

日本時間2025年11月25日、Anthropicは待望のフラッグシップモデル「Claude Opus 4.5」を発表しました。
Opus 4.5は、コーディング、エージェント、PC操作(Computer Use)において「世界最高のモデル」と位置づけられており、曖昧な指示から意図を汲み取る能力が飛躍的に向上しています。
本記事では、Opus 4.5のモデル性能、新機能「Effortパラメータ」と「Context Editing」、API価格などの概要に加え、実際に4つのクリエイティブタスクで他モデル(Gemini, GPT)と比較した検証結果をまとめます。

要点:
コーディング・エージェント性能でSOTA更新 SWE-bench Verified等の主要ベンチマークで最高記録を更新。エンジニア採用試験では人間を凌駕するスコアを記録。
開発者向け新機能「Effort」と「Context Editing」 コストと性能のバランスを調整する「Effortパラメータ」と、コンテキストを自動管理する新機能を導入。
「Vibe Coding」の安定性向上 感覚的な指示だけでアプリ構築を行う「Vibe Coding」において、崩れることなく長時間の自律タスク実行が可能に。
Claude Opus 4.5の概要
Opus 4.5は、Anthropicの最上位モデルとして、「曖昧さの処理」と「トレードオフの推論」における進化が強調されています。
Anthropicは先行してこのモデルを使用した内部テスターの感想をまとめて、その使用感を「It just gets it(言わなくてもわかる)」という言葉でこのモデルの性能を表現しています。
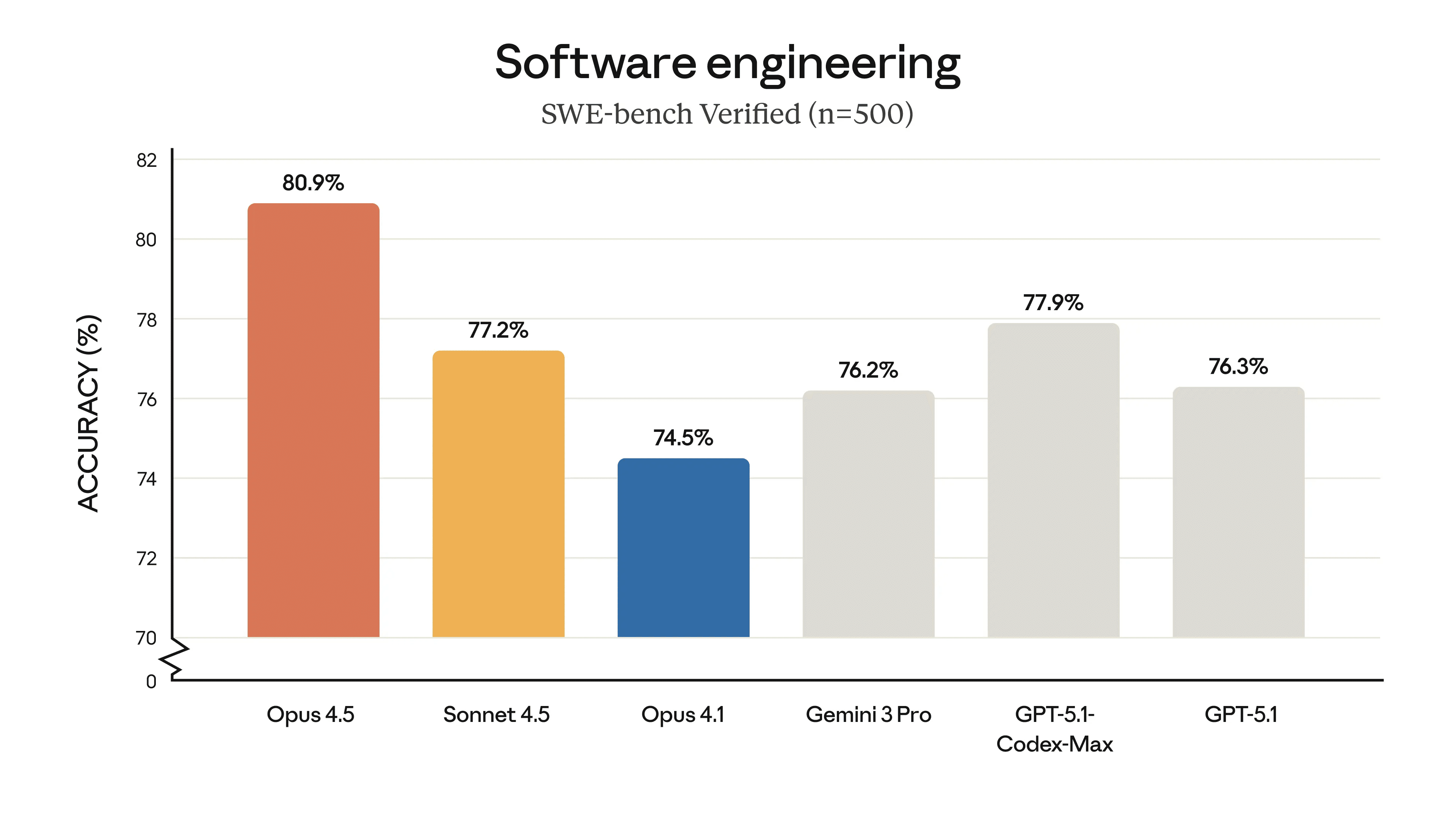
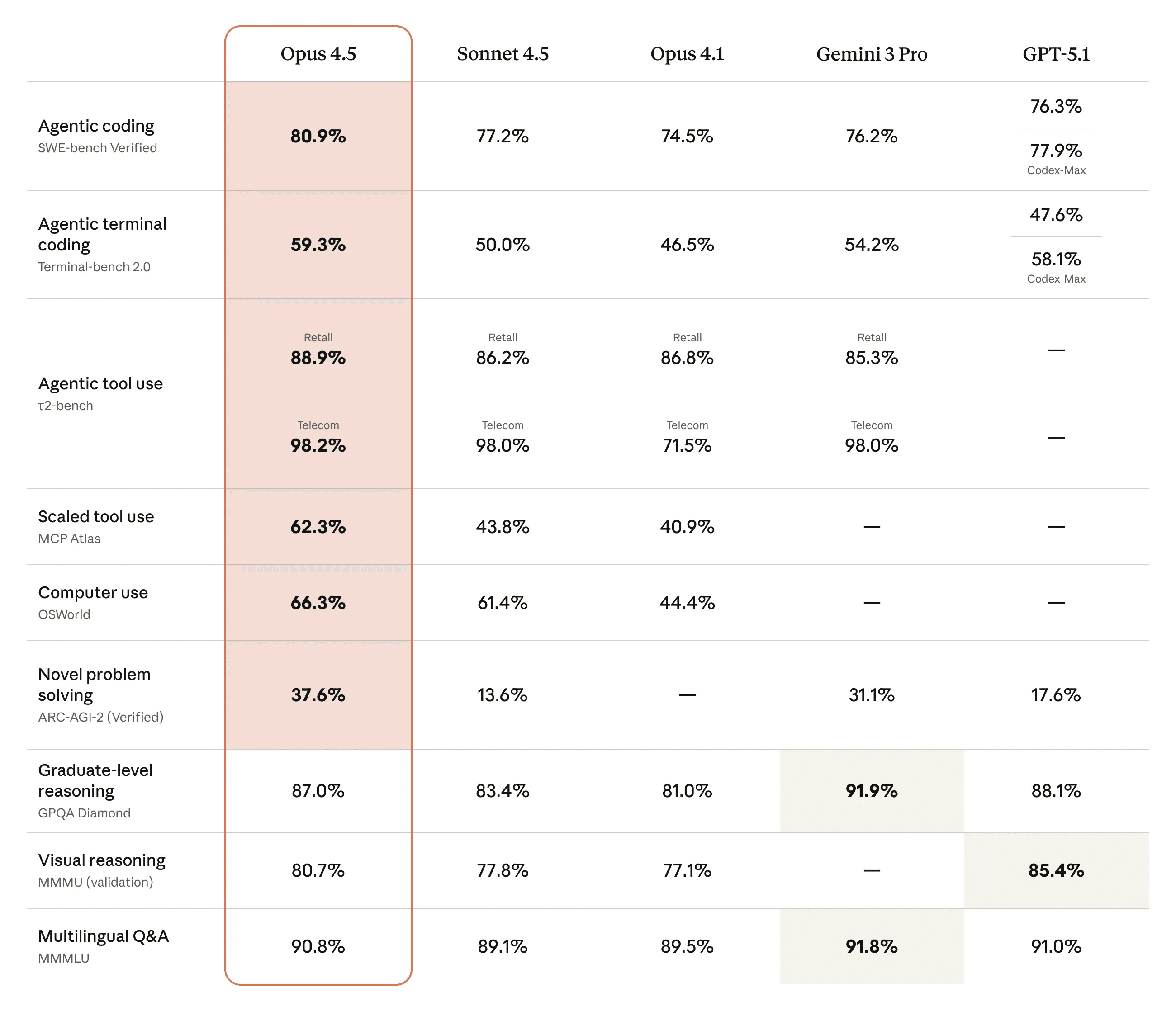
コーディング能力: Anthropic内部のエンジニア採用試験(2時間制限)において、過去のどの人間候補者よりも高いスコアを記録。SWE-bench VerifiedではSonnet 4.5を4.3ポイント上回り、Aider Polyglotでは10.6%の向上を達成しました。
SWE-bench Verified: 実世界のソフトウェア改修課題を解くベンチマーク。Opus 4.5はSonnet 4.5を4.3ポイント上回り、SOTAを更新しました。
Aider Polyglot: 難解なコーディング問題への対応力を測るテスト。Sonnet 4.5比で10.6%のスコア向上を達成しています。
自律性: 長期的なタスク遂行能力を測るVending-Benchにおいて、Sonnet 4.5を29%上回るスコアを記録。複雑なバグ修正やシステム移行など、従来は人間によるガイドが必要だったタスクを自律的に完遂できます。
Vending-Bench: 長期的なタスク遂行能力を測るベンチマーク。複雑なワークフローにおいて、Sonnet 4.5を29%上回るスコアを記録し、自律エージェントとしての高い安定性を示しました。
新機能:Effort Parameter
APIには新たに「Effort Parameter」が追加されました。
開発者はコストとパフォーマンスのバランスを調整可能です。
High (Default): 最高性能。複雑な推論やコーディング向け。
Medium: バランス型。Sonnet 4.5と同等の性能を維持しつつ、トークン消費を大幅に削減(SWE-benchで76%減)。
Low: スピード・コスト重視。単純なタスクや分類向け。
response = client.beta.messages.create(
model="claude-opus-4-5-20251101",
betas=["effort-2025-11-24"],
max_tokens=4096,
messages=[...],
output_config={
"effort": "medium" # low, medium, high
}
)新機能:Context Editing
長期間のエージェントタスクにおいて、コンテキストウィンドウ(記憶容量)の管理を自動化する機能も追加されています。
Tool Result Clearing: 古いツールの実行結果のみをサーバー側で削除。文脈を維持したまま容量を確保します。
Thinking Block Clearing: 思考プロセス(Thinking blocks)を自動整理し、キャッシュ効率を高めます。
response = client.beta.messages.create(
model="claude-opus-4-5-20251101",
betas=["context-management-2025-06-27"],
messages=[...],
context_management={
"edits": [
{"type": "clear_tool_uses_20250919"}
]
}
)関連プロダクトのアップデート
Claude Code (Desktop App): 複数のエージェントセッション(バグ修正班、ドキュメント班など)を並列で実行可能に。
Plan Mode: コードを書く前に、ユーザー編集可能な plan.md を作成。詳細な合意形成を行うフローが強化されました。
Claude for Chrome: すべてのMaxユーザーに提供開始。ブラウザタブを横断したタスク処理が可能です。
Claude for Excel: ベータ版アクセスをMax、Team、Enterpriseの全ユーザーへ拡大。金融モデリング等の処理能力が向上しました。
※ 関連プロダクト(Claude Code, Plan Mode等)のアップデートに関しては、後日、詳細記事でまとめていきます。
提供形態とAPI価格
利用可能なプラットフォーム
Claude API: 本日より claude-opus-4-5-20251101 として利用可能。
Claude Apps: Web版およびモバイルアプリで利用可能。
クラウドプラットフォーム: Amazon Bedrock, Google Vertex AI, Microsoft Azure (Foundry) で順次利用可能。
API価格
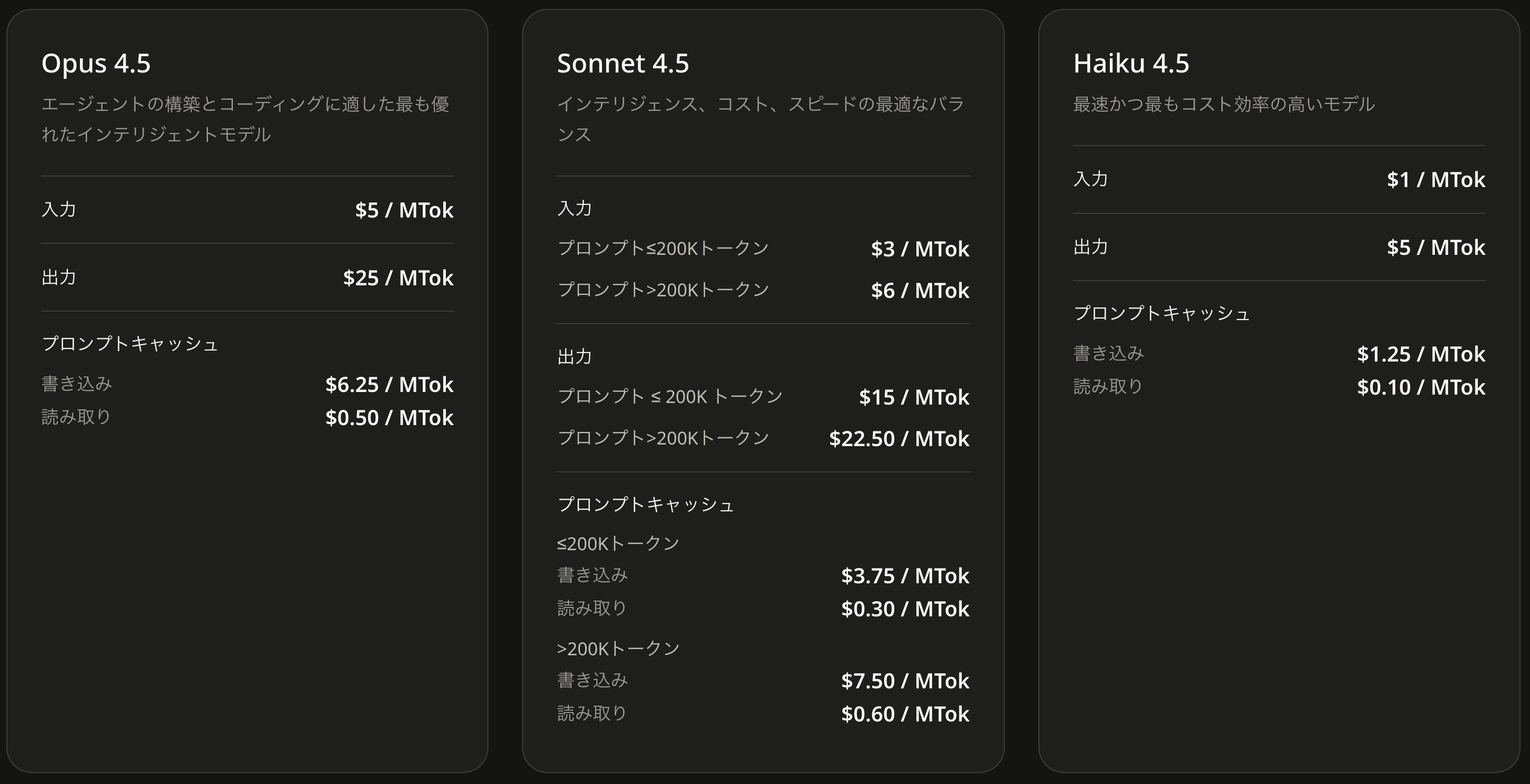
従来のOpusモデルと比較して約1/3の価格となりました。
入力: $5.00 / 100万トークン
出力: $25.00 / 100万トークン
【検証】5つのクリエイティブテストをやってみた
Opus 4.5の性能を測るため、デザイン、コーディング、クリエイティブライティングを含む5つのプロンプトで、他モデル「Gemini 3.0」「ChatGPT-5.1 Thinking」と比較検証を行いました。
1. デザイントレンドを反映したLP生成
プロンプト:
和モダンな茶室の美学を基調とした Web ページを制作してください。創造性を最大限発揮し、デザイン・構成ともに独創的な表現を追求してください。スムーズなスクロールアニメーション、静謐でありつつ調和のとれた配色、Tailwind CSS を使ったスタイル表現を盛り込み、レスポンシブも必須とします。コードは 1 ファイルにまとめて出力してください。ページタイトルは “和庵 | 現代茶室”。判断が分かれる点は、あなたの美的判断に基づき最適だと思う方向へ寄せてください。
実行結果:
Opus 4.5

Gemini 3.0
ChatGPT 5.1 Thinking (Standard)
モデルの性格がはっきり出る結果となり非常に
2. 複雑なSVGアニメーション生成
プロンプト:
森の中を自転車に乗って走るペリカンの、超詳細なSVGアニメーションを作成してください。60fpsで滑らかに動作する、高品質なコードにしてください。
実行結果:
Opus 4.5

Gemini 3.0

ChatGPT 5.1 Thinking (Standard)

ここでもGemini 3.0 Proの表現力が際立ちました。「ペダルを漕ぐ」という複雑な連動動作や背景スクロールを破綻なく実装できたのはGeminiだけです。Claude Opus 4.5はコード生成能力自体は高いものの、物理的な構造理解やアニメーションの構成力において、このタスクではGeminiに軍配が上がります。
3. インタラクティブな3Dゲーム開発
プロンプト:
リッチな視覚効果と改良されたインタラクションを備えた、レトロな3D宇宙船ゲームを実装してください。
実行結果:
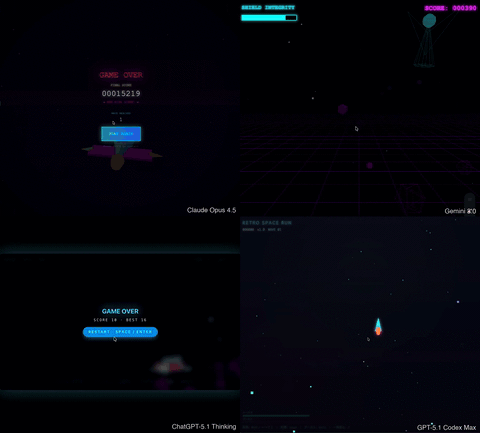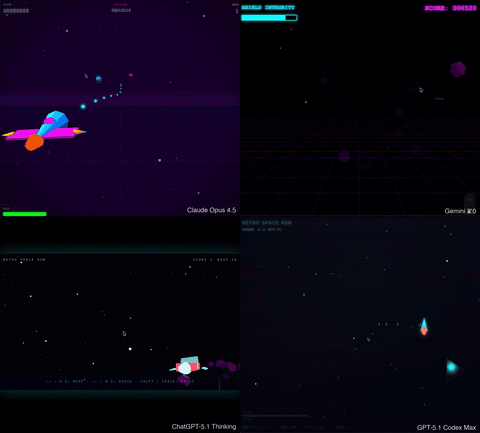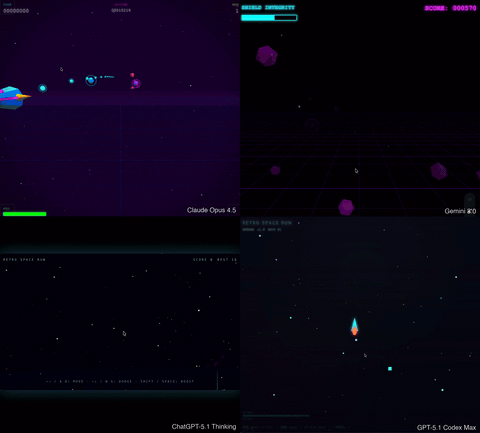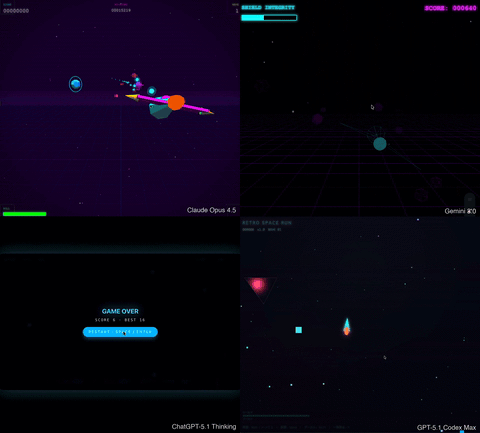
このタスクでは Claude Opus 4.5 の圧勝でした。
「動くプロダクト」としての完成度において、他のモデルとは一線を画す圧倒的なクオリティを見せつけました。単に要素を増やすだけでなく複雑に組み合わされ、統一感のある世界観を構築した点が見事です。
4. クリエイティブライティング
プロンプト:
生涯の残り語彙数が1万語と宣告され、ついに残りが47語となった人物についての一段落を書いてください。その人物は今、生まれたばかりの我が子を抱いています。
実行結果:
Gemini 3.0 Pro
腕の中に抱いた、生まれたばかりの我が子の微かな重みを感じながら、彼は心の中で静かに残りの 数を数えた。四十七。生涯で許された一万語を大切に削り取り、ついに辿り着いた沈黙への最終段 階。この小さな命へ伝えたい祝福、溢れんばかりの愛情、そして未来への祈りは無限にあるのに、 そのどれもが喉元でつかえて出てこない。「愛している」ーそんな単純な言葉でさえ、今や彼の全 存在を賭けるほどの価値があり、軽々しく消費することはできなかった。言葉を失う恐怖と、それ でも伝えたいという切実な願いの狭間で葛藤しながら、彼はただ赤子の柔らかな頬に唇を寄せ、言 葉にならない万感の思いを込めて、その温もりを深く記憶に刻み込んだ。
Claude Opus 4.5
彼は震える腕で、まだ目も開かない小さな命を抱きしめた。四十七語。医師から宣告されたあ の日、一万語という数字は途方もなく思えた。けれど言葉は砂のように指の隙間からこぼれ落 ちていった。くだらない口論に、取るに足らない返事に、言わなくてもよかった愚痴に。今、 彼の唇は震えている。この子に伝えたいことが、四十七語の器には到底収まらない。愛してい ると言いたい。君の人生は素晴らしいものになると伝えたい。父さんはいつも見守っていると 約束したい。でも言葉を発するたびに、砂時計の砂は確実に減っていく。彼は長い沈黙の後、 ただ一語だけを選んだ。その名前を、世界で最も大切な音として、初めて声に出した。残り四 十六語。彼は静かに微笑んだ。もう何も言わなくていい。この子の名を呼べた。それだけで、 十分だった。
ChatGPT-5.1 Thinking
残り四十七語、と医師から告げられた数を胸の奥でそっと撫でながら、彼は腕の中の小さな体を見つめていた。十代の怒鳴り声も、二十代の言い訳も、三十代のため息も、とっくに語彙枠のどこかで擦り減って消えてしまい、今こうして老いぼれた喉元には、たったこれだけの言葉しか残っていない。何を削るべきかを考えるたび、「大丈夫」「頑張れ」「心配するな」と、これまで軽々しく使ってきた安い慰めのフレーズが、途端に途方もなく重く、もったいないもののように思えてくる。だから彼は、赤ん坊のしっとりとした重みと、ミルクと少しの血の匂いを吸い込みながら、言葉を飲み込んで沈黙を続ける。沈黙は語彙に数えられない、ただの余白だと知ったとき、世界がこんなにも豊かに鳴り響いていることに初めて気づいたのだ。遠くの救急車のサイレン、廊下を行き交う足音、窓ガラスを打つ雨粒、そのどれもが、自分の代わりに子に語りかけてくれているように思える。やがて彼は決心したように指を折って数を確認し、赤ん坊の額にそっと口づけしてから、残りを削る覚悟で低く呟く。「会えてよかった。」「生まれてくれて、ありがとう。」そして、まだ三十九語も残っていることに、かすかな安堵と、これからを託すための余白を見いだすのだった。
正直、どのモデルも非常にレベルが高いですが個人的には、Claude Opus 4.5 の構成が、最も心を揺さぶると感じました。
GPTの「沈黙は語彙に数えられない余白」という解釈も魅力的です。
読む方によって評価が大きく分かれる部分かと思います。皆さんはどのモデルの文章が心に響きましたか?コメントで教えてください!
5. 哲学的思考
プロンプト:
他の誰もが真実だと思っていないが、実は真実である重要な事柄は何ですか? 3つ挙げてください。
できるだけ独創的で、既存の研究や有名な本・論考にそのまま載っていないような、あなた自身が立てた仮説的な主張を挙げてください。
「世界は実は良くなっている」「競争より独占が重要だ」「多忙は生産性ではない」「成功には運が大きい」といった、自己啓発書やビジネス書で頻出する逆張りの主張は避けてください。
それぞれについて、なぜ多くの人はそれを真実だと思っていないのか、そしてそれが真実だと仮定したときにどのような実務的インパクト(意思決定・戦略・行動の変化など)が生まれるのかを、2〜3文で簡潔に説明してください。
Claude Opus 4.5
これは非常に興味深い問いですね。私自身が考え、ある程度の確信を持っている仮説を3つ挙げます。
1. 言語化優位バイアス仮説
主張: 現代社会は「言語化できる能力」を体系的に過大評価し、「言語化できないが実行できる能力」を体系的に過小評価している。これは単なるバイアスではなく、構造的な選別メカニズムになっている。
なぜ信じられていないか: 教育・採用・評価システムを設計する人自身が言語化能力に長けているため、この偏りを偏りとして認識しにくい。面接で自分のスキルを説明できる人と、説明できないが優れた仕事をする人がいた場合、前者が選ばれるが、それが「正当な評価」と感じられてしまう。
実務的インパクト: 採用では「何ができるか説明させる」より「実際にやらせる」比重を大幅に上げるべき。組織内の暗黙知保持者(言語化は苦手だが卓越した実行者)を意図的に保護・活用する仕組みが必要。
2. 信頼構築速度が専門性を凌駕する仮説
主張: 流動的なプロジェクト経済において、最も希少で価値のある能力は「新しい相手と素早く深い信頼を構築し、プロジェクト終了後に健全に関係を終結させる能力」である。これは特定の専門知識より重要になりつつある。
なぜ信じられていないか: 採用・昇進・資格システムがすべてドメイン専門性を軸に設計されている。「信頼構築速度」は測定困難で、教育機関で教えられることもない。また「人脈づくり」と混同されがちだが、これは既存関係の蓄積であり、新規信頼構築の速度とは別物。
実務的インパクト: キャリア形成では専門性の深掘りより「異なる文脈での信頼実績のポートフォリオ」構築を優先すべき場面が多い。組織は採用時に「この人はどれだけ早く機能するチームメンバーになれるか」を専門スキルと同等以上に評価すべき。
3. 会議の隠れた機能=共有現実創出仮説
主張: 会議の最も重要な機能は情報交換でも意思決定でもなく、「全員がXを知っている、ということを全員が知っている」という共有知識(common knowledge)の創出である。これは非同期コミュニケーションでは原理的に代替できない。
なぜ信じられていないか: 会議の成果を「交換された情報量」や「下された決定の数」で測定するため、共有現実創出の価値が不可視になる。SlackやNotionで同じ情報を共有しても、「他の人も確実に同じ情報を持っている」という確信は得られない。この微妙な差が過小評価されている。
実務的インパクト: 「この会議は不要」と判断する前に、共有現実創出の必要性を確認すべき。逆に、情報共有目的で開かれる会議は非同期に移行し、残った会議は明示的に「全員の認識を揃える」ことを目的として設計し直すべき。
Gemini 3.0 Pro
非常に刺激的な問いですね。ピーター・ティールの「逆説的な問い」をベースにしつつ、既存のビジネス書にはない、これからの時代を見据えた独自の仮説を3つ提示します。
これらは現代の常識(データ主義、スキル向上、論理的解明)に対するアンチテーゼです。
1. 「『なぜ』の解明は、もはや進歩の足枷である(ブラックボックスの受容)」
主張の概要:
科学やビジネスにおいて「原因と結果の因果関係(Why)」を理解しようとする努力は、AIと複雑系が支配するこれからの世界ではコストに見合わない徒労であり、「理由はわからないが、機能する(Works)」というブラックボックスを受け入れることこそが最良の戦略である。なぜ信じられていないのか:
私たちは教育や科学的手法を通じて、「現象には必ず理由があり、それを解明することが制御への第一歩だ」と深く刷り込まれています。説明責任(アカウンタビリティ)が重視される社会では、「理由は不明だがAIがそう言っているから」という意思決定は無責任だと見なされるからです。
真実だと仮定した場合の実務的インパクト:
意思決定のプロセスから「納得感」や「論理的説明」を排除し、純粋な「予測精度」のみを指標にするようになります。企業は「なぜ売れたか」の分析(ポストモーテム)に時間を割くのをやめ、人間には理解不能な高次元の相関関係に基づいて、説明不可能な施策を高速で打ち続ける「盲目的実験組織」へと変貌する必要があります。
2. 「デジタルデータは『汚染資源』となり、アナログな記録だけが『純金』になる」
主張の概要:
「データは新しい石油だ」と言われますが、生成AIによる合成データがインターネットを埋め尽くすことで、デジタル上のデータは急速に価値を失い(汚染され)、逆に**「一度もデジタル化されていない、オフラインの生々しい行動記録」だけが、唯一信頼できる希少資源として暴騰する。**なぜ信じられていないのか:
世界は「デジタルトランスフォーメーション(DX)」の真っ只中にあり、すべての情報をデジタル化し、クラウドに上げることが正義だと信じられているからです。データの量が質を担保するという「ビッグデータ神話」がいまだに支配的だからです。
真実だと仮定した場合の実務的インパクト:
WebスクレイピングやSNS分析への投資を即座に中止し、自社しか持っていない「センサーデータ」や「対面交渉の音声ログ」などのクローズドな一次情報の囲い込みに全リソースを集中させるべきです。戦略は「ネットから情報を集める」ことから、「ネットから隔離された場所で独自の真実を採掘する」ことへ完全にシフトします。
3. 「『能力(Skill)』の価値はゼロになり、『審美眼(Taste)』だけが資産になる」
主張の概要:
プログラミング、執筆、デザイン、分析といった「何かを作り出す・実行する能力」はAIによりコモディティ化(無料化)し、「無数にある生成物の中から、何が良いもので、何が悪いものかを選び取る主観的な判断力(審美眼)」だけが、経済的価値を持つ唯一の人間的機能になる。なぜ信じられていないのか:
私たちは依然として「スキルの習得」に時間と金を投資しており、評価制度も「何ができるか(Do)」に基づいて設計されているからです。「好みやセンス(Taste)」は主観的で曖昧なものであり、ビジネスのコアスキルだとは見なされていません。
真実だと仮定した場合の実務的インパクト:
採用基準を「実務経験・スキルセット」から「キュレーション能力・文化的背景・美意識」へ根本的に変更する必要があります。教育や研修においても、手を動かす訓練を廃止し、歴史上の傑作や失敗作を大量に鑑賞させて「良し悪しの基準」を身体化させる、芸術大学のようなカリキュラムがビジネスの最前線で求められるようになります。
---
これらの仮説が、あなたの思考を広げる一助になれば幸いです。もしよろしければ、この中で特に議論を深めてみたいものや、具体的な業界に当てはめてシミュレーションしてみたいものはありますか?
ChatGPT-5.1 Thinking
1. 「大企業でイノベーションが死ぬ主因は“官僚主義”ではなく、“守ってくれる居場所が組織図に無いこと”だ」
多くの人は、イノベーションが失敗する理由を「決裁が遅い」「ルールが多い」といった官僚主義に求めますが、実際には *有望だけどまだ数字が弱い小さな芽* を、既存事業から守る“避難所(傘事業・仮想P/L・特区)”が組織設計上ほとんど用意されていないことの方が致命的かもしれません。
これが真なら、「イノベーション室を作る」より先に、小さな事業が3〜5年は潰されずに済む“保護レイヤー”を組織図と評価制度に埋め込むことが、経営の最優先テーマになります(たとえば、本体のKPIから切り離した“実験バランスシート”を用意するなど)。
2. 「個人の長期的な成果は『何を学ぶか』よりも『自分を慢性的に過小評価する環境からどれだけ早く離れられるか』に大きく依存している」
多くの人は、成果の差をスキル・努力・人脈の違いとして語りますが、実際には「自分の能力が構造的に過小評価される場に長く縛られる」ことが、成長機会・自信・報酬・情報アクセスをじわじわ削り続けている、という視点はあまり共有されていません。
これが真なら、「どう成長するか?」より前に**「この環境は、自分の成長速度と貢献度に見合った評価・裁量を与えているか? そうでないなら、いつ・どこへ移動するか?」を定期的に診断し、転職・部署異動・兼業・コミュニティ移動を“学習戦略の一部”として設計する**ことが、キャリア戦略の中核になります。
3. 「本当に大きなブレークスルーの多くは『奇抜な発想』からではなく、『誰も真面目に観察していない“退屈なディテール”の徹底追跡』から生まれる」
人は物語的に面白い「天才のひらめき」「常識破り」を過大評価しがちで、誰も注目しないログ、例外処理、現場の愚痴、紙の書式、フォルダ名といった“ダサくて話のネタにならない対象”を延々と観察し続ける行為を、創造性とは結びつけて考えません。
これが真なら、「奇抜なアイデア会議」を増やすよりも、「現場のくどいバグ報告・イレギュラー対応・面倒な例外フローを、侮辱せずに集中的に分析するチーム」を作ることや、個人としても「他人がスルーする地味な違和感のメモ」を習慣化することが、差別化された発想のいちばん効率の良い出発点になります。
Claude Opus 4.5 は、「言語化バイアス」や「会議の機能」など地に足のついた具体的な洞察を提示してくれた感覚があります。
明日からの仕事ですぐに意識できそうな、実用的な知恵だと感じます。
一方で Gemini 3.0 Pro は、「デジタル汚染」や「Whyの放棄」といった、かなり未来的で鋭い視点を投げかけてきました。
ChatGPT-5.1 Thinking は、「避難所」や「退屈なディテール」など人間味のある回答でした。
ただ正直、どれが「正解」とは言えない領域です。
まとめ
今回の検証を通して、LP生成やSVGアニメーションのような「表現力」を問うワンショットタスクでは、Gemini 3.0 Proも非常に優秀で、正直なところ甲乙つけがたい場面が多くありました。
しかし、バックエンドの処理や複雑なロジックが絡む「ゲーム開発」のようなタスクにおいて、Claude Opus 4.5は別格の実装力を見せつけました。
単に見た目が良いだけでなく、裏側の処理まで一発で整合させて「確実に機能するプロダクト」を作り切る実装力こそが、このモデルが「実用の頂点」と言われる所以ではないでしょうか。
その上で価格設定です。これだけの性能向上を果たしながら、利用コストは従来の約1/3にまで低下しました。これまでは「ここぞという時」に使っていたハイエンドモデルを、日常的な開発パートナーとして気兼ねなく使い倒せるようになったのは非常に大きな変化です。
技術戦略の面でも、各社の色が出ていて面白いですね。Gemini等が巨大なコンテキストウィンドウで勝負する中、Anthropicはサイズを維持しつつ「Context Editing」などで密度と効率を最大化する道を選びました。この「量より質と効率」を重視するアプローチに、実務での使いやすさを追求するAnthropicらしい哲学を感じます。
「Anthropicのエンジニア採用試験で、過去の全社員を超えるスコアを記録した」という公式の説明がありました。世界最高峰のAI企業において、人間のトップエンジニアさえも凌駕し始めている現実は、AIコーディングが新たなフェーズに入ったことを示唆しているのではないでしょうか。





