイウェアパートナーとして、Gentle Monster と Warby Parker が発表され、将来的にはさらに多くのブランドが参加する予定です。Android XR グラスの開発者向け提供は、2025年後半に開始される予定です。

まとめ
Google I/O 2025は、AI、特に「Gemini」が私たちの生活を大きく変えることを予感させる発表に満ちていました。
今年のキーワードは、Geminiの「自律性」と「パーソナライゼーション」の深化です。AIがユーザーの状況をより深く理解し、能動的にサポートする未来が示されました。
さらに、これらの進化したAIが「Google Beam」のような新しいコミュニケーションツールや、「AI Mode」による次世代検索、そして「Android XR」といった新しいハードウェアと融合することで、全く新しいユーザー体験が生まれようとしています。動画・画像生成AIの進化も目覚ましく、クリエイティブの可能性を大きく広げるでしょう。
AIの倫理的な利用への配慮も示されつつ、2025年はGoogleのAI技術が私たちの日常や創造活動を新たな次元へと導く一年になりそうです。
お知らせ:
本日20時より「Google I/O 2025」開幕に合わせ、AGI CastをLIVE配信でお届けします。AIに関する主要な発表と、その注目ポイントを分かりやすく解説していきます!
追いきれてないという方はぜひ以下のリンクからご視聴ください!
AGI Castは、ChatGPT研究所が運営するAI特化型Podcastです。この番組では、最新のAIニュースや業界の動向をわかりやすく解説し、役立つ視点をお届けします。
https://www.youtube.com/live/POjIn5YEoIk?si=sW5JRxwpaJp0951Z
Keynote本編はこちら:
https://www.youtube.com/live/o8NiE3XMPrM?si=ZYIxaGed0xHG0Jcr





