

日本時間2026年2月6日、AnthropicとOpenAIがほぼ同時に大型アップデートを発表しました。
Anthropicからは最上位モデル Claude Opus 4.6 と、Claude Codeでエージェントを並列に動かす Agent Teams。OpenAIからは、コーディングと実務を統合した GPT-5.3-Codex と、それを動かす Codexデスクトップアプリ。
本記事では、両社のリリース内容をまとめ、何が変わったのかを整理します!
要点
Opus 4.6:1Mコンテキスト対応のOpus初モデル。 エージェント的なタスク、長文脈の情報検索、コーディングで業界最高水準のベンチマークを記録。価格は据え置き($5/$25 per 1M tokens)。
Agent Teams:Claude Codeで複数エージェントが並列稼働。 リサーチ、コードレビュー、仮説検証など独立性の高いタスクを分担させる仕組み。research previewとして公開。
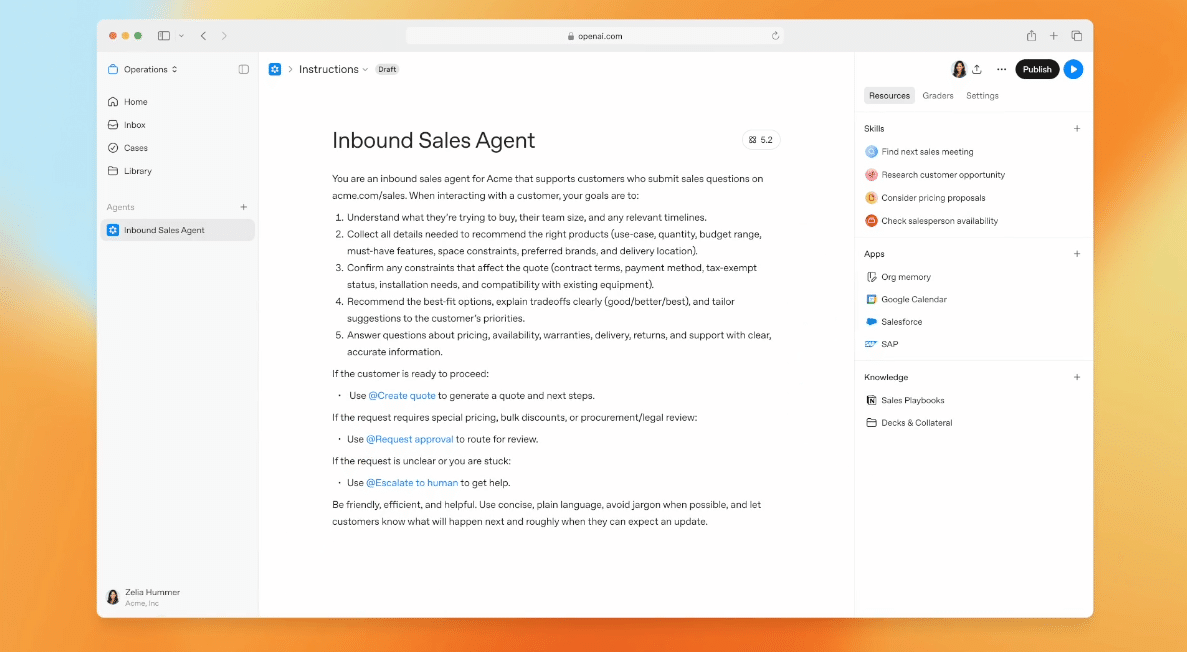
GPT-5.3-Codex:コーディングから実務全般をカバーする統合モデル。 前世代比25%高速化。SWE-Bench Pro・Terminal-Bench 2.0でSOTA。作業中に対話しながらステアリングできる設計。
Codexデスクトップアプリ:エージェントの司令塔。 複数エージェントの並列管理、Skills、Automations(定期実行)を搭載したmacOS向けアプリ。
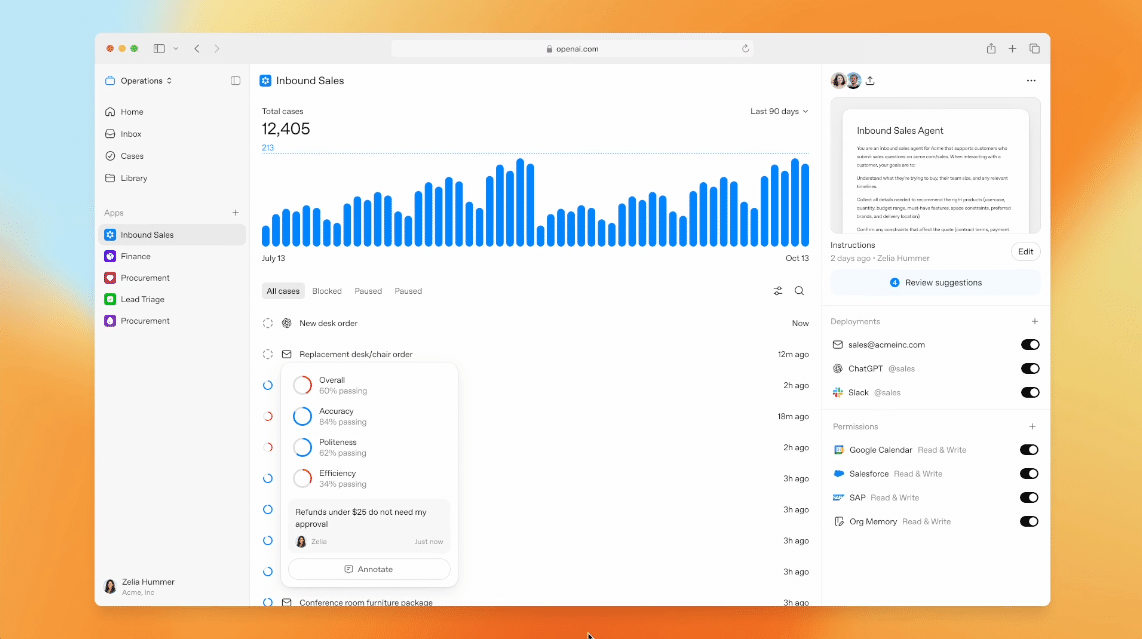
両社の同時発表を受け、Xでは早朝から開発者が実際に触り始め、ベンチマーク数値よりも「自分のプロジェクトで動かしてどうだったか」という実践的な報告が飛び交っています。
全体として、Opusは長文脈やコードレビューでの「一緒に考えてくれる感」、Codexは速度とタスク完遂力への評価が目立つ印象です。
以下では、それぞれの中身を詳しく見ていきます。
Claude Opus 4.6 の概要
Opus 4.6は、Anthropicの最上位モデル「Opus」シリーズの最新版です。前モデルのOpus 4.5から、コーディング、エージェント的なタスク、長文脈処理の3つの軸で強化されています。

何が変わったか
最大の変化は 1Mトークンのコンテキストウィンドウ(ベータ)に対応したことです。Opusクラスのモデルでは初めてとなります。出力も 最大128kトークン まで拡張され、大規模なコード生成や長文レポートの一括出力が可能になりました。
Anthropicの説明によると、Opus 4.6はタスクの難しい部分により深く集中し、簡単な部分はすばやく通過する傾向があるとのことです。推論を慎重にやり直す場面が増えたため、難しい問題では精度が上がる一方、単純なタスクではコストやレイテンシが増える場合もあります。その調整のために、effortパラメータが導入されています。
CLIからは /model で切り替えられます
Adaptive Thinking と Effort
これまで拡張思考(extended thinking)はON/OFFの二択でしたが、Opus 4.6では Adaptive Thinking が導入されました。モデル自身が文脈から「深く考えるべきか」を判断します。
開発者向けには 4段階のeffortレベル が用意されています。low、medium、high(デフォルト)、maxの4つで、タスクの性質に応じて知性・速度・コストのバランスを調整できます。
Context Compaction(ベータ)
長時間のエージェント運用では、コンテキストウィンドウの上限に達する問題がありました。Context Compaction は、古い会話履歴を自動的に要約・圧縮することで、長時間のタスクをコンテキスト切れなしに継続させる仕組みです。

ベンチマーク
公式が強調している主な指標は以下の通りです。
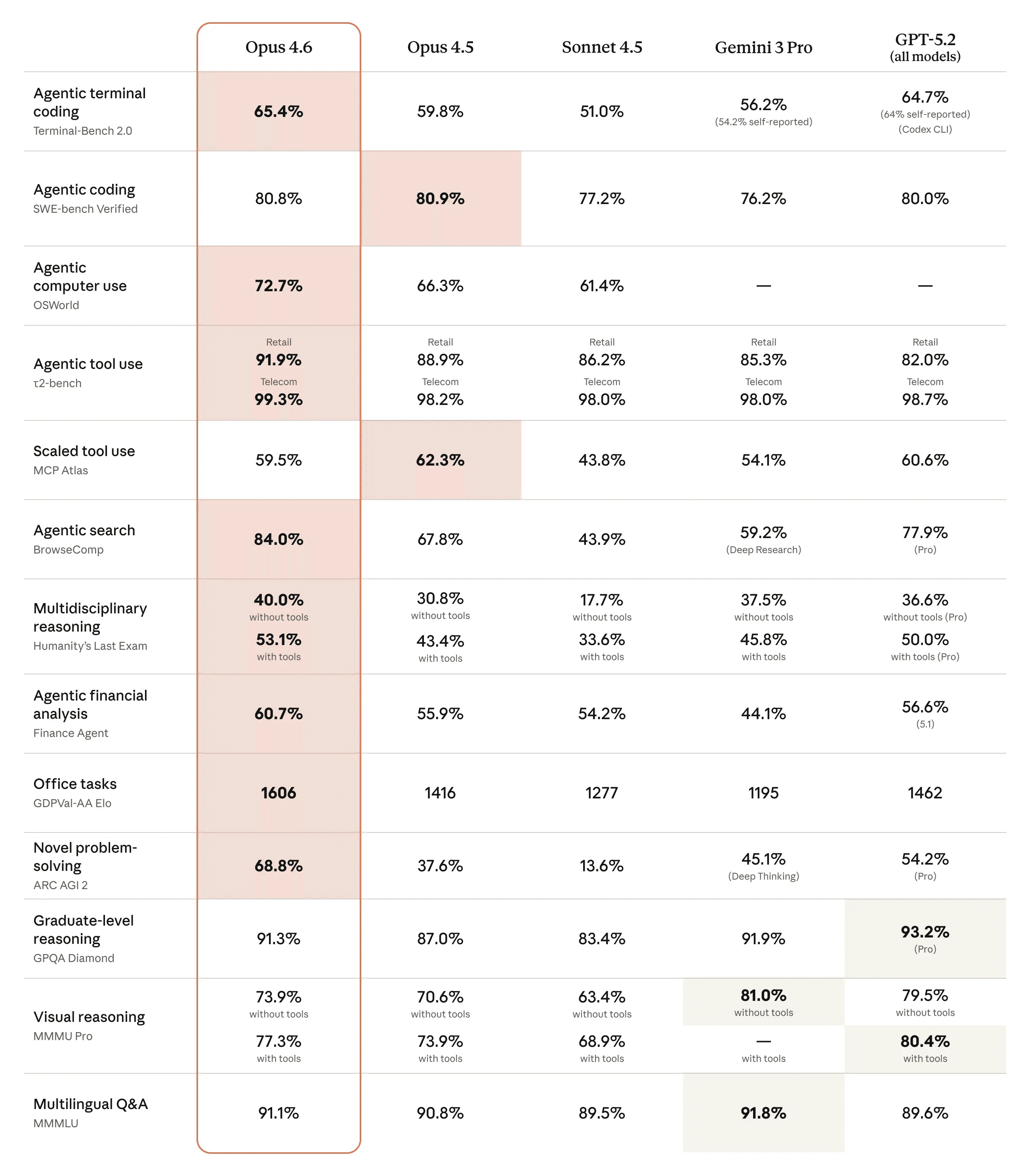
Terminal-Bench 2.0(エージェント的なターミナル操作):65.4%でAnthropicの発表時点では業界最高
OSWorld(OS操作タスク):72.7%
MRCR v2(8-needle 1M variant、長文脈検索):76%(Sonnet 4.5は18.5%)
GDPval-AA(実務系ナレッジワーク):GPT-5.2を約144 Elo、Opus 4.5を190 Elo上回る
Humanity's Last Exam(学際的推論):フロンティアモデル中で最高スコア
BrowseComp(情報検索):業界最高
BigLaw Bench(法律推論):90.2%(Harveyによる評価)
パートナー企業からの評価も紹介されています。
NorwayのNBIM(政府系投資基金のAI/ML部門)は、サイバーセキュリティ調査40件のうち38件でOpus 4.6が最良の結果を出したと報告。
Rakutenは、約50名・6リポジトリにまたがる組織をOpus 4.6が自律的にマネジメントし、プロダクトと組織の両面で意思決定を行いながら、人間にエスカレーションすべきタイミングも判断したとしています。
HarveyのClaude Opus 4.6は、法務ベンチマーク「BigLaw Bench」において、歴代のClaudeモデルで最高となる90.2%のスコアを記録しました。
完璧な回答が40%、スコア0.8以上が84%に達しており、法的推論において極めて高い能力を発揮しています。
(Harvey AIリサーチ責任者、Niko Grupen)
楽天におけるClaude Opus 4.6の活用では、1日で13件の課題を自律的に解決し、12件の課題を適切なチームメンバーに割り当てました。
約50人規模の組織、および6つのリポジトリにまたがる管理業務を遂行したことになります。
複数の領域にわたる文脈を統合しながら、プロダクト開発と組織運営の両面で意思決定を行い、さらには人間に判断を仰ぐべきタイミングも的確に判断していました。
(楽天 AIエグゼクティブ、Yusuke Kaji)

ベンチマークの数値はあくまで一面ですが、長文脈での情報劣化(いわゆる「context rot」)が大幅に減ったという点は、実務で扱うコードベースの規模を考えると大きな進歩と見られます。
安全性
Opus 4.6は、前モデルOpus 4.5と同等かそれ以上のアライメントを維持しているとされています。欺瞞、おべっか、ユーザーの妄想への同調、悪用への協力といった不整合行動の発生率が低く、加えて「過剰拒否」(無害な質問を拒否してしまう問題)が歴代Claudeモデルで最も少ないとのことです。
サイバーセキュリティ能力が向上したことに伴い、悪用を検知するための新しいプローブ(検出手法)が6種類追加されています。
提供形態と価格
利用可能な場所: claude.ai(Pro / Max / Team / Enterprise)、Anthropic API、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry
APIモデル名: `claude-opus-4-6`
価格: 入力 $5 / 出力 $25(100万トークンあたり)── 据え置き
200kトークン超の長文脈: 入力 $10 / 出力 $37.50(100万トークンあたり)
Prompt Caching: 最大90%割引
Batch API: 50%割引
US-only inference: 1.1倍の価格
なお、今回のリリースに合わせて Claude in Excel の大幅アップグレードと Claude in PowerPoint(research preview)も発表されています。ExcelではClaudeが事前に計画を立ててから実行する形になり、非構造化データの取り込みや複数ステップの変更を一度に処理できるようになりました。
PowerPointではテンプレートのレイアウト・フォント・スライドマスターを読み取って、ブランドを維持したままデッキを生成します。

GPT-5.3-Codex の概要
OpenAI側の目玉は GPT-5.3-Codex です。GPT-5.2-Codex(コーディング特化)とGPT-5.2(汎用推論)の知見を統合した上位モデルとして位置づけられています。

何が変わったか
一言でいえば、「コードを書くだけのエージェント」から「コンピュータ上でほぼ何でもこなすエージェント」への拡張です。
前世代比で 25%高速化 され、レイテンシが改善。調査、ツール操作、複雑な実行を含む長時間タスクへの対応力が強化されています。特徴的なのは、作業途中で人間が割り込んでステアリングできる「インタラクティブ」な設計です。文脈を失わずに、途中で質問やフィードバックを返せます。
もうひとつ注目すべき点として、GPT-5.3-Codexは自身のトレーニングにも使われた初めてのモデルです。OpenAIのCodexチームが、早期バージョンを使って自分自身のトレーニングのデバッグ、デプロイ管理、評価結果の診断を行ったとしています。
ベンチマーク
主な公式数値は以下の通りです。
SWE-Bench Pro(多言語ソフトウェアエンジニアリング):56.8%(xhigh設定)
Terminal-Bench 2.0:77.3% ── 他モデルを大きく上回り、かつトークン消費量も最少
OSWorld-Verified(デスクトップ操作):64.7%(GPT-5.2-Codexの38.2%から大幅向上)
GDPval(実務ナレッジワーク):70.9%のタスクで専門家と同等以上の成果
サイバーセキュリティCTF: 77.6%
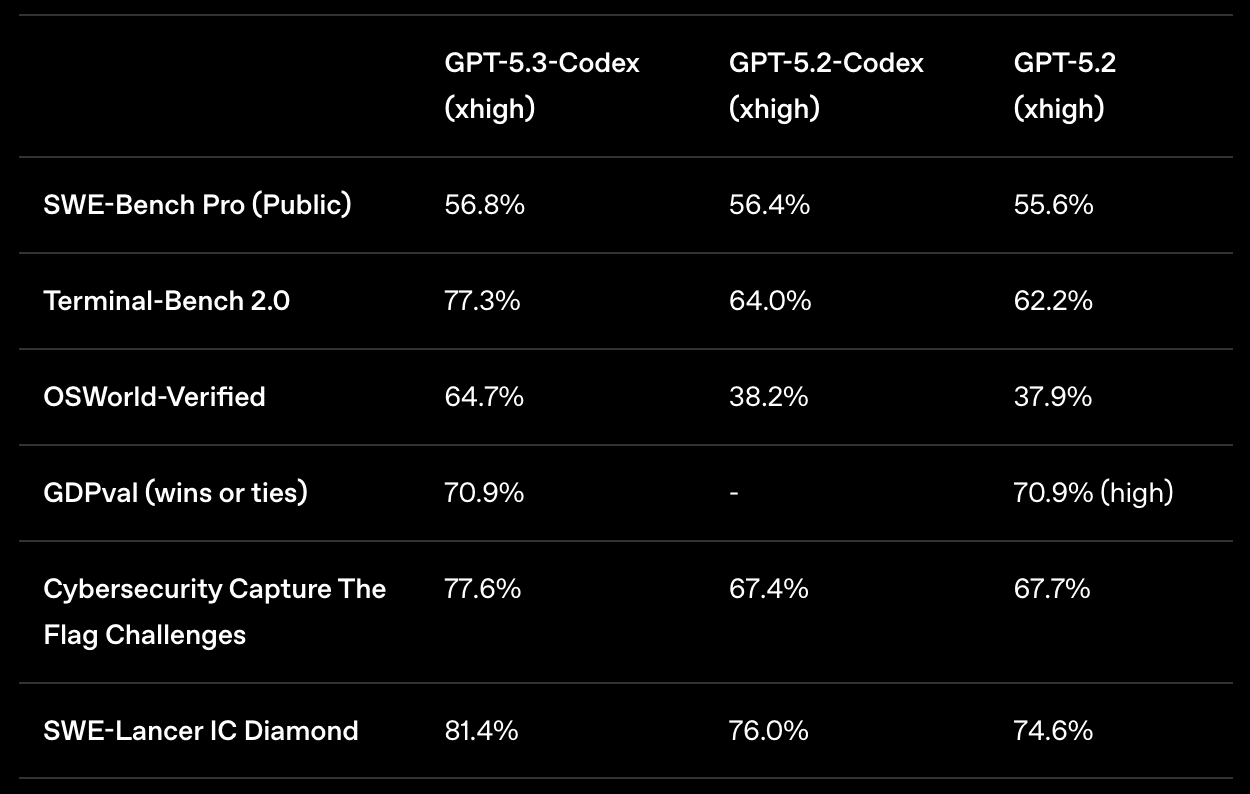
Terminal-Bench 2.0のスコア(77.3%)は、今回のOpus 4.6(65.4%)を上回っています。一方、SWE-Bench Proでは両者が拮抗しています。どちらが「上」というよりも、得意領域が異なるという印象です。
コーディング以外の実務能力
GPT-5.3-Codexは、コード生成にとどまらずソフトウェアライフサイクル全体をカバーする設計です。デバッグ、デプロイ、監視、PRD(製品要件定義書)作成、コピー編集、テスト、メトリクス分析まで対応するとしています。
GDPvalでは、44の職種にわたる実務タスク(プレゼンテーション作成、スプレッドシート処理など)で70.9%のタスクにおいて専門家と同等の成果を達成。
これはGPT-5.2もhigh設定で70.9%を達成しており同水準だが、GPT-5.3-Codexはxhigh設定での結果で、コーディング特化モデルがここまで汎用タスクにも対応できるようになったことを示しています。
プロンプト:あなたは高級ブティックのシニア・クライアント・アドバイザーです。この職務では、顧客へのアウトリーチ(働きかけ)を管理し、効果的なコミュニケーションを通じて来店予約を獲得する責任を担っています。
最近、店舗に新しいメンバーが加わりました。彼らは顧客にどのようなメッセージを送ればよいか、具体的な事例を必要としています。そこでマネージャーから、ある高級ファッションブランドの「2025年リゾートコレクション」を題材に、アウトリーチの設計をサポートしてほしいと依頼されました。
まず、あなたが選んだ2025年リゾートコレクションの中から、スタイリング済みのルックを4〜6スライドにまとめたPDFプレゼンテーションを作成してください。
(注:ここで言う「ルック」とは、特定のコレクションにおける、テーマの一貫性を持った服とアクセサリーのセットを指します。選択したブランドの公式サイトやルックブックを参考に、ルックを選定してください。)
次に、スタッフが顧客へ予約を促す際に使用できる、メールやテキストメッセージのテンプレートを作成してください。
このテンプレートはチーム内で共有され、今後のキャンペーンの参考資料として活用されます。
作成されたプレゼンテーション:

セキュリティへの取り組み
GPT-5.3-Codexは、OpenAIの Preparedness Framework においてサイバーセキュリティ関連タスクで「High capability」に分類された初のモデルです。脆弱性を特定するよう直接トレーニングされた初めてのモデルでもあります。
これに伴い、Trusted Access for Cyber というパイロットプログラムが同時発表されています。サイバー防御研究を加速させる取り組みで、オープンソースプロジェクトへの無料スキャン提供や、$10MのAPIクレジットによるサイバー防御支援も含まれています。
提供形態
利用可能な場所: Codexアプリ、CLI、IDE拡張、Web ── ChatGPTの有料プラン(Plus / Pro / Business / Enterprise / Edu)
期間限定: ChatGPT Free / Goユーザーにも一時的に開放。既存の有料プランはレートリミットを2倍に拡大
API: 「soon」(現時点では未提供)
ハードウェア: NVIDIA GB200 NVL72システムで学習・推論
API価格がまだ公表されていない点は、開発者にとって気になるところです。
Agent Teams(Claude Code)
今回のリリースで個人的に最も気になるのが、Claude Codeに追加された Agent Teams です。複数のClaude Codeインスタンスをチームとして並列に動かし、自律的に協調させる仕組みです。
仕組み
Agent Teamsは、1つのセッションを「チームリード」として、そこから「チームメイト」と呼ばれる複数のエージェントを立ち上げます。各チームメイトは独自のコンテキストウィンドウを持ち、独立して作業しつつ、相互にメッセージをやり取りできます。
従来のサブエージェント(subagents)との違いは明確です。サブエージェントはメインエージェントへの報告のみでしたが、Agent Teamsではチームメイト同士が直接コミュニケーションを取れます。共有タスクリストで作業を分担し、依存関係の管理も自動化されています。
サブエージェント は、結果だけが必要な集中タスク向き。各サブエージェントは独自のコンテキストを持ちますが、メインへの報告のみで、相互通信はできません。トークンコストは比較的低め。
Agent Teams は、議論・協調が必要な複雑な作業向き。各チームメイトが完全に独立したインスタンスとして動き、チームメイト同士で直接メッセージをやり取りできます。そのぶんトークンコストは高くなります。
得意なユースケース
公式ドキュメントが推奨するのは、並列に探索することで価値が出るタスクです。
リサーチ・レビュー: 複数の観点から同時に調査し、互いの知見を共有・反論する
新機能の並行実装: フロントエンド、バックエンド、テストを別々のチームメイトに任せる
仮説検証のデバッグ: 複数の仮説を並行でテストし、「科学的な議論」のように互いの仮説を崩し合う
コードレビュー: セキュリティ、パフォーマンス、テストカバレッジの3観点を同時にレビュー
操作方法
表示モードは2つ。in-process はメインターミナル内でShift+Up/Downでチームメイトを切り替える方式。split panes はtmuxまたはiTerm2で各チームメイトを別ペインに表示します。
リードに「プラン承認を必須にして」と指示すれば、チームメイトは実装前にプランを提出し、リードの承認を待ちます。さらに delegate mode(Shift+Tab)に切り替えると、リードはコードに一切触れず、オーケストレーションに専念します。
注意点
Agent Teamsはresearch previewであり、デフォルトでは無効です。有効化には `CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS=1` の設定が必要です。
トークン消費は単一セッションよりも大幅に増えます。各チームメイトが独立したClaude Codeインスタンスとして動くためです。また、セッション復旧(`/resume`)ではin-processのチームメイトが復元されない、チームメイトがタスクの完了マークをしないことがあり、依存タスクがブロックされる場合がある、といった既知の制限もあります。
それでも、コードレビューや調査系タスクでの並列実行は、これまで手動でターミナルを複数開いてやっていた作業の自動化として魅力的です。
両社の発表を俯瞰して
コーディングエージェントからナレッジワーク・プラットフォームへ
今回の同日発表で最も注目すべきは、コーディングエージェントが「コードを書くだけ」の存在から、より広範なナレッジワーク全般をカバーする方向に進化しつつあるという構造的な変化です。
Anthropicは、Claude CodeをベースにしたCoworkで、非エンジニアも含めたナレッジワーカー向けに「リサーチ+文書作成+メール送信を並列で」といった体験を提供し始めています。OpenAIも、Codexデスクトップアプリで同じ方向に踏み出しました。Skills、Automations、GDPvalでの知識労働タスク対応を前面に出しています。
さらにOpenAIは同日、エンタープライズ向けの新プラットフォーム OpenAI Frontier も発表しました。
AIエージェントを「AIコワーカー」として企業内に展開・管理するための基盤で、社内のCRM、チケット管理、データウェアハウスなどを横断的に接続し、エージェントにビジネスコンテキストを与えて実務を遂行させる設計です。
HP、Intuit、Oracle、State Farm、Uber、Thermo Fisherが初期導入企業として名を連ねています。OpenAIのForward Deployed Engineers(FDE)がクライアント企業に入って共同で構築するハンズオン体制も特徴的で、「コーディングエージェント」の枠を超え、組織全体のナレッジワークインフラとしてAIエージェントを位置づける動きが鮮明になっています。
モデル自体の傾向も同様です。Every.toのVibe Checkでは「OpusがCodex寄りに(長時間タスクへの粘り強さ向上)、CodexがOpus寄りに(速度・親しみやすさ向上)」と評され、"The Great Convergence"(大収束)と見出しが付けられています。
モデルが自身を進化させる時代
もうひとつ見逃せないのは、モデル自身がモデルの進化に関与し始めたという点です。
OpenAIは公式に、GPT-5.3-Codexが「自身のトレーニングにも使われた初めてのモデル」であると明言しています。早期バージョンを使ってトレーニングのデバッグ、デプロイ管理、テスト結果の診断を行ったとしており、AIの自己改善ループが実用段階に入りつつあることを示唆しています。
GPT-5.3-Codexは、自分自身の構築において極めて重要な役割を果たした、当社初となるモデルです。
Codexチームは、開発の初期段階からこのモデル自身を活用して、トレーニング中のデバッグ、デプロイの管理、さらにはテスト結果や評価の分析までを行いました。
Codexが自らの開発スピードをこれほどまでに加速させたという事実に、開発チーム一同、大きな衝撃を受けています。

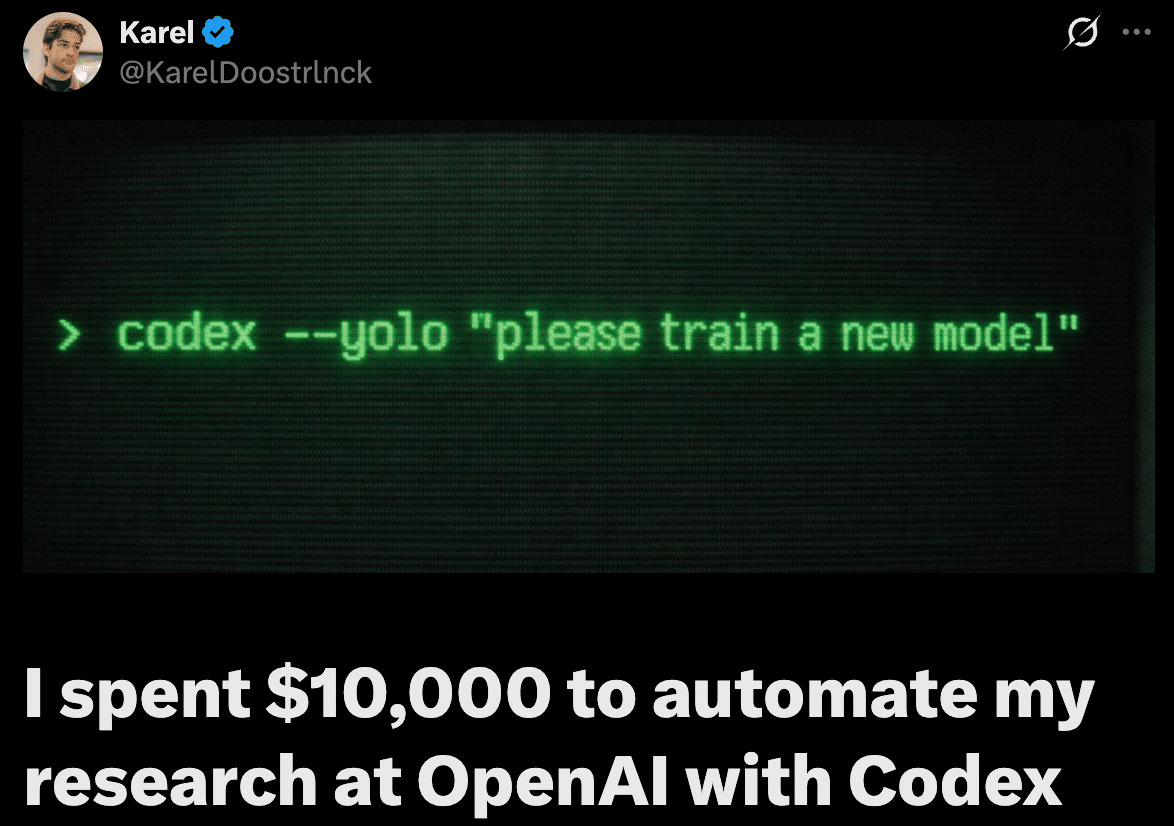
OpenAIの研究者Karel Doostrlnck氏は、Codexに月額$10,000を費やして自身の研究を自動化していると公開しています。Slackチャンネルやコードベースを横断的にクロールして700以上の検証可能な仮説を自動生成させたり、複数のサブエージェントを束ねて調査・コード生成・データ分析を並列実行させたりと、「1人の研究者+エージェント群」で組織横断的なナレッジ統合を実現している事例です。
OpenAIのCodexを使って、自分の研究を自動化するために1万ドルを費やした
またOpenAIはGinkgo Bioworksと共同で、GPT-5を自律型ラボに接続し、実験の設計→実行→結果分析→次の実験設計というループを6回繰り返すことで、タンパク質生産コストを40%削減したと発表しています。36,000以上の反応組成を探索し、人間が試していなかった低コストな組み合わせを発見したとのことで、AIの自律的な研究サイクルが具体的な成果を出し始めています。
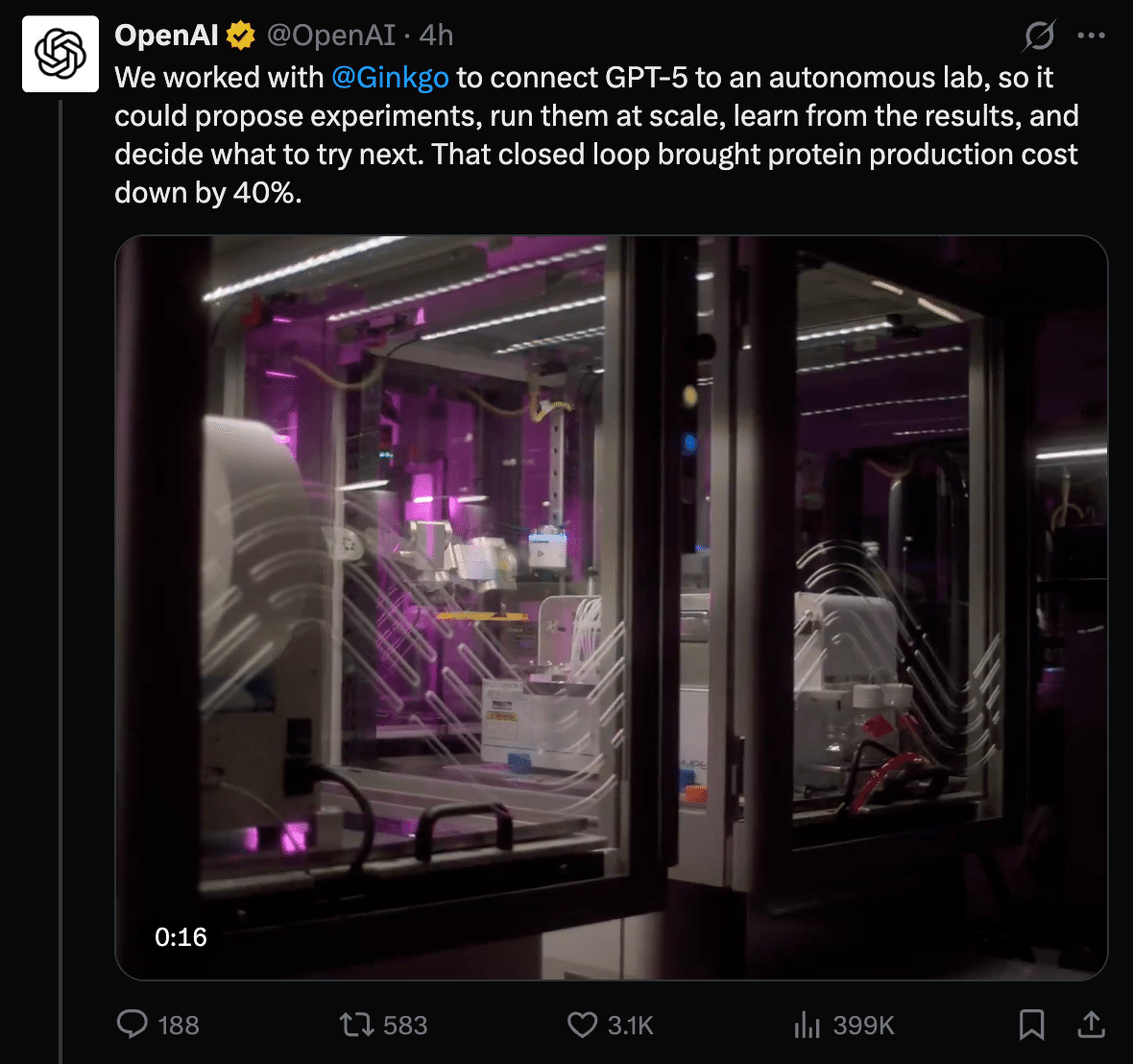
私たちは Ginkgo Bioworks と協力し、GPT-5 を自律型ラボに接続しました。これにより、AIが自ら実験を提案・大規模に実行し、その結果から学んで次の試行を決定できるようになりました。この一連のクローズドループ(自動循環)によって、タンパク質の生産コストを40%削減することに成功しました。
Anthropic側でも、セーフガードチームの研究者Nicholas Carlini氏がOpus 4.6のAgent Teamsを使い、16のエージェントを並列で動かしてRustベースのCコンパイラをほぼ自律的に構築する実験を公開しています。約2,000セッション・$20,000のAPIコストで、Linuxカーネルをコンパイルできる10万行のコンパイラが生成されました。完全な代替にはまだ至らないものの、「人間はテストハーネスの設計に集中し、実装はエージェント群に任せる」というワークフローの可能性を示す事例です。

私たちは、エージェント・チームを組んだOpus 4.6に対し、Cコンパイラの構築を命じ、その後は(ほぼ)彼らに任せてみました。自律的なソフトウェア開発の未来について、今回の試みから得られた知見を紹介します。
得意領域の差は残っています。Terminal-Bench 2.0ではCodexが優位(77.3% vs 65.4%)。長文脈検索(MRCR v2)ではOpus 4.6が76%を記録し、Sonnet 4.5(18.5%)を大きく上回っています。
どちらが「上」かという比較よりも、コーディングエージェントがナレッジワーク全体のプラットフォームへと変わりつつあること、そしてモデルが自身の進化を加速させ始めたこと。この2つが、今回の同日発表から読み取れる本質だと感じます。





