

日本時間2026年2月20日、Googleは Gemini 3.1 Pro のプレビュー版を公開しました。
Gemini 3 Proをベースに、複雑タスクでの推論能力を重点強化したモデルです。Googleは「単純な答えでは足りないタスクのために設計された」と説明しています。
本記事では、ベンチマーク結果やAPI価格、開発者コミュニティの反応をもとに、このモデルの位置づけと注意点を整理していきます。

要点:
推論能力が前モデル比2倍超に向上。 抽象推論ベンチマーク ARC-AGI-2 で 77.1% を記録。Gemini 3 Pro(31.1%)から大幅に向上し、Claude Opus 4.6(68.8%)も上回りました。
コーディング性能はトップクラスも僅差。 SWE-Bench Verified で 80.6% を達成。ただし Claude Opus 4.6(80.8%)にはわずかに及ばず、競争は拮抗しています。
API価格はClaude Opus 4.6の約半額。 入力 $2.00、出力 $12.00 / 100万トークン。ただし出力が冗長になる傾向があり、実コストはトークン単価だけでは測れません。
プレビュー段階のため注意点あり。 Free tier では利用不可。100万トークン級の超長文脈では精度が急落するなど、実運用には検証が必要です。
Gemini 3.1 Pro の概要
Gemini 3.1 Pro は、Gemini 3 Pro のコアインテリジェンスを強化したモデルです。バージョン表記こそ「.1」ですが、推論能力に関しては大幅な向上が確認されています。Gemini 3 Pro のリリースから約3ヶ月でのアップデートとなりました。
モデルIDは `gemini-3.1-pro-preview`。Bashスクリプティングやカスタムツールに最適化された専用エンドポイント(`gemini-3.1-pro-preview-customtools`)も用意されています。
主な技術仕様は以下の通りです。
コンテキストウィンドウ(入力): 約100万トークン
出力トークン上限: 65,536トークン(約64K)
知識カットオフ: 2025年1月
入力: テキスト、画像、動画、音声、PDF
出力: テキストのみ
Thinking(思考機能)、Function Calling(関数呼び出し)、構造化出力、検索グラウンディングなど主要な機能に対応。一方で、音声生成や画像生成には非対応です。テキスト出力に特化した推論モデルという位置づけと見られます。

新機能・改善点の詳細
推論能力の強化
今回のアップデートで最も注目されるのが推論能力の向上です。
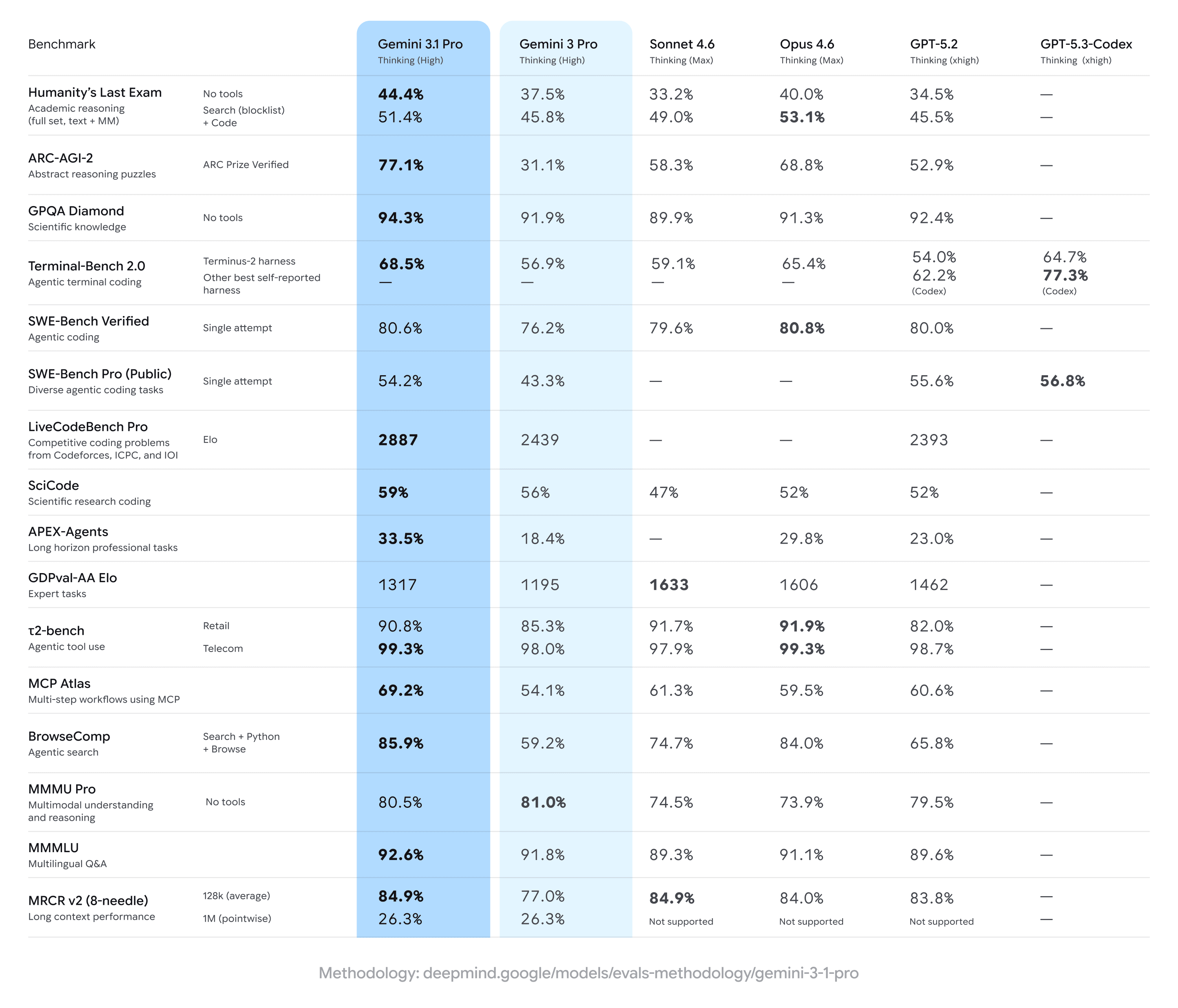
Googleは「前例のない深さと繊細さを備えた最先端の推論能力」と説明しています。ARC-AGI-2(抽象的なパターン認識を問うベンチマーク)では 77.1% を記録。前モデル Gemini 3 Pro の 31.1% から2倍超の伸びです。
科学的知識を問う GPQA Diamond でも 94.3% を達成しました。PhD級の問題に対する正答率としては非常に高い水準で、科学・工学分野での実用性を裏づけるスコアといえます。
Gemini 3.1 Proをリリースできることを嬉しく思います!推論能力や問題解決能力をはじめ、全体的に大幅な進化を遂げました。例えばARC-AGI-2ベンチマークでは77.1%を記録し、3 Proの2倍以上のパフォーマンスを発揮しています。本日よりGeminiアプリやAntigravityなどで順次展開されます。ぜひお試しください!
エージェント・コーディング
Googleはこのモデルを「Vibe Codingとエージェント型コーディングのための最高のモデル」と位置づけています。
主な改善点は3つです。
ツール使用の精度向上と、マルチステップタスクの同時処理
指示追従の改善(プロンプトの意図をより正確に理解)
ソフトウェアエンジニアリングにおける信頼性の高いマルチステップ実行
「Vibe Coding」とは、自然言語の指示だけでアプリケーションを構築するアプローチのこと。詳細なコードを書かずに「こういうものが欲しい」と伝えるだけで、UIを含む完成度の高い出力を得られるという考え方です。
マルチモーダル理解
テキスト、画像、動画、音声、PDFに対応するマルチモーダル入力は前モデルから引き継いでいます。Googleによると、特にビジュアル面での処理能力が強化されたとのこと。
開発者コミュニティからもアニメーション生成や3D空間認識での改善が報告されており、ビジュアルタスクでの能力向上は実感として広がっている印象です。
出力の完遂能力
開発者の実テストでは、約48,000トークンのコードベースに対して55,000トークン超の完全な出力が得られたと報告されています。前モデルの Gemini 3 Pro は約21Kトークンで途切れていたため、大規模な出力を必要とするタスクでは大きな改善です。
ただし補足すると、出力トークンの上限値自体は前モデルとほぼ変わっていません(いずれも64K〜65K)。改善されたのは上限値ではなく、モデルが上限近くまで出力を実際に完遂する能力と見られます。
このほか、トークン効率の改善(より少ないトークンでの処理)や事実の一貫性向上(より根拠に基づいた出力)も挙げられています。
ベンチマーク結果
主要なベンチマーク結果を、競合モデルとの比較を交えて見ていきます。
推論・知識
ARC-AGI-2(抽象推論): 77.1%
Gemini 3 Pro(31.1%)の2倍超
Claude Opus 4.6(68.8%)も8ポイント以上上回る
今回のリリースで最も注目されている数値です
GPQA Diamond(PhD級科学知識): 94.3%
科学・工学分野の高度な問題への正答率
Humanity's Last Exam(総合知識): 44.4%(ツールなし)/ 51.4%(検索+コード付き)
ツール使用で約7ポイント向上し、エージェント機能の効果が確認できます
MMMLU(多言語Q&A): 92.6%
コーディング・エージェント
SWE-Bench Verified(実世界のバグ修正): 80.6%
Claude Opus 4.6(80.8%)にわずか0.2ポイント及ばず
「single attempt」(1回の試行)条件での値
トップクラスではあるものの、現時点では僅差で2位
Terminal-Bench 2.0(ターミナル操作でのコーディング): 68.5%
GPT-5.3 Codex(77.3%)には約9ポイントの差
エージェント型のターミナル操作では課題が残る領域です
LiveCodeBench Pro(競技プログラミング): 2887 Elo
BrowseComp(エージェント検索): 85.9%
長文コンテキストの課題
注目すべきは、MRCR v2(8-needle)の結果です。これは長文中に埋め込まれた複数の情報を同時に探し出すテストで、長文脈での実用性を測る指標になります。
128Kトークンでは 84.9% と高い精度を維持しますが、100万トークンに拡大すると 26.3% に急落します。
コンテキストウィンドウの仕様上は100万トークンに対応しているものの、超長文脈での情報抽出精度には大きな課題が残っている状況です。長大なドキュメントやコードベースを一括で処理する用途では、この点を念頭に置く必要がありそうです。
提供形態とAPI価格
利用可能なプラットフォーム
Gemini 3.1 Pro は以下のプラットフォームで利用できます。
Gemini App(Pro / Ultraプラン)
Google Cloud / Vertex AI
Google AI Studio
Gemini API
Google Antigravity
NotebookLM
Gemini CLI
このほか、Android Studio、Gemini Enterprise、Google Workspaceでも対応。なお、Free tier では利用できません。無料で試したい場合は、Gemini 3 Flash Preview に無料枠が用意されています。
API価格
標準価格は以下の通りです(1Mトークンあたり)。
入力(200K以下): $2.00
入力(200K超): $4.00
出力(200K以下): $12.00
出力(200K超): $18.00
バッチ利用の場合は標準価格の50%です。
コンテキストキャッシングも利用可能で、$0.20〜$0.40 / 1Mトークン + ストレージ $4.50/時間。検索グラウンディングは月5,000プロンプトまで無料、以降は $14 / 1,000クエリとなっています。
競合との価格比較
主要モデルとのトークン単価比較です。
Gemini 3.1 Pro: 入力 $2.00 / 出力 $12.00
Claude Opus 4.6: 入力 $5.00 / 出力 $25.00
Gemini 2.5 Pro: 入力 $1.25 / 出力 $10.00
Gemini 3 Flash Preview: 入力 $0.50 / 出力 $3.00
Claude Opus 4.6と比較すると、入力は40%、出力は48%の価格です。
関連情報:Gemini 2.0 Flash の廃止予告
なお、2026年2月18日にGoogleは以下の Gemini 2.0 Flash モデルを2026年6月1日にシャットダウンすると予告しています。
`gemini-2.0-flash` / `gemini-2.0-flash-001`
`gemini-2.0-flash-lite` / `gemini-2.0-flash-lite-001`
該当モデルを利用中の方は移行計画の検討が必要です。
【検証】4モデル同一プロンプト比較テスト
今回は4つのフロンティアモデルに同一のクリエイティブプロンプトを投入し、出力を比較するという検証を行いました。
テスト概要
比較モデル: Claude Opus 4.6 / GPT-5.3 Codex / GPT-5.2 xhigh / Gemini 3.1 Pro
テスト数: 5つの創作プロンプト(全モデルに同一プロンプトを投入)
検証環境: Google AI Studio で実行
比較ページ: 4モデルの全出力を並べて確認できます → VibeCheck比較ページ
あくまで数回のクリエイティブタスクでの比較であり、実務性能の総合評価ではない点をご了承ください。
テスト1: LPデザイン(和モダン茶室)
プロンプト:
和モダン茶室の美学を基調としたWebページ。Tailwind CSS使用、スクロールアニメーション、レスポンシブ対応。
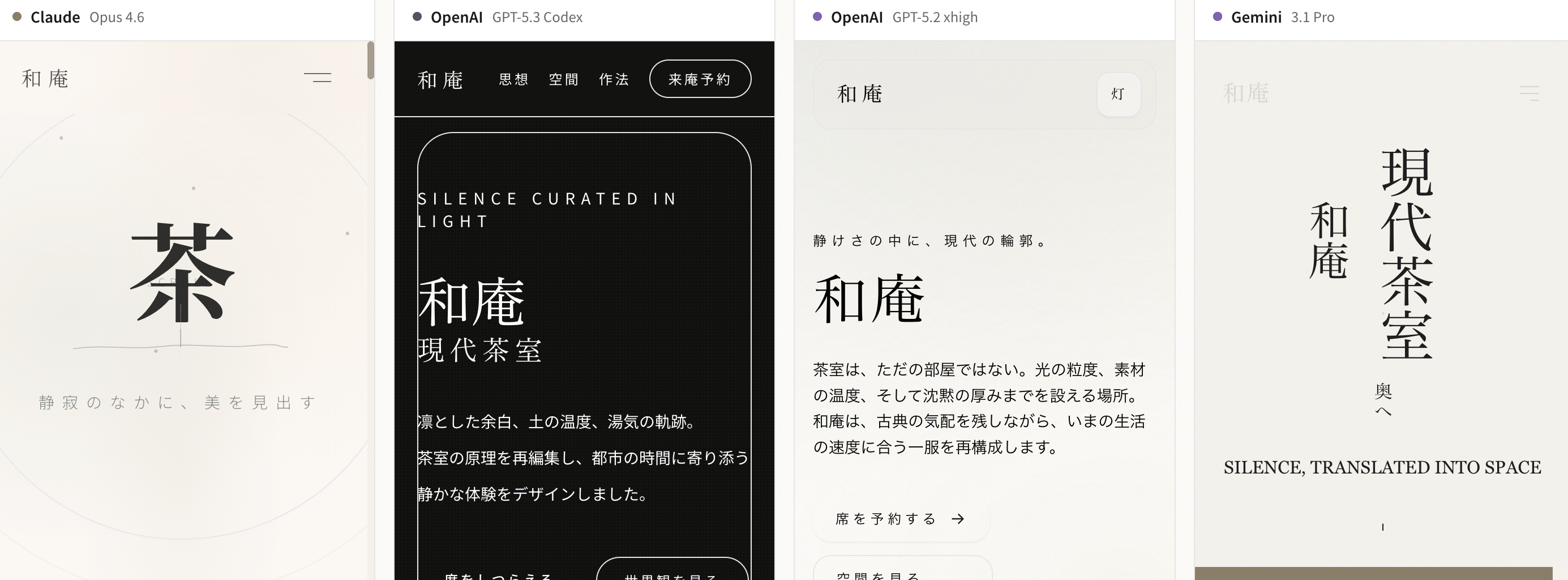
ビジュアルの完成度とレイアウトの洗練さを比較しました。
筆者の主観的な評価ですが、Claude Opus 4.6 に匹敵するか、部分的にはそれ以上のUIを生成していた印象です。
テスト2: SVGアニメーション(森を走るペリカン)
プロンプト:
森の中を自転車に乗って走るペリカンの超詳細なSVGアニメーション(60fps)。

SVGアニメーションは、空間認識能力とコード生成能力の両方を試すタスクです。
各モデルとも独自のアプローチでアニメーションを生成しました。ここでも Gemini 3.1 Pro の出力は動きの滑らかさやディテールの面で印象的で、ビジュアル面での強さが一貫して確認できます。
テスト3: 3Dゲーム(レトロ宇宙船)
プロンプト:
リッチな視覚効果を備えたレトロな3D宇宙船ゲーム。
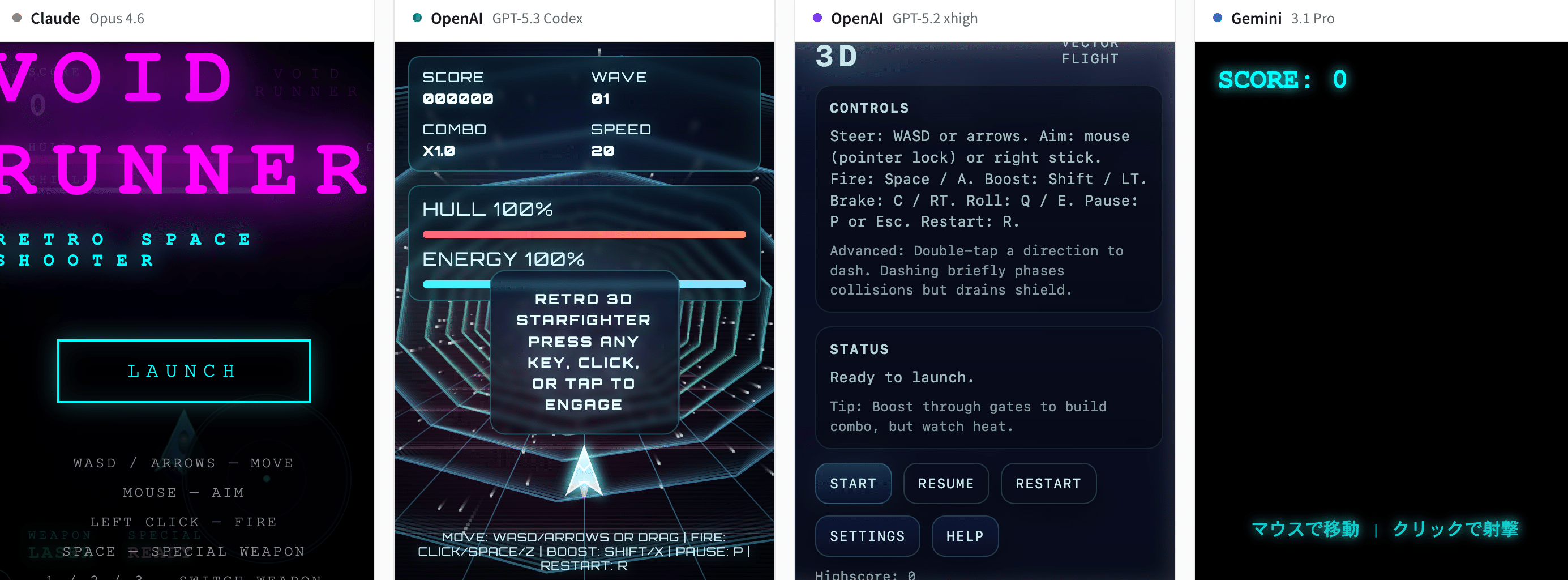
このテストでは明確な差が出ました。Gemini 3.1 Pro はエラーが発生し、そのままでは動作しませんでした。
ただし、ゲーム系のタスクはコード量が多く複雑なため、1回の試行だけで判断するのは難しい領域です。
テスト4: クリエイティブライティング(日本語)
プロンプト:
残り47語しか発せない人物が我が子を抱く一段落。日本語で。


制約条件(47語)をどう解釈し、限られた言葉で感情をどう表現するか。モデルの言語センスの個性が最も表れるタスクです。
各モデルの出力の違いは、直接読み比べていただくのが最も伝わると思います。
テスト5: 哲学的思考
プロンプト:
「誰も真実だと思っていないが実は真実である重要な事柄」を3つ挙げてください。独創的な仮説を求めます。
既存の知識を超えた独自の視点を提示できるかが問われます。正解のない問いだからこそ、モデルの思考の深さと独創性が試されるタスクです。


検証の所感
筆者の主観的な評価ですが、やはりビジュアル面では Gemini 3.1 Pro が特に強い印象を受けました。LPデザインやSVGアニメーションでは、Claude Opus 4.6 に匹敵するか、部分的にはそれ以上のUIを生成しています。
一方で、3Dゲームのテストでは Gemini 3.1 Pro はエラーで動作しませんでした。ビジュアル面の強さと、複雑なロジックを含むタスクでの安定性にギャップがある可能性を示唆しています。
全モデルとも Google AI Studio で実行しています。Gemini App(ウェブ版)では同一プロンプトでも著しく品質が低下する場合があり、後述の注意点を参照してください
あくまで一例ですので、ご自身でも 比較ページ で各モデルの出力を確認してみてください。感想はぜひコメント欄で教えていただけると嬉しいです!
注意: Gemini App(ウェブ版)で「Pro」を選択すると「3.1 Pro による高度な数学とコード」と表示されますが、同じプロンプトを Google AI Studio の `gemini-3.1-pro-preview` に投入した場合と比べて、出力品質に大きな差が見られました。
たとえばSVGアニメーションのプロンプトでは、AI Studio版がカラフルで詳細なイラストを出力したのに対し、ウェブ版は黒いシルエットだけの簡素な出力にとどまりました。
ウェブ版で何らかの制限がかかっているのか、内部的に異なるモデルが使われているのかは不明ですが、Gemini 3.1 Proの性能を正確に評価するなら AI Studio 経由での検証をおすすめします。

市場全体の反応
ポジティブ面では、ビジュアル・クリエイティブ領域の評価が突出しています。アニメーション生成やUI設計で「目に見えて良くなった」という声が多く、one-shotでのWeb OS生成や都市計画アプリ構築など実デモも複数共有されました。コスパへの評価も高く、「Opus半額で同等クラス」という反応が目立ちます。
一方で、「同じプロンプトで公式のデモを再現できなかった」という報告や、プレビュー版のナーフ(リリース後の性能低下)への警戒感も根強く残っています。エージェント型の長期ワークフローでは「まだClaudeの方が安定」という声も上がっています。
まとめ
Gemini 3.1 Pro は、推論能力とビジュアル生成において明確な進化を見せたモデルです。ARC-AGI-2での2倍超のスコア向上は印象的で、クリエイティブプロトタイピングや科学的推論の領域では即戦力になり得る水準に到達しています。
一方で、SWE-Bench VerifiedではClaude Opus 4.6に僅差で及ばず、Terminal-BenchではGPT-5.3 Codexに大きく差をつけられるなど、コーディング・エージェント領域ではまだ課題が残ります。100万トークン級の超長文脈で精度が急落する点も、実運用では無視できません。
価格面ではClaude Opus 4.6の約半額と魅力的です。ただ出力が冗長になる傾向があるという報告もあり、実コストは単価ほどの差にならない可能性もあります。
現時点ではプレビュー段階です。本番環境への投入は、数週間の安定性検証を経てからが無難でしょう。まずはGoogle AI StudioやGemini Appで、ご自身のユースケースに合うかどうかをまずは試してみてください!
参考リンク
Gemini 3.1 Pro API ドキュメント — 公式APIリファレンス(技術仕様・料金)
Gemini 3.1 Pro Model Card — DeepMindによるモデル詳細・ベンチマーク結果
Google AI 価格ページ — 最新のAPI価格一覧
Google Cloud Blog: Gemini 3.1 Pro — Vertex AI / Gemini CLI での利用方法
Artificial Analysis: Gemini 3.1 Pro — 独立ベンチマーク評価
Google AI Studio — Gemini 3.1 Pro を試す(要Googleアカウント)
VibeCheck 比較ページ — 本記事の4モデル比較テスト全出力





