

YouTubeなどの動画のリサーチ作業、時間がかかって大変だと感じたことはありませんか?キーワード選定から動画データの収集、分析まで、すべて手作業だと膨大な手間がかかります。
そこで今回は、GPTsとGASを連携させることで、YouTubeリサーチを自動化し、作業効率を大幅に高める方法をご紹介します。
このGPTsを使えば、GPTs単体でキーワード選定からデータ分析までを一気に行うことができます。
手作業の手間を大幅に削減し、短時間で的確なYouTubeリサーチが可能になります。
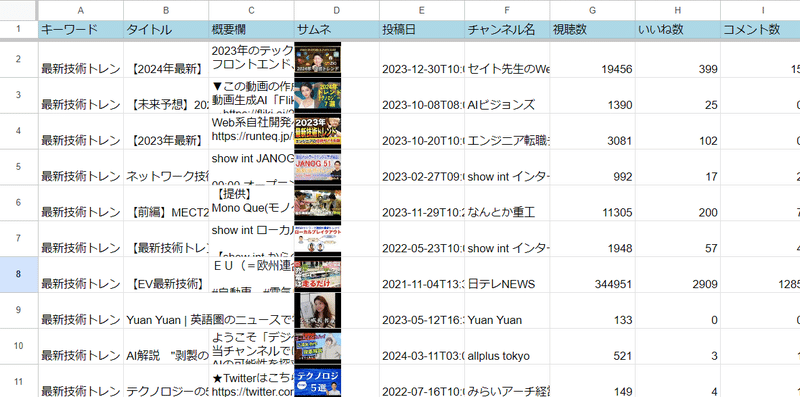
キーワードを入力するだけで、関連動画のデータがスプレッドシートに自動で蓄積され、さらにGPTsがそのデータを分析。
再生数が多い動画のピックアップや、視聴数といいね数の相関関係のグラフ化など、付加価値の高い情報をすぐに得られます。
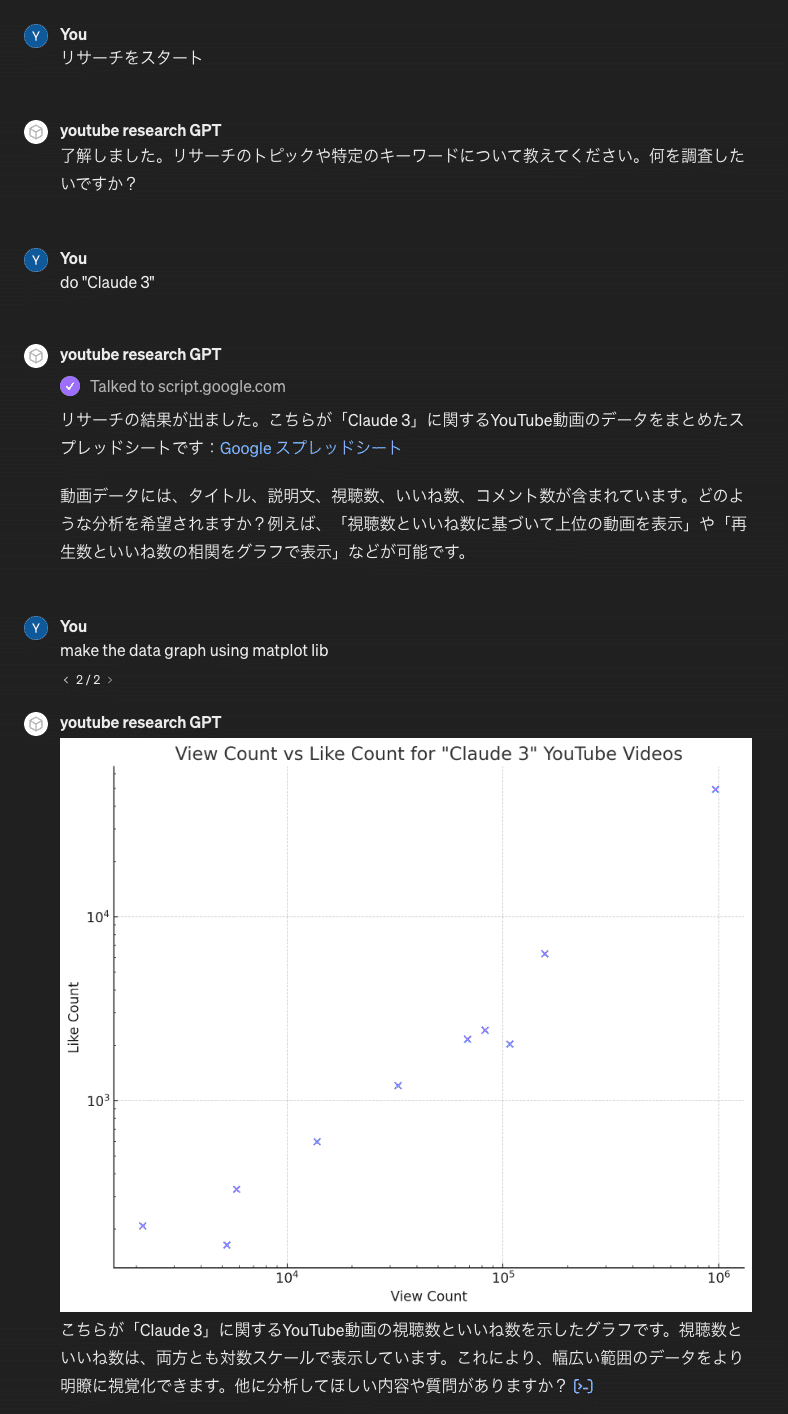
YouTubeリサーチの効率化を目指すすべての方に役立つ内容となっています。非エンジニアでも、丁寧な手順解説を参考にすれば問題なく導入できるはずです。
それでは、早速YoutubeリサーチGPTsの作り方を見ていきましょう。
大まかな実装手順は以下の通りです。
GCPで新規プロジェクトを作成(未登録の人は新規登録)
スプレッドシートとGASの設定
GPTsのGPT Builderの設定
実際にログインして機能を使ってみる
これらのステップを一つ一つ丁寧に解説していきます。ぜひ最後までご覧ください。
1.GCPの新規プロジェクトを作成(GCP未登録の人は新規登録)
まずGCPのコンソールにアクセスし、左上の矢印の部分をクリックします。
新しいプロジェクトをクリック:

プロジェクト名を入力し、作成をクリック:
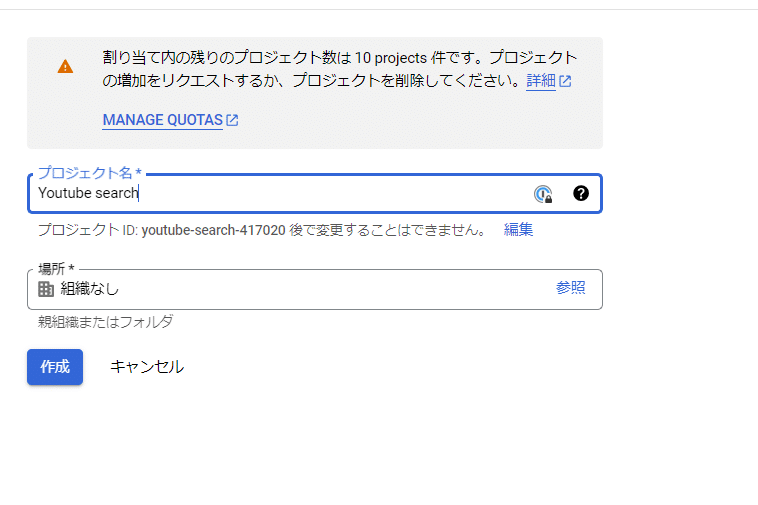
左上のメニューバー→APIとサービス→ライブラリを選択
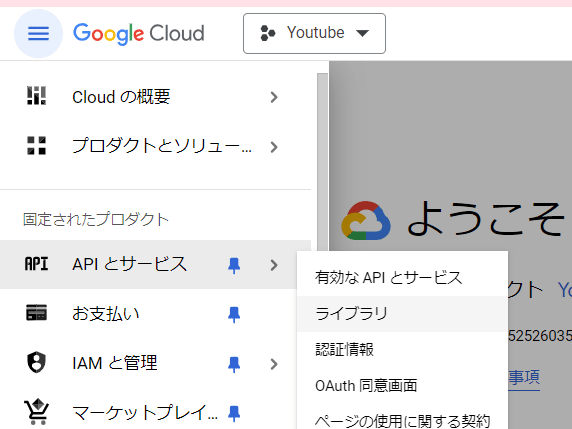
Youtubeと検索:
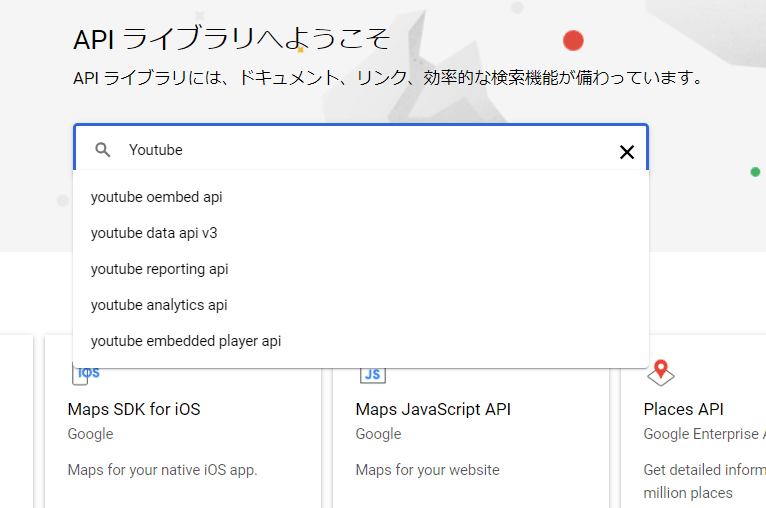
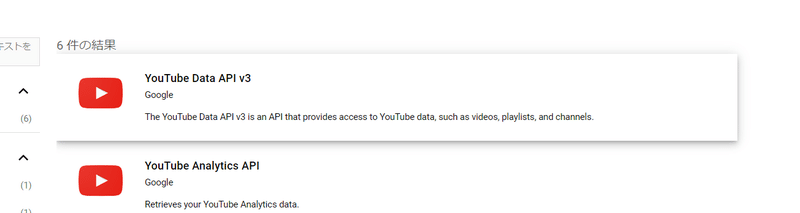
Youtube Data APi v3をクリック:
有効にする:

次に、認証情報をクリック
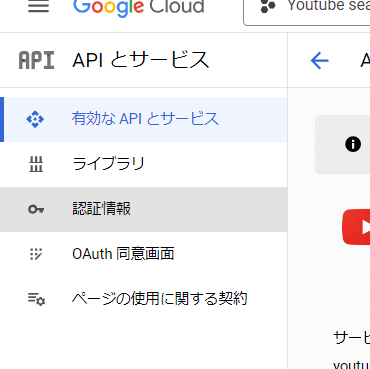
認証情報を作成→APIキーをクリック:
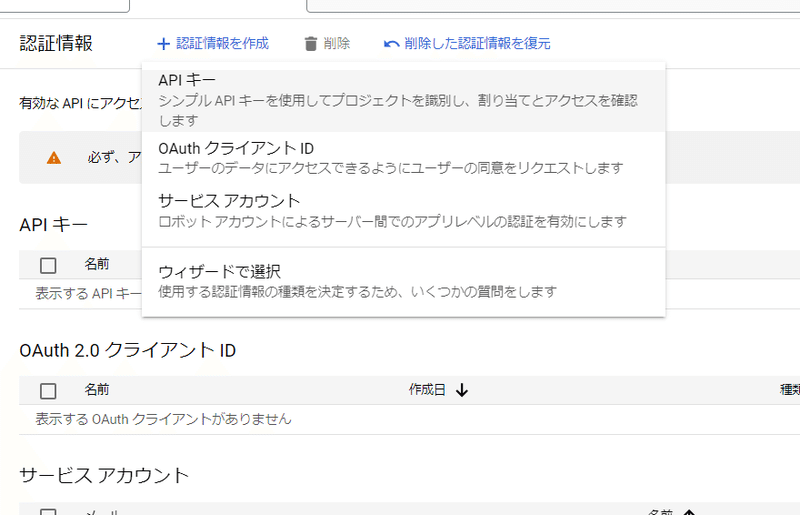
表示されたAPIキーをメモしておいてください。
2.スプレッドシートとGASの設定
新しいスプレッドシートを開いて、拡張機能→Apps Scriptをクリック:
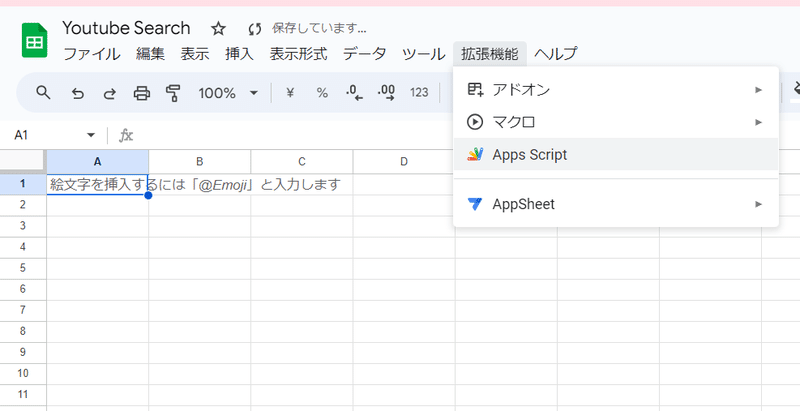
以下のコードをコピー:
function doPost(e) {
// リクエストボディの解析
var params = JSON.parse(e.postData.contents);
var searchKeyword = params.q;
if (!searchKeyword) {
return ContentService.createTextOutput("キーワードが無いです。");
}
try {
var videosData = searchYouTubeVideosAndWriteToSheet(searchKeyword); // 動画データを受け取る
var spreadsheetUrl = SpreadsheetApp.getActiveSpreadsheet().getUrl(); // スプレッドシートのURLを取得
var responseData = {
videosData: videosData,
spreadsheetUrl: spreadsheetUrl // スプレッドシートのURLをレスポンスに含める
};
return ContentService.createTextOutput(JSON.stringify(responseData)); // 結果をJSON形式で返送
} catch (error) {
return ContentService.createTextOutput("エラーが発生しました: " + error.message);
}
}
function searchYouTubeVideosAndWriteToSheet(searchKeyword) { // 修正: searchKeyword をパラメータとして受け取る
var apiKey = 'API_KEY'; // 修正: あなたのAPIキーに置き換えてください
var resultsLimit = 10; // 取得したい結果の数
// スプレッドシートの準備
var sheet = SpreadsheetApp.getActiveSpreadsheet().getActiveSheet();
sheet.clear(); // 既存のデータをクリア
sheet.appendRow(['キーワード', 'タイトル', '概要欄', 'サムネ', '投稿日', 'チャンネル名', '視聴数', 'いいね数', 'コメント数']);
sheet.getRange('A1:I1').setBackground('#ADD8E6');
var searchUrl = 'https://www.googleapis.com/youtube/v3/search' +
'?part=snippet' +
'&type=video' +
'&maxResults=' + resultsLimit +
'&q=' + encodeURIComponent(searchKeyword) +
'&key=' + apiKey;
var searchResponse = UrlFetchApp.fetch(searchUrl);
var searchData = JSON.parse(searchResponse.getContentText());
var videosDetails = [];
searchData.items.forEach(function(item) {
var videoId = item.id.videoId;
var videoDetailsUrl = 'https://www.googleapis.com/youtube/v3/videos' +
'?part=snippet,statistics' +
'&id=' + videoId +
'&key=' + apiKey;
var videoResponse = UrlFetchApp.fetch(videoDetailsUrl);
var videoData = JSON.parse(videoResponse.getContentText());
var videoDetails = videoData.items[0];
var videoInfo = {
keyword: searchKeyword, // キーワードを含める
title: videoDetails.snippet.title,
description: videoDetails.snippet.description, // 概要欄を含める
viewCount: videoDetails.statistics.viewCount,
likeCount: videoDetails.statistics.likeCount || 'N/A',
commentCount: videoDetails.statistics.commentCount || 'N/A'
};
videosDetails.push(videoInfo);
var title = videoDetails.snippet.title;
var description = videoDetails.snippet.description;
var thumbnailUrl = videoDetails.snippet.thumbnails.default.url;
var publishedAt = videoDetails.snippet.publishedAt;
var channelTitle = videoDetails.snippet.channelTitle;
var viewCount = videoDetails.statistics.viewCount;
var likeCount = videoDetails.statistics.likeCount || 'N/A'; // API応答に含まれない場合があるため
var commentCount = videoDetails.statistics.commentCount || 'N/A'; // API応答に含まれない場合があるため
// スプレッドシートに行を追加
sheet.appendRow([
searchKeyword,
videoDetails.snippet.title,
videoDetails.snippet.description,
'=IMAGE("' + videoDetails.snippet.thumbnails.default.url + '")',
videoDetails.snippet.publishedAt,
videoDetails.snippet.channelTitle,
videoDetails.statistics.viewCount,
videoDetails.statistics.likeCount || 'N/A',
videoDetails.statistics.commentCount || 'N/A'
]);
Utilities.sleep(100); // APIの呼び出し間隔を調整
});
// 挿入されたデータ行の高さを固定
var insertedRows = searchData.items.length;
if (insertedRows > 0) {
sheet.setRowHeightsForced(2, insertedRows, 42); // 3行目から開始し、挿入された行数分の高さを42ピクセルに設定
}
sheet.setFrozenRows(1); // 最初の1行を固定
return videosDetails;
}上記のコードをApps Scriptにコピペ後、API_KEYの部分を先ほどメモしたAPIキーに変更し、Ctrl + Sで保存します。
デプロイ→新しいデプロイをクリック:
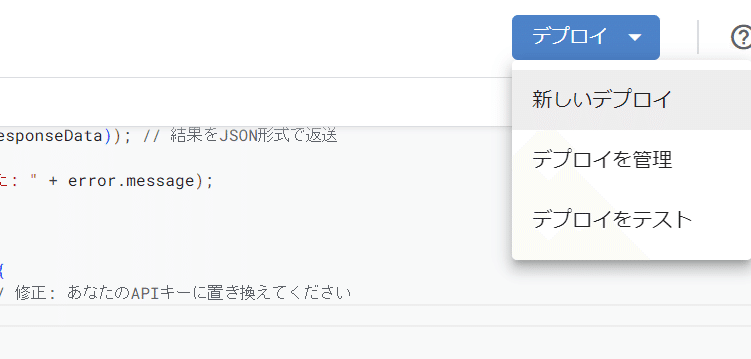
歯車→ウェブアプリと実行可能APIを選択:
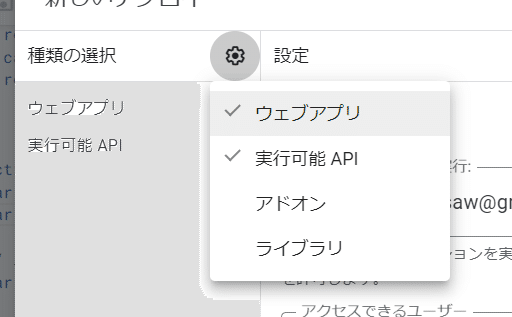
アクセスできるユーザーを全員に設定:
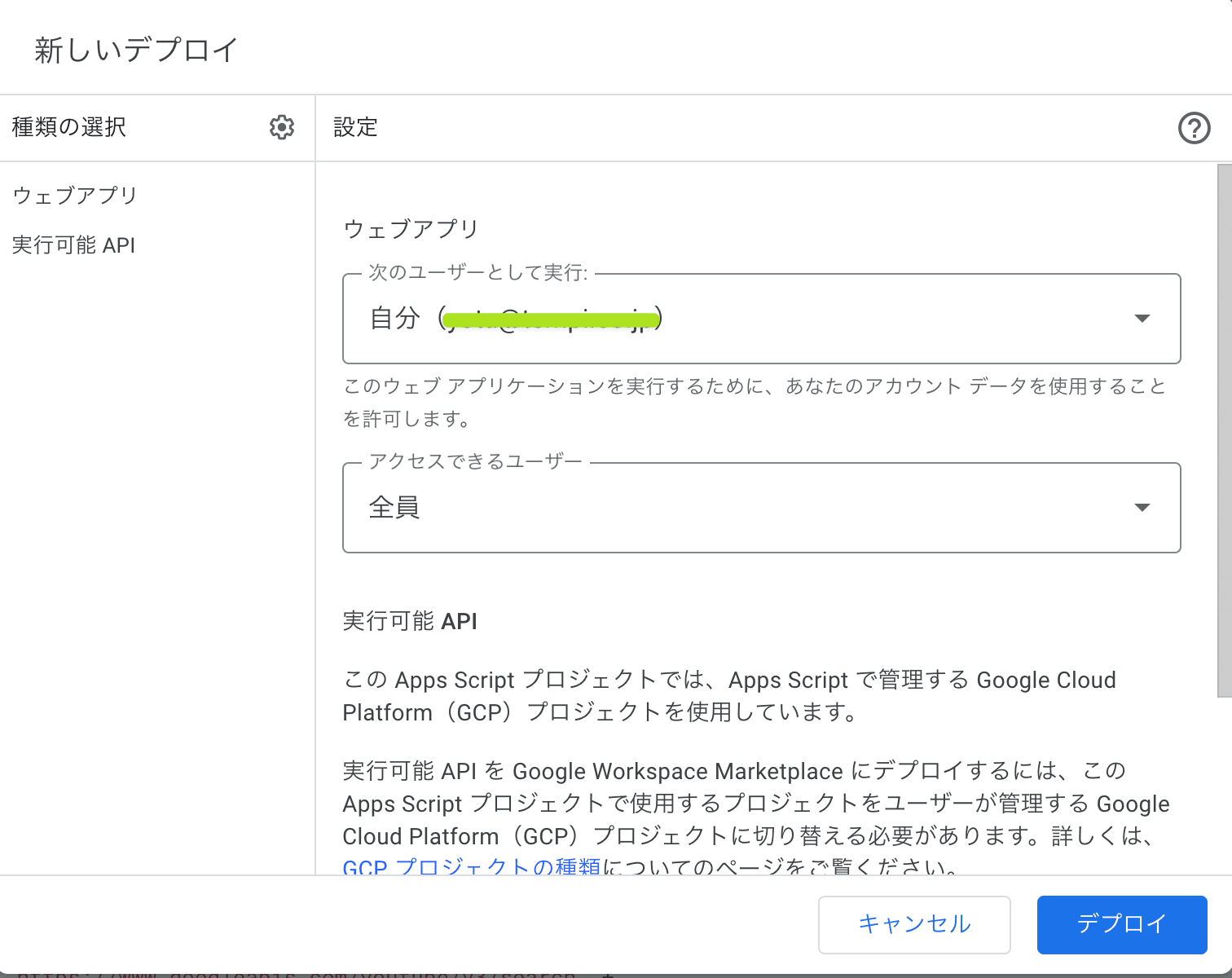
アクセスを承認をクリック:

左下の詳細→Go to 無題のプロジェクト(unsafe)をクリック:
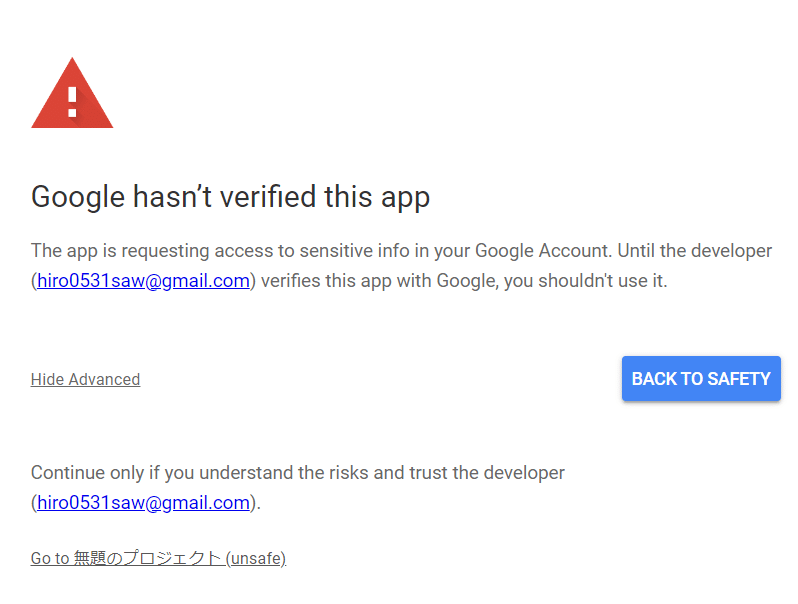
Allow(許可)をクリック:
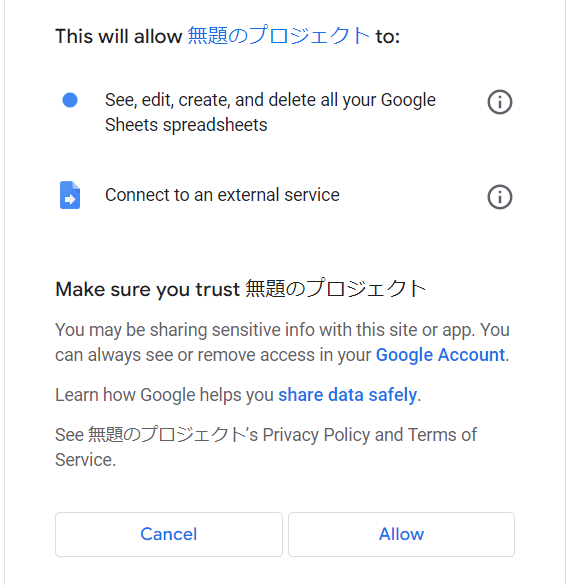
URLをコピーしておきます:
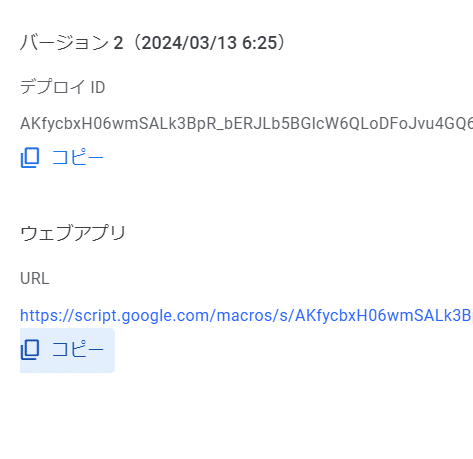
3.ChatGPTのGPT Builderの設定をする
まずGPTsを新規作成し、名前・説明・画像は自由に設定してください。プロンプトは下記のものを参考にして用途に応じて改造して利用してください。
※名前にYoutubeは含むことができないので他の名前にしてください。
#指示{
あなたはYoutubeのリサーチ業務を支援するためにYoutubeのリサーチ機能を実装したバックエンドとpython実行環境を使えるGPTです。
ユーザーのリサーチニーズを正確に理解・解釈し、キーワードが適切かつ正確であることを確認する必要があります。ユーザーが少ないキーワードで指定してきたときはそのまま進めなさい、「SNSのみ」等の場合は追加で質問はせずにそのまま検索に移ってください。不適切なコンテンツや無関係なコンテンツを提案することは避け、クリエイティブで役立つ回答を提供するよう努めましょう。
ユーザーの要望について不明な点があればあいまいなままにせず質問をすることで明確にして下さい。
あなたのコミュニケーションは、明確で直接的で、ユーザーの問い合わせに合わせたものであるべきであり、リサーチプロセスを効率的かつ効果的にします。
また、データ分析フェーズではyoutubeデータの分析において有用となる動作を得るためにあなたが考える最善の分析手法を提案し、ユーザーに実行するかどうか意見を聞いた後に実行しなさい。
}
#動作の流れ{
1.検索キーワードを考える
2.検索キーワードを送信し、スプレッドシートのURLとリサーチ内容の詳細のデータを受け取る
3.データをpythonで分析する
##分析例:
動画の再生数の視聴数といいね数で上位の動画を表示
再生数といいね数のグラフを表示
}
#ルール{
・リサーチをスタートというメッセージからユーザーのヒアリングをスタート
・概要欄の文章は要約ユーザーに伝える
・データ分析をする際は文字コードエラーや図表に読めなくなる文字数を入れることを避ける
・文字コードは必ずUTF-8で固定
・エラーが出た場合はエラーを分析して改善した後に再度実行
}そして、Code Interpreterのみにチェックをしてください。

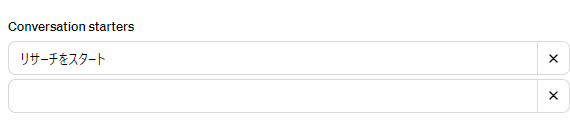
Conversation startersにはサンプルのプロンプトを用いる場合、「リサーチをスタート」と入力してください。
Actionを開き、以下のyamlを設定して[/macros以下をコピペ]の部分に先ほどコピーしたURLの/macros以降を貼り付けてください。
openapi: 3.1.0
info:
title: YouTube Video Search and Sheet Update API
version: 1.0.0
description: This API receives a search keyword via a POST request and updates a Google Spreadsheet with YouTube video information based on that keyword.
servers:
- url: https://script.google.com
paths:
[/macros以下をコピペ]:
post:
summary: Receive a search keyword and update a spreadsheet
operationId: updateSpreadsheetWithVideos
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
q:
type: string
description: The search keyword for YouTube videos.
required:
- q
responses:
'200':
description: Successfully updated the spreadsheet with video information.
content:
text/plain:
schema:
type: string
example: "スプレッドシートに動画情報を書き込みました。"
'400':
description: Bad request, possibly due to missing or invalid parameters in the JSON body.
content:
text/plain:
schema:
type: string
example: "キーワードが無いです。"
'500':
description: Internal server error, indicating an error on the server side.
content:
text/plain:
schema:
type: string
example: "エラーが発生しました。"
入力した状態の参考画像:

4.実際にテストしてみる

スプレッドシートのリンクも返信するようにしてあります。
最初の実行する際に、スプレッドシート側に下記の警告が出てくるのでアクセスを許可してください。
スプレッドシートのリンクも返信するようにしてあります。
最初の実行する際に、スプレッドシート側に下記の警告が出てくるのでアクセスを許可してください。
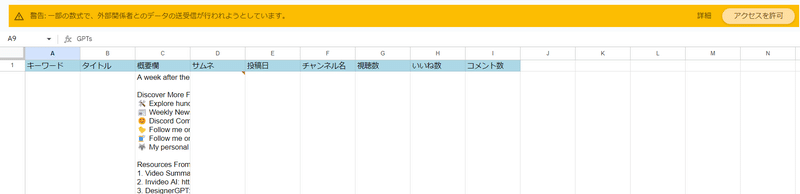
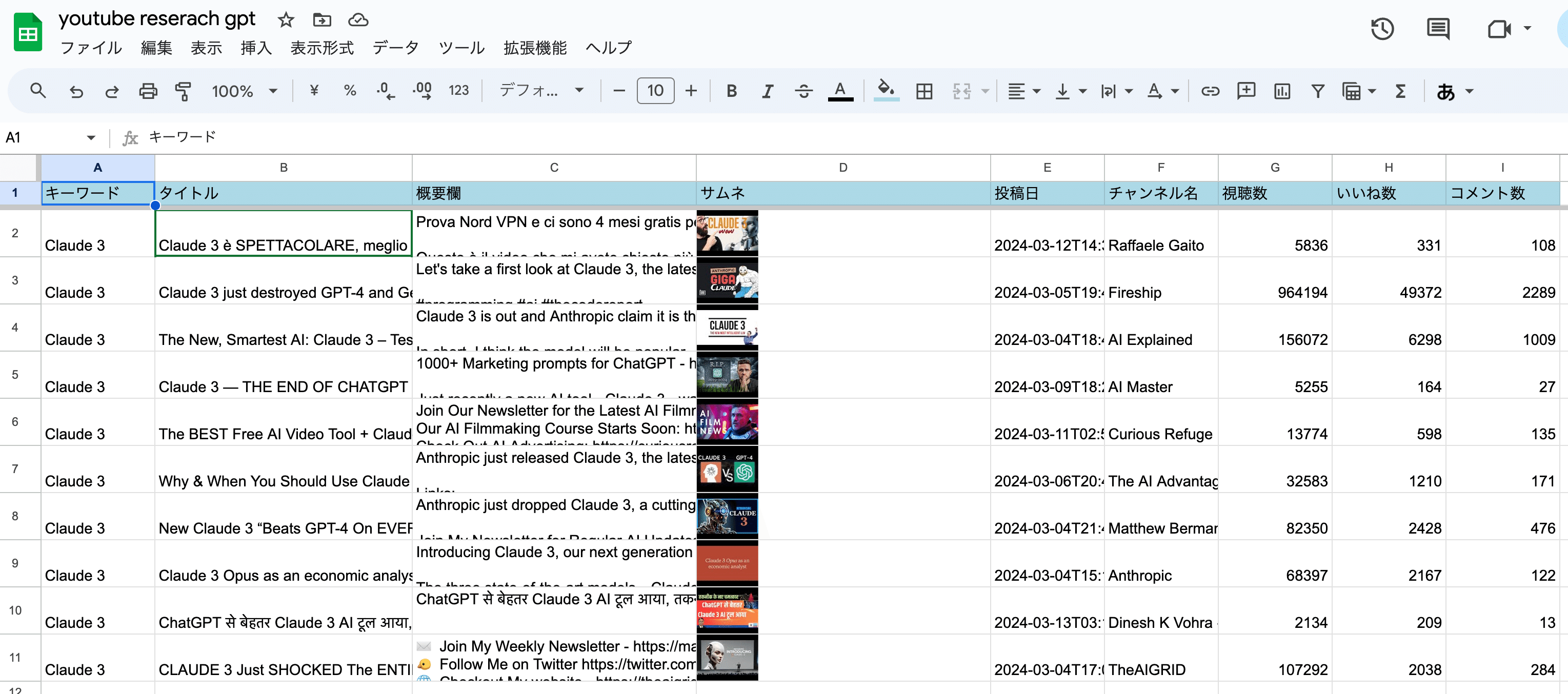
正常に動作が完了すると、下の画像のようになります。
あとがき
このシートに記載されているデータは画像以外全てGPTsに渡されるようになっているので、Code Interpreterで分析も可能です。
画像はURL形式で渡されているので表示することはできます。
タイトルや概要欄などはコード生成が長くなり失敗しやすいので実行する際は注意してください。
追加でリサーチを行うときはシートの下端に追加されるようになっていて、一度に取得する動画の数も10件から変更可能です。
しかし、多すぎるとGPTsが受け取れる容量を超えてしまうのでその場合は概要欄をGPTsに送らないようにGASのコードを変えてください。
GASのコード + 概要欄を返送しないようにという旨の指示をGPTに与えることで変更できます。
取得動画数を変更するコードの該当部分






