

AIとの会話の中で、こんな経験はないでしょうか。
「この形式で報告書をまとめて」と毎回同じ指示を繰り返す。
「うちの会社のロゴとカラーで資料を作って」と頼んでも、結局は手作業で修正。
これまでのAI活用では、タスクの「やり方」をその都度伝え直す必要がありました。AIが、私たちの仕事の進め方や暗黙のルールを知らないからです。
この課題を解決するのが、Anthropicから登場したClaudeの新機能「スキル(Skills)」です。
AIに一度「仕事のやり方」を教え込めば、その手順を保存し、必要な時に自動で再現してくれる。いわば、AIのための手順書です。
この記事では「スキル」機能の基本から、具体的な活用法、そしてMCPとの違いまでを解説していきます。
Claudeの「スキル」とは?
「スキル」 とは、特定のタスクをこなすための指示書、関連資料、実行可能なプログラム(スクリプト)までを一つにまとめた、フォルダベースの能力パッケージです。Claudeを専門領域や業務フローに合わせて「特化」させることが可能です。
最近のClaudeに搭載された.docxや.pdfなどのドキュメント生成機能も、このスキルを用いて実装されています。スキルは単なる追加機能ではなく、Claudeの能力を支える中核的な仕組みです。
Anthropicは以下の3つをスキルが提供する大きな価値と強調しています。
① 専門性の付与 (Specialize Claude)
会社のブランドガイドライン適用や、特定のフレームワークに沿ったデータ分析など、組織や個人が持つ独自のドメイン知識をClaudeに与えることができます。これにより、Claudeは一般的なアシスタントから、あなたの業務を深く理解した専門家へと進化します。
② 繰り返し作業の削減 (Reduce repetition)
一度スキルを作成すれば、Claudeはタスクに応じて必要なスキルを自動で判断し、呼び出して使用します。毎回同じ指示をプロンプトに書き込む必要はなくなり、作業の一貫性と効率が劇的に向上。
③ 能力の組み合わせ (Compose capabilities)
スキルは単体で機能するだけでなく、複数のスキルを組み合わせ、より複雑なワークフローの構築も可能に。例えば、「PDFから情報を抽出し(PDFスキル)、その内容を分析して(分析スキル)、会社のフォーマットで報告書を作成する(文書作成スキル)」といった一連の作業の自動化です。
他の機能との違いは?
vs プロジェクト: プロジェクトは特定の話題に関する情報を蓄積する「場所」。対してスキルは、場所を問わず動的に起動する「手順書」です。

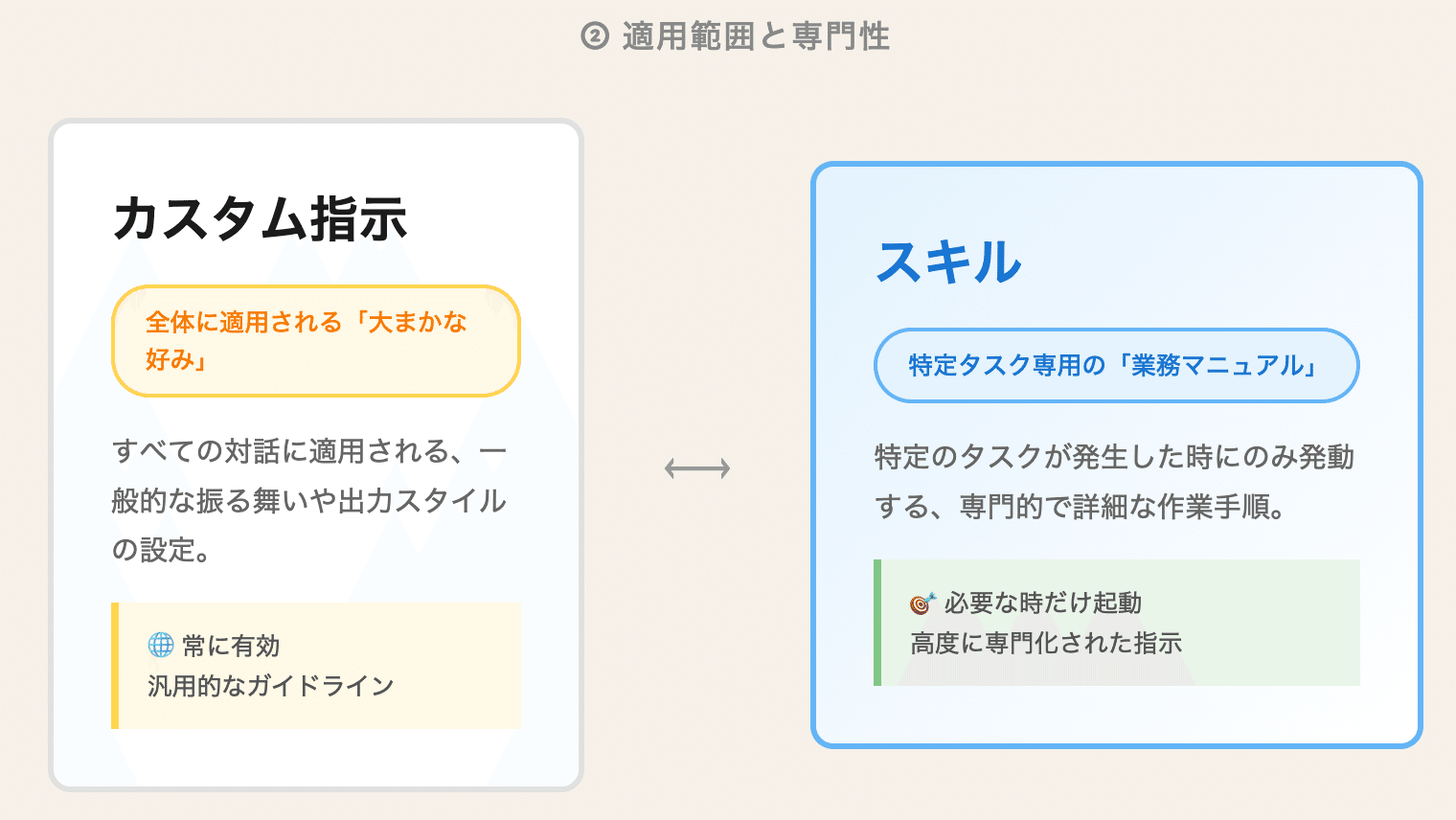
vs カスタム指示: カスタム指示は、すべての対話に適用される「大まかな好み」。スキルは、特定のタケスクにのみ発動する「専門的な業務マニュアル」と言えるでしょう。
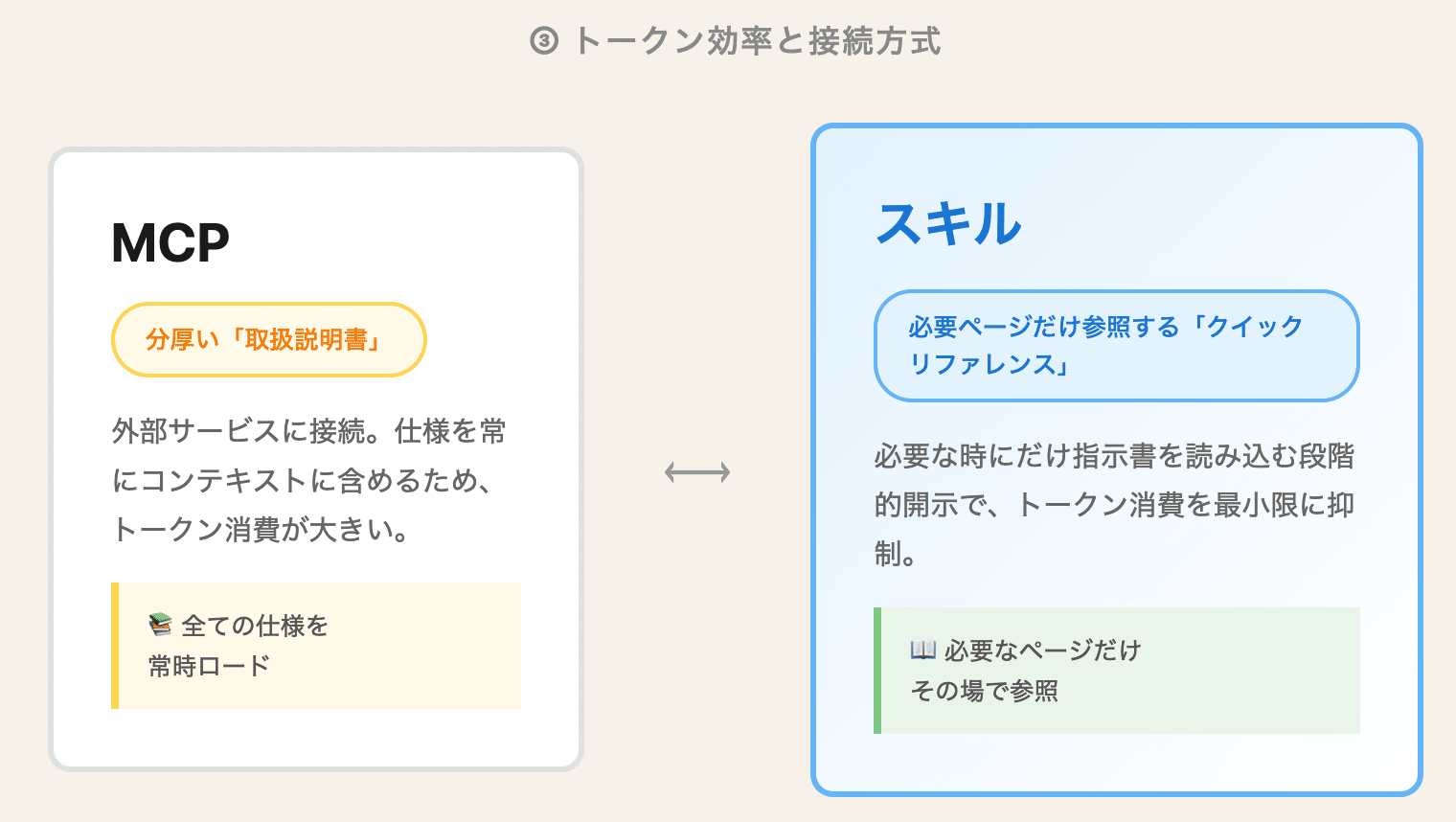
vs MCP (Model Context Protocol): MCPは外部サービスに「接続」しますが、その仕様を常にコンテキストに含めるため、トークン消費が大きいという課題がありました。一方、スキルは必要な時にだけ指示書を読み込むため、トークン消費を最小限に抑えられます。MCPが分厚い「取扱説明書」なら、スキルは必要なページだけを都度参照する「クイックリファレンス」です。
スキルの設定方法(使い方)
スキルを実際に使うための設定は非エンジニアの方にとっても非常にシンプルです。
利用条件:
対応プラン: Pro, Max, Team, Enterpriseの各プランで利用可能。
前提条件: Claudeの設定で「コード実行(Code Execution)」が有効になっていること。
スキルには、Anthropicが提供する「Anthropic製スキル」と、自身で作成する「カスタムスキル」の2種類が存在します。
ここでは、claude.ai でカスタムスキルを有効化する手順を見ていきましょう。
① 設定画面へ移動
Claudeの 設定 から 機能(Capabilities) を選択。
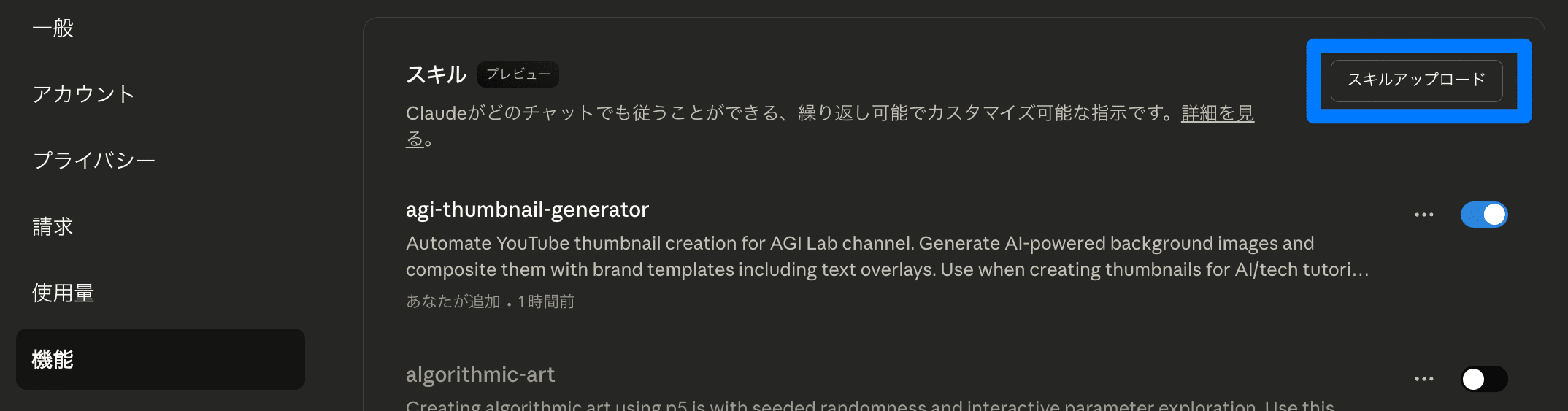
② スキルをアップロード
スキル(Skills) の項目で、用意したスキル(.zip形式)を右上の「スキルアップロード」からアップロードします。
これだけです。アップロードが完了すれば、Claudeが対話の文脈に応じて自動でスキルを使い始めます。
例えば、Notionが公開しているNotion Skills for Claudeのような、パートナー企業が提供するスキルをダウンロードし、自身のClaudeに導入することも一つの手です。
スキルの基本機能と仕組み
スキルの挙動を理解する上で、2つの重要な要素があります。
中核となる SKILL.md ファイルと、「段階的開示」という仕組みです。
SKILL.md ファイル:スキルの設計図
すべてのスキルの中心にあるのが、SKILL.md というマークダウンファイル。このファイルが、スキルの振る舞いを定義します。
ファイルの冒頭には、YAML形式で2つの情報を記述します。
name: スキルの名前(例: pdf-processing)
description: スキルが何をするのか、いつ使うべきかの説明
そして、その下にマークダウン形式で、Claudeに実行させたい具体的な指示や手順を書き込んでいきます。このファイルは、YAMLフロントマター(Markdownファイルなどの冒頭に書かれるメタデータブロック)と呼ばれるメタデータブロックから始める必要があります。
以下はPDF処理スキルの例です:
---
name: pdf processing
description: PDFからテキストや表を抽出し、フォーム入力や文書の結合を行います。PDF作業やPDF・フォーム・抽出が言及された場合に使用します。
---
# PDF Processing
## Quick start
pdfplumberを使ってPDFからテキストを抽出してください:
```python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()```
情報読み込みの仕組み
スキルは、すべての情報を一度に読み込むわけではありません。
3つのレベルで構成され、それぞれ必要な情報を必要な時にだけ読み込む「段階的開示(Progressive Disclosure)」という仕組みでトークン消費を抑え、効率的に動作します。
レベル1: メタデータ(常にロード)
SKILL.md の name と description (YAML フロントマターの部分)のみ。Claudeは常にこの情報だけを把握しており、「どんなスキルがあり、いつ使うべきか」を判断します。消費トークンはごくわずかです。レベル2: 指示書(トリガー時にロード)
ユーザーの指示が `description` と一致すると、Claudeはスキルを「トリガー」します。この時、初めて `SKILL.md` の全文(Markdownの部分)がコンテキストに読み込まれ、Claudeは具体的な指示を理解します。

レベル3: 外部リソース(必要に応じてロード)
`SKILL.md` の中で言及されている追加の参考資料(例: `forms.md`)やPythonスクリプトは、さらに必要になった場合にのみ、個別に読み込まれます。
この仕組みを図で見てみましょう。

図のように、ユーザーがPDFの操作を依頼すると、以下のステップで情報が段階的に読み込まれます。
① Claudeは `pdf` スキルをトリガーし、`SKILL.md` を読み込みます。
② `SKILL.md` の内容を解釈し、さらに詳細な情報が書かれた `forms.md` を参照する必要があると判断します。
③ `forms.md` を読み込み、最終的なタスクを実行します。
このように、一度にすべての情報を読み込むのではなく、必要な情報を必要な分だけ参照していくことで、トークンの消費を最小限に抑えつつ、複雑なタスクを実行できるのがスキルの強みです。
活用事例5選
Anthropicは、スキルの活用例を示すため、公式のGitHubリポジトリで多様なサンプルスキルを公開しています。
リポジトリで公開されているスキルの中からいくつか紹介します。
`document-skills`: Claudeのドキュメント生成・編集機能の中核。Word(.docx), Excel(.xlsx), PowerPoint(.pptx), PDFの作成や編集といった、複雑なファイル操作を実現します。ウェブ版のClaudeには標準で搭載されています。
`webapp-testing`: ローカル環境で動作しているWebアプリケーションを、Playwrightを使ってテスト。UIの検証やデバッグを自動化します。
`artifacts-builder`: ReactやTailwind CSSといったモダンな技術を使い、インタラクティブなHTML成果物(Artifacts)を構築します。
これらの例が示すように、スキルの応用範囲は、日常的な作業の自動化から、専門的な開発業務の支援まで、非常に多岐にわたります。





