

今週のAI業界は、まさに激動の一週間となりました。
年間を通しても稀に見るほどの大型発表が相次ぎ、2週間前にOpenAIの「Codex」登場で沸いた興奮が冷めやらぬうちに、業界の景色は瞬く間に塗り替えられたと言っても過言ではないでしょう。
あまりのスピードで進化と変革が続くため、「最新情報を追いきれない」と感じている方も少なくないのではないでしょうか。
そんな方に向けて、この怒涛の1週間における主要なAIニュースとそのポイントを、カテゴリーごとに分かりやすく整理してお届けします。それでは、早速見ていきましょう!
今週のハイライト
今週のAI業界は、まさに大型発表のラッシュでした。Google I/O 2025では、AIモデル「Gemini」群が大きく進化。検索機能には待望の「AI Mode」が導入され、3Dビデオ通話「Google Beam」といった新サービスも多数登場しています。
続くMicrosoft Build 2025。GitHub Copilotは、自律的な「コーディングエージェント」への進化が強調されました。企業向けカスタマイズ機能「Copilot Tuning」、AIエージェント開発基盤「Azure AI Foundry」の強化も大きな発表です。
そしてAnthropicからは、遂に次世代AIモデル「Claude 4 Opus/Sonnet」が登場。コーディング能力や高度な推論能力の向上を強くアピールし、開発者向けの新API群やAIコーディング支援ツール「Claude Code」も公開されました。
AIの自律性とパーソナライゼーションは一層進み、開発者エコシステムも拡大しています。
1. 大手AI企業の製品・サービス更新
マイクロソフト、気象予測の枠を超えるAI基盤モデル「Aurora」発表。多様な環境事象を高精度・高速に予測可能に
マイクロソフトリサーチが、AI基盤モデル「Aurora」を開発しました。このモデルは、従来の気象予測の範囲を超え、ハリケーンや大気の質、さらには海洋波といった多様な環境事象を、より高い精度かつ迅速に予測できます。Auroraは100万時間を超える膨大な大気関連データで訓練されており、既存の数値予報やAIアプローチと比較して優れた性能と低い計算コストを実現しています。

主な特徴とポイント:
広範な予測能力: 天気予報だけでなく、大気汚染、海洋波、熱帯低気圧など、様々な環境現象に対応。
高精度・高速処理: 既存の数値予報やAIモデルと比較し、91%の予測目標で優位性を示し、計算コストも大幅に削減。
大規模データで学習: 衛星、レーダー、気象観測所などから集めた100万時間以上の多様な大気データでAIを訓練。
ファインチューニングで特化: 基礎学習後、少量の追加データを用いることで、特定の予測タスクに合わせた調整が可能。
オープンソースとして公開: ソースコードとモデルの重みを公開し、技術革新を促進。MSN天気予報にも既に導入済み。
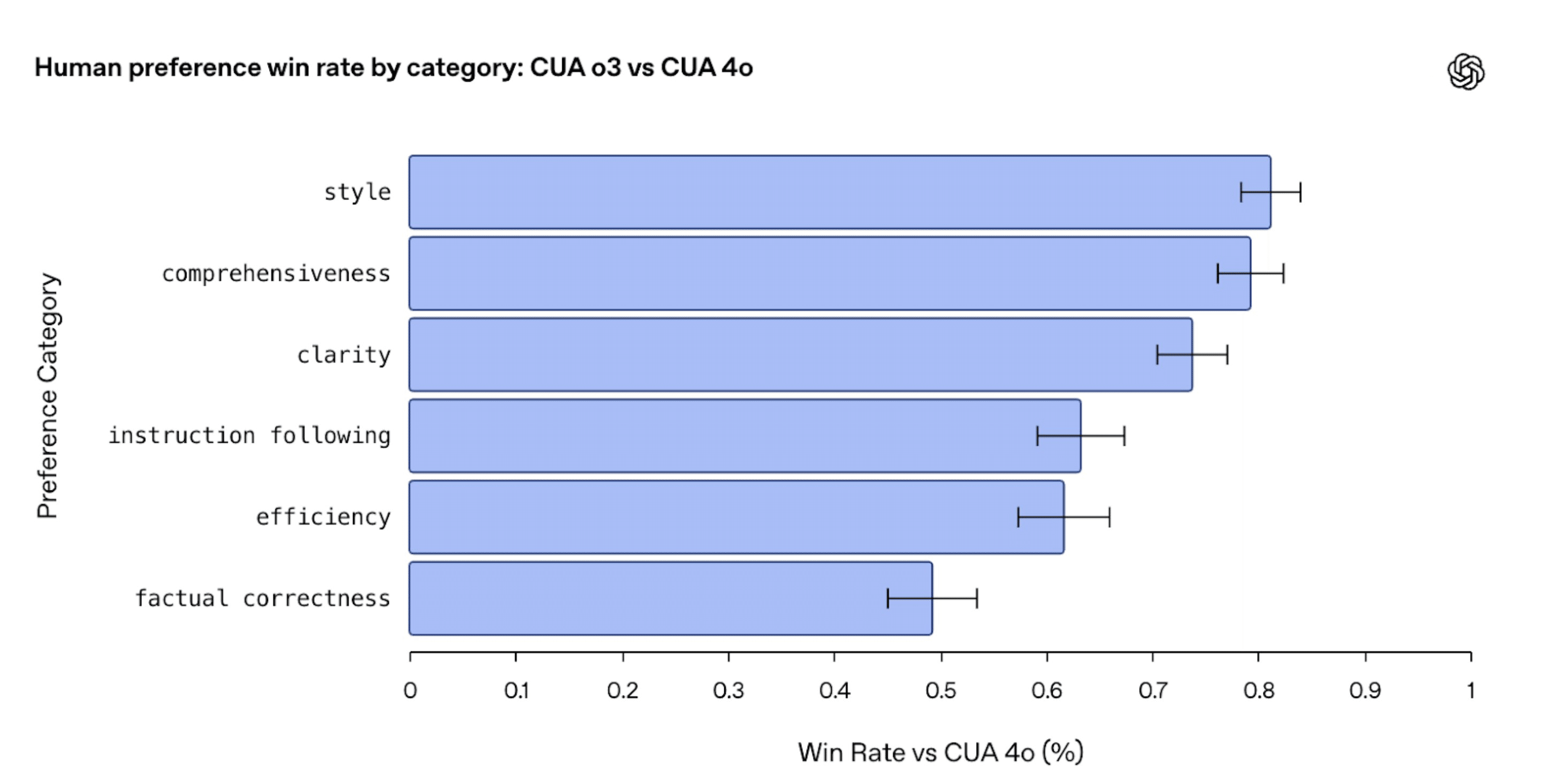
OpenAI、エージェントモデル「Operator」をo3ベースに更新。コンピュータ操作の安全性と能力を向上
OpenAIは、ユーザーに代わってウェブブラウザを操作しタスクを実行するエージェントモデル「Operator」について、その基盤モデルを従来のGPT-4oベースから新しいOpenAI o3ベースへと更新しました。今回の更新により、特にコンピュータを使用する際の安全性と判断能力が強化されています。
https://twitter.com/ctgptlb/status/1926069361447473552
主な特徴とポイント:
o3モデルへ移行: Operatorの頭脳となるモデルをGPT-4oからOpenAI o3に変更。ただしAPI版は4oベースを維持。
コンピュータ操作に特化した安全性: 新しいo3 Operatorは、コンピュータ利用時の判断基準や拒否すべき操作を学習させるための専用データで追加学習済み。
多層的な安全対策: 従来の4o版Operatorで採用されていた安全アプローチを継承し、安全性を確保。
コーディング能力は継承: o3モデルの持つコーディング能力は引き継ぎますが、Operator自体が直接コード実行環境やターミナルにアクセスする機能は持ちません。
性能を示すベンチマーク結果:

Anthropic、次世代AIモデル「Claude 4 Opus/Sonnet」発表。新APIや開発ツール「Claude Code」も登場
Anthropic社が、同社初となる開発者向けイベント「Code with Claude」で、次世代AIモデル「Claude Opus 4」および「Claude Sonnet 4」を発表しました。これらの新モデルは、コーディング能力や高度な推論能力が大幅に向上しているとのことです。あわせて、AIエージェント開発を加速させる新しいAPI群や、ターミナル中心のAIコーディング支援ツール「Claude Code」の一般提供開始など、多岐にわたる大型アップデートが実施されました。
https://www.youtube.com/live/EvtPBaaykdo?si=L8YbpzOZa3XJUY65
主な特徴とポイント:
次世代モデル登場: コーディング、高度な推論、AIエージェント能力で業界標準を目指す「Claude Opus 4」と、応答精度が向上した「Claude Sonnet 4」を発表。
強力な新API群: Claudeによる直接的なコード実行、外部ツール連携の簡素化、ファイルの永続管理、最大1時間のコンテキスト維持など、AIエージェント開発を支援する4つの新機能をベータ版で提供。
「Claude Code」一般提供開始: ターミナル上で動作し、IDEやGitHubとも連携可能なAIコーディングアシスタント。
ベンチマークで高性能を実証: 「SWE-bench verified」など主要ベンチマークで、OpenAIのo3やGemini 2.5 Proを上回る結果を記録。
安全性への継続的取り組み: AI Safety Level 3 (ASL-3) を含む高度な安全対策を実装し、リスクの最小化と安全性の最大化を図る。
詳細はこちら:
https://agi-labo.com/articles/n9a38887b7980
Meta、AIモデル「Llama」のスタートアップ向け導入支援プログラムを開始
Metaが、同社のAIモデル「Llama」の採用をスタートアップ企業に促すための新しい支援プログラム「Llama for Startups」を開始しました。このプログラムでは、対象企業に対し、MetaのLlamaチームによる直接的なサポートや、場合によっては資金提供も行うとしています。激化するオープンソースAIモデル市場において、Llamaエコシステムの拡大を目指す動きです。
主な特徴とポイント:
スタートアップ支援: Llamaモデルを活用する米国拠点のスタートアップに対し、技術サポートや資金援助を提供。
資金援助の詳細: 最大月額6,000ドルを最長6ヶ月間提供し、生成AIソリューション構築コストを支援。
応募資格: 米国法人で、資金調達額1,000万ドル未満、開発者1名以上在籍、生成AIアプリ開発中の企業。
エコシステム拡大戦略: 競合が激化するオープンソースAIモデル市場で、Llamaの普及と利用促進を図る。
Llamaの収益化計画: Llama搭載AIアシスタント「Meta AI」での広告表示や有料プラン導入の可能性も示唆。
Google I/O 2025基調講演まとめ:Gemini新時代到来、AIの自律性とパーソナライゼーション深化へ
Googleが開発者向けイベント「Google I/O 2025」の基調講演で、AIモデル「Gemini」を中心とした多数の新技術やサービスを発表しました。今年のテーマはGeminiの「自律性」と「パーソナライゼーション」の深化で、AIがユーザーの状況をより深く理解し、能動的にサポートする未来が示されました。検索機能の「AI Mode」や3Dビデオ通話「Google Beam」、Android XRプラットフォームなど、ハードウェアとの連携も強化されています。
https://www.youtube.com/live/o8NiE3XMPrM?si=8N7zR2QGZpSxmqYK
主な特徴とポイント:
AIファースト加速: Google CEOがAI開発の進捗とGemini時代における製品リリースの加速を強調。
新サービス・新機能多数発表: 3Dビデオ通話「Google Beam」、Meetリアルタイム音声翻訳、進化したAIアシスタント「Gemini Live」、タスク自動化「Agent Mode」、GmailパーソナライズドSmart Replyなど。
Geminiモデル群の大幅進化: 最上位モデル「Gemini 2.5 Pro」のアップデート、高速・低コストモデル「Gemini 2.5 Flash」の性能向上、思考時間を増やす「DeepThinkモード」などを発表。API機能も強化。
検索体験の革新「AI Mode」: 複雑な質問への包括的回答、パーソナライズ、詳細調査代行、データ可視化、タスク実行など、Geminiベースの高度なAI検索機能を米国で提供開始。
生成AIツールの進化: 最新画像生成モデル「Imagen 4」、音声同時生成可能な動画モデル「Veo 3」、音楽制作支援「Music AI Sandbox (Lyria 2)」、AI映画制作ツール「Flow」を発表。
詳細はこちらにまとめています:
https://agi-labo.com/articles/n62fd4c630dad
Microsoft Build 2025発表まとめ:新Copilot、MCP対応などAIエージェント新時代へ
マイクロソフトが開発者向けイベント「Build 2025」で、AI関連の多数のアップデートを発表しました。特に注目されるのは、GitHub Copilotの「コーディングエージェント」への進化、企業向けカスタマイズ機能「Copilot Tuning」、AIアプリ・エージェント開発統合基盤「Azure AI Foundry(エージェントファクトリ)」の強化、そしてオープンな連携を目指す「MCPサーバー」への対応です。これらの発表は、AIがより自律的にタスクを実行し、相互に連携する「オープンなエージェンティック・ウェブ」の実現に向けた同社の強い意志を示すものです。
https://www.youtube.com/watch?v=ceV3RsG946s
主な特徴とポイント:
GitHub Copilotが「エージェント」化: 単なるコード補完から、バグ修正や機能追加などを自律的に実行する「チームメンバー」のような存在へ進化。
企業特化AI「Copilot Tuning」: Microsoft 365 Copilotを企業の独自データでファインチューニングし、専門性の高いアシスタントを構築可能に。
統合開発基盤「Azure AI Foundry」強化: xAIの「Grok 3」やOpenAIの「Sora」など新規モデル追加。エージェント開発・管理機能も拡充。
MCPサーバーへの対応: AIエージェント間のオープンな連携を実現する「Model Context Protocol」をWindows OSレベルでネイティブサポート。
オープンなエコシステム構築: 自然言語でウェブサイトと対話可能にする「NLWeb」プロジェクトなども発表し、AI技術の相互運用性と拡張性を推進。
詳細はこちら:
https://agi-labo.com/articles/nf5ad2466291c
GoogleのAIノートアプリ「NotebookLM」、iOS・Android版が登場。オフライン音声再生や共有機能も
Googleは、複雑な情報を理解し、対話形式で活用できるAIツール「NotebookLM」のモバイルアプリ版を、iOSとAndroid向けにリリースしました。多くのユーザーから要望があったというこのアプリでは、AIが生成する音声概要(Audio Overviews)をオフラインで聞いたり、その場で情報源について質問したり、閲覧中のウェブサイトやPDF、YouTube動画などを直接NotebookLMに追加したりすることが可能です。
主な特徴とポイント:
モバイルアプリ提供開始: iOS (17以降) とAndroid (10以降) 向けにNotebookLMアプリをリリース。
オフライン音声概要再生: 生成された音声概要をダウンロードし、オフライン環境やバックグラウンドで再生可能。
インタラクティブな対話: 音声概要を聞きながら、AIホストに質問したり、話題の方向性を変えたりすることが可能。
外部コンテンツの簡単共有: ウェブサイト、PDF、YouTube動画などを、共有メニューから直接NotebookLMの情報源として追加。
今後の機能拡充: 今回はコア機能を中心とした初期バージョンで、今後数ヶ月でさらなる改良や機能追加を予定。

ByteDance系、統一マルチモーダル基盤モデル「BAGEL」発表。オープンソースでGPT-4oやGemini 2.0に対抗
TikTokを運営するByteDance傘下の研究チームByteDance Seedが、オープンソースの統一マルチモーダル基盤モデル「BAGEL」を発表しました。BAGELは、テキスト、画像、動画、ウェブデータを大規模に事前学習したデコーダーオンリーのモデルで、マルチモーダルな理解と生成をネイティブにサポートします。GPT-4oやGemini 2.0のようなプロプライエタリシステムに匹敵する機能を提供し、高精細な画像生成や複雑なマルチモーダル推論が可能です。
主な特徴とポイント:
オープンソースの統一マルチモーダルモデル: テキスト、画像、動画を統合的に扱い、理解と生成の両方を実現。
大規模データで事前学習: 数兆トークン規模の多様なマルチモーダルデータで学習し、複雑な推論能力を獲得。
多様な機能: チャット、画像・動画フレーム生成、画像編集、スタイル変換、ナビゲーション、思考モードなど、幅広いタスクに対応。
MoTアーキテクチャ採用: Mixture-of-Transformer-Experts (MoT) アーキテクチャにより、多様なモーダル情報からの学習能力を最大化。
段階的な能力獲得: 学習が進むにつれて、基本的な理解・生成から複雑な編集能力へと段階的に能力が発現する「創発特性」を確認。





