

日本時間 2026年6月10日、Anthropicが新モデル「Claude Fable 5」を公開しました。政府や重要インフラ向け限定だった「Mythosクラス」が、セーフガード付きで初めて一般開放されます。価格は100万トークンあたり入力10ドル/出力50ドルと、Opus 4.8の2倍です。
要点:
「Mythos クラス」の初の一般提供:Fable 5 は Opus 4.8 の後継ではなく、別系統の最上位モデルです。API のモデル名は claude-fable-5。〔公式〕
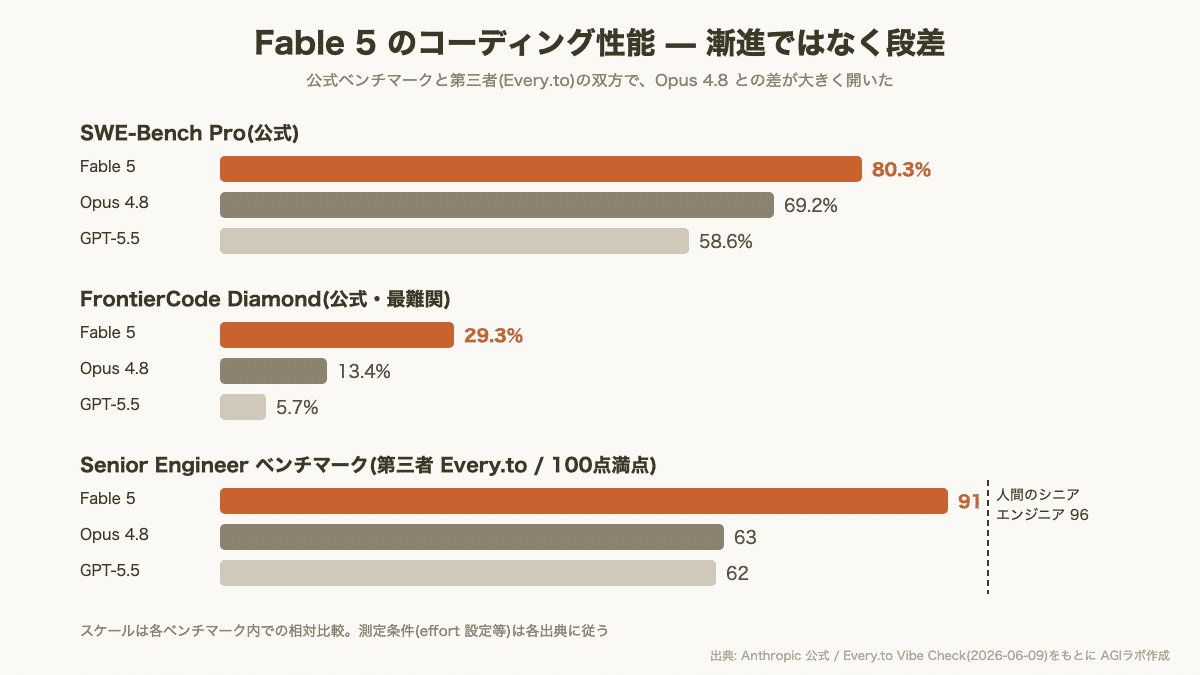
コーディングは漸進ではなく段差:SWE-Bench Pro は 69.2%→80.3%(Opus 4.8 比 +11.1pt)。外部評価でも Cursor が 72.9% の新 SOTA、Every.to が 91/100 と、方向が一致しました。〔公式・外部〕
強みは「長く複雑なタスク」に集中:外部評価6件で高い伸びを示したのはすべて長時間・複合系の試験です。短いタスクでは差がほぼ見えず、価格だけが2倍かかります。〔外部・実機〕
一部領域では Opus 4.8 が代わりに答える:サイバー攻撃・生物化学・蒸留の3分類でセーフガードが発動し、Opus 4.8 にフォールバックします。報じられている一部の高スコアは、一般には買えない「解除版(Mythos 5)」の数字です。〔公式・第三者〕
Claude Fable 5 の概要
まず押さえたいのは、モデルの系譜が変わったことです。
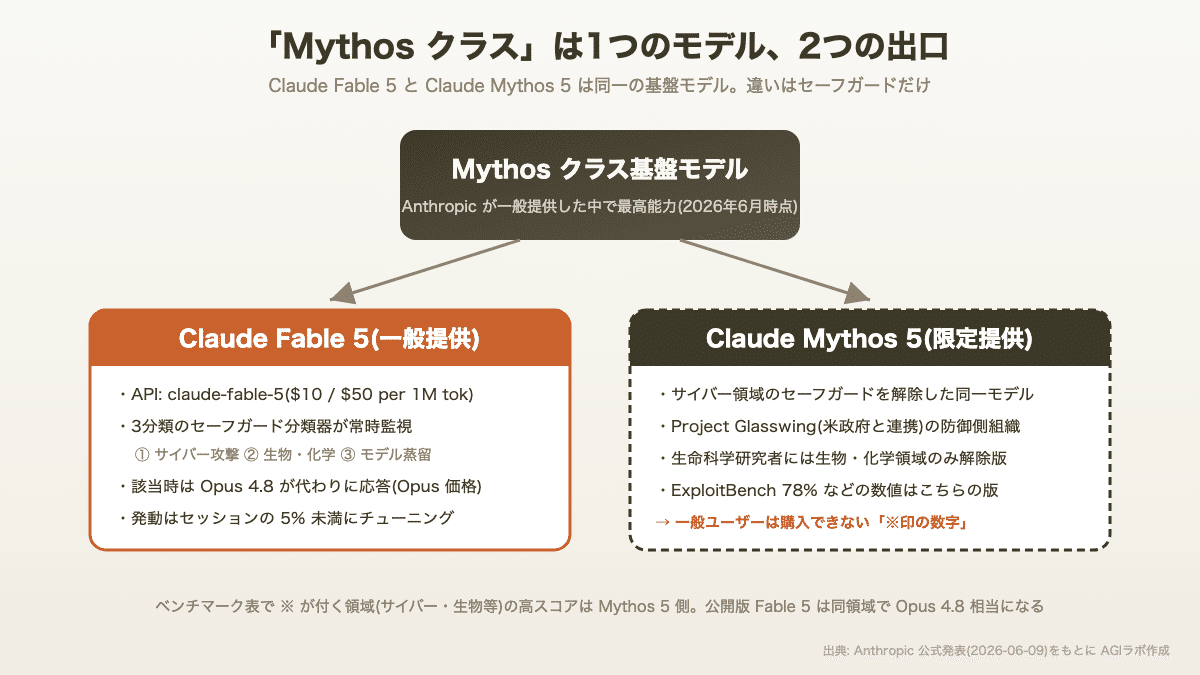
Fable 5 は Opus 4.8 の後継ではなく、「Mythos クラス」と呼ばれる別系統のモデルを、一般利用向けに調整したものです。
Mythos はこれまで、Project Glasswing(米政府と連携したサイバー防御の取り組み)などを通じた限定提供に留まっていました。今回はその正式版の基盤モデルから、2つの製品が同時にリリースされています。
Claude Fable 5:セーフガードを付けた一般提供版。今日から API で使えます。
Claude Mythos 5:一部のセーフガードを解除した版。サイバー防御組織や認可を受けた生命科学研究者のみが利用できます。
セーフガードの仕組み——「断る」のではなく「Opus 4.8 が代わりに答える」
Fable 5 には、3分類の安全フィルタが常時適用されています。
①サイバー攻撃への悪用、②生物・化学の危険領域、③モデルの能力抽出(蒸留)です。該当すると判断されたリクエストは、Fable 5 ではなく Opus 4.8 が代わりに応答します。その間の課金は Opus の料金体系が適用され、Fable の料金は発生しません。
発動率はセッションの5%未満にチューニングされており、初日のデータでは95%のセッションが Fable 5 自身の応答だけで完結したとのことです。一方で Anthropic 自身が「現状のフィルタはアグレッシブすぎて、無害なリクエストをブロックしうる」と認めています。
もうひとつ、Fable 5 の利用には30日間のデータ保持が必須です。ゼロ保持(zero-retention)契約を結んでいる企業でも、Fable 5 のトラフィックに限っては保持されます。社内規程のある組織は事前に確認してください。
公式ベンチマーク:コーディングの伸びが非連続
SWE-Bench Pro(実コード修正):80.3% / 69.2% / 58.6%
FrontierCode Diamond(最難関コーディング):29.3% / 13.4% / 5.7%
OSWorld-Verified(PC操作):85.0% / 83.4% / 78.7%
GDPval-AA(知的労働の質を対戦形式で比べるレーティング):1932 / 1890 / 1769
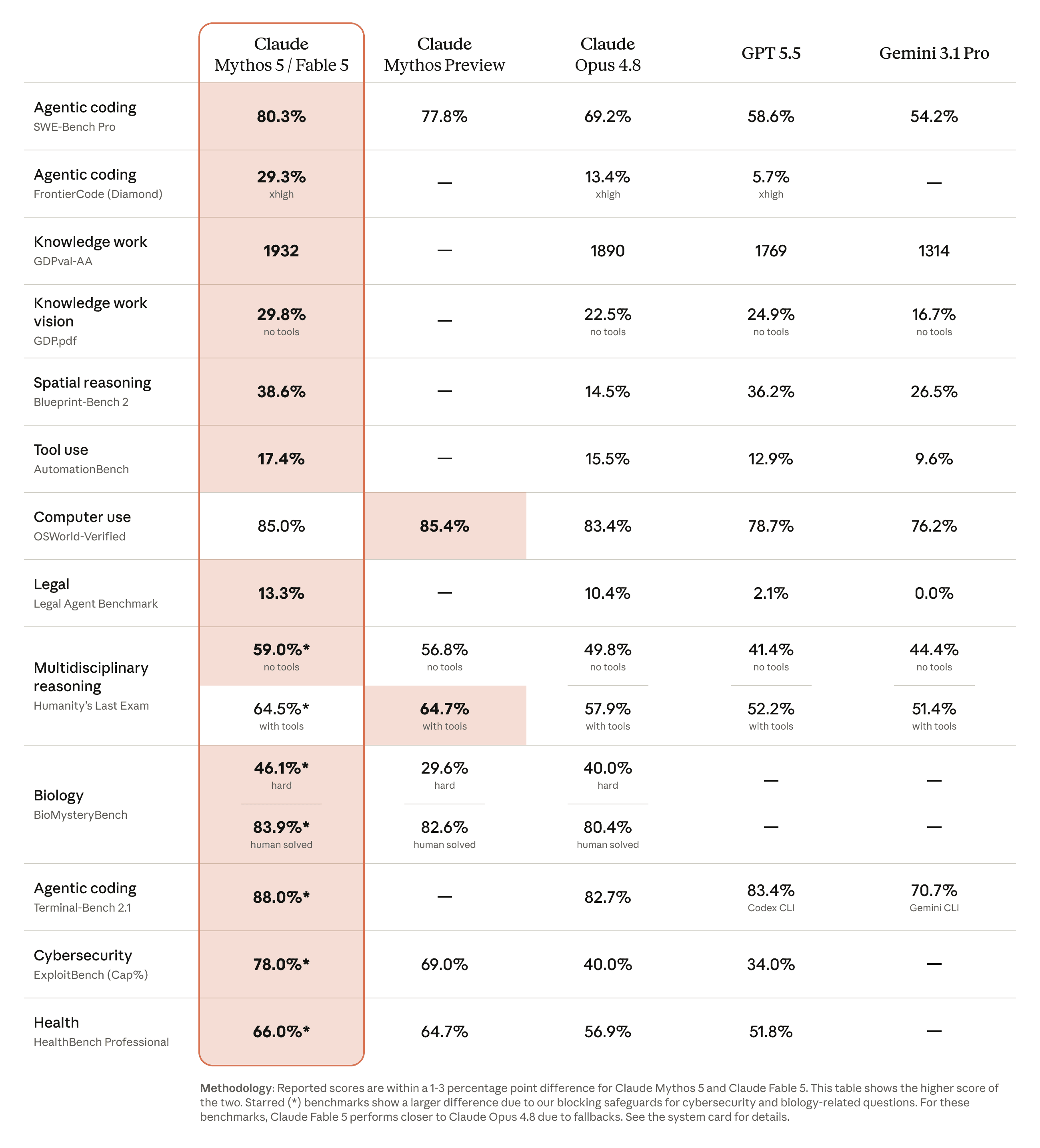
※印はセーフガード対象領域の数字で、この点は後述します
Opus 4.7→4.8 のときの SWE-Bench Pro は 64.3→69.2 と、5pt 程度の向上でした。
今回は 69.2→80.3 と、飛躍的な更新です。特に FrontierCode Diamond では Opus 4.8 の2倍を超えるスコアが出ており、難しいタスクほど差が開く傾向が公式数値からも読み取れます。
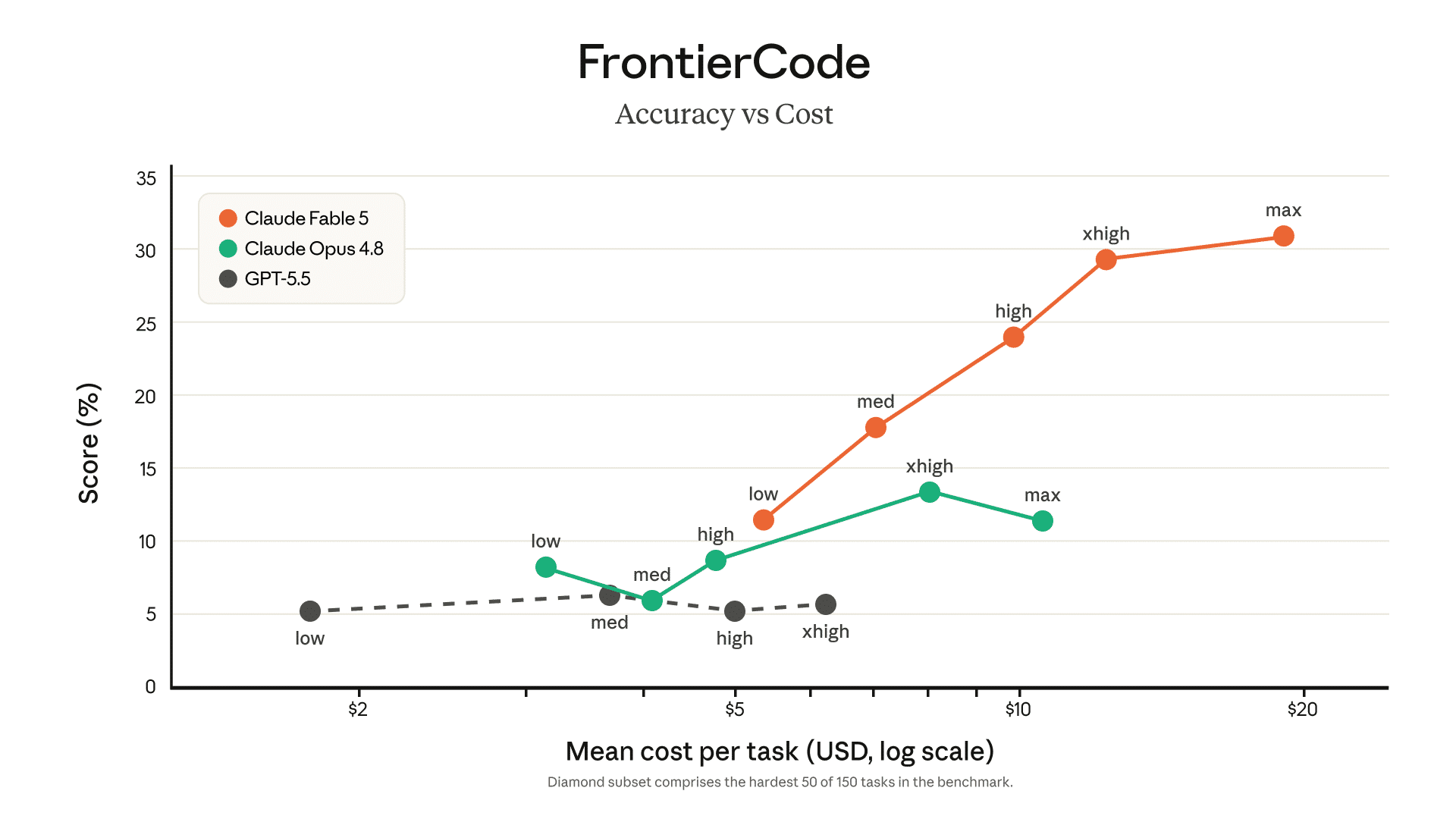
effort(労力)設定との関係も公式の図で示されています。FrontierCode の「精度対コスト」曲線では、Fable 5 は low でも Opus 4.8 の xhigh 相当に達し、effort を上げるほど差が広がります。前記事で詳しく扱った「effort 次第で別物になる」という性格は、Fable 5 において「どの effort でも一段上、ただしコストも一段上」という形に進化しました。
6件の外部評価まとめ

Every.to:91/100——人間のシニアエンジニアに迫る
7名が約1週間先行利用した Every.to の「Senior Engineer ベンチマーク」(現実の散らかったコードベースを作り直させる試験)では、91/100 を記録しました。Opus 4.8 の63、GPT-5.5 の62 から大きく離れ、人間のシニアエンジニア(96・89)に迫るスコアです。
同時に Every.to は、はっきりした弱点も挙げています。動作が遅く、トークン消費が大きいこと。そして小さなタスクでは優位性がほとんど見られないことです。

Cursor:CursorBench 72.9% の新 SOTA
コーディングエディタの Cursor は、公式 X で「CursorBench で 72.9% の新 SOTA。従来ベストを8ポイント更新」と発表しました。
ドキュメントでは「長いセッションでも意図を保持し、確認の往復が少ないままタスクを完了に持ち込む」と説明されています。
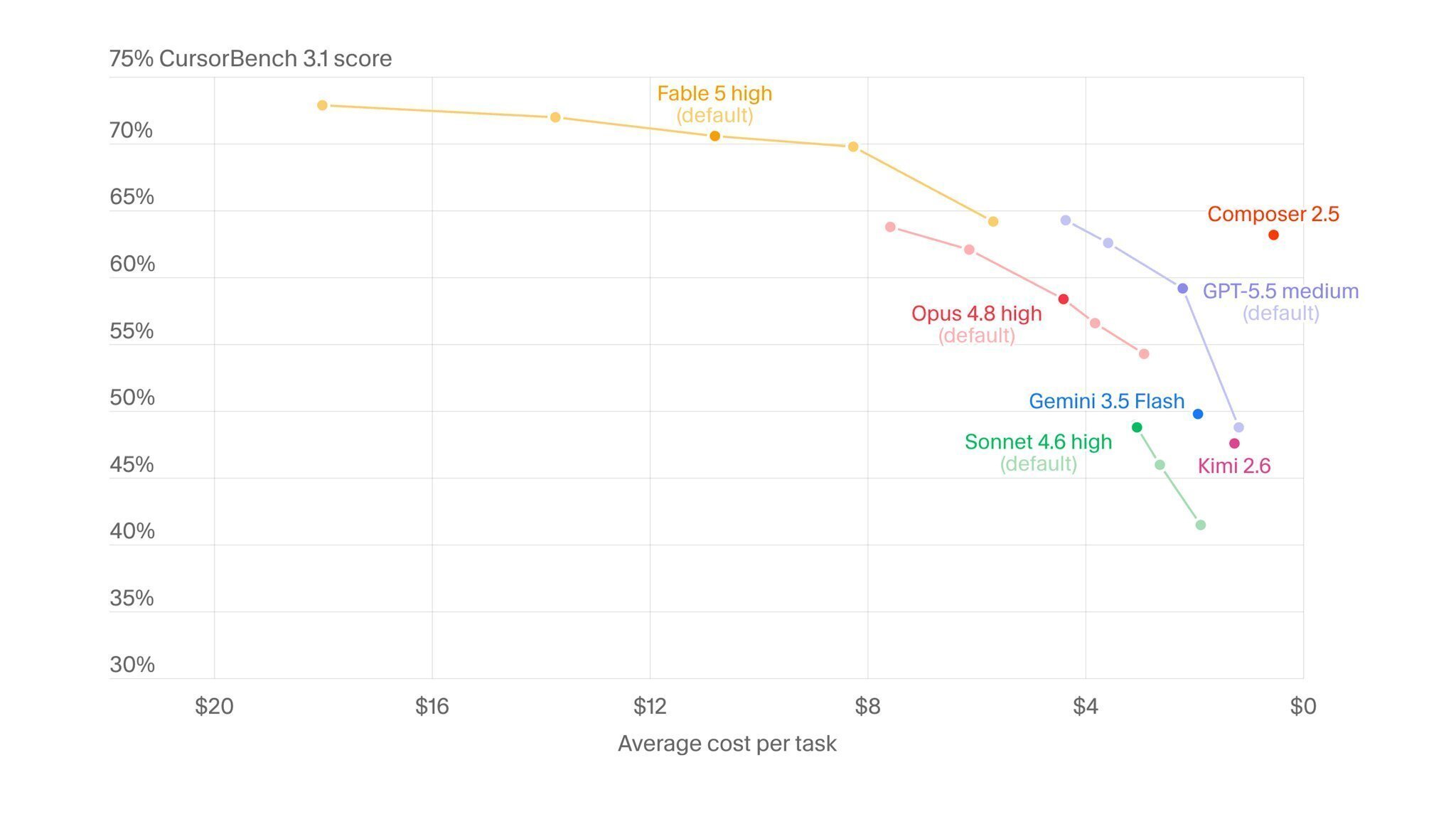
Fable 5 は high(既定)でも従来勢を上回り、コストを上げるほど伸びる
Harvey:リーガル特化の自社ベンチで過去最高
法務AIのHarveyは、自社のBigLaw Benchで93.4%(同社測定の過去最高)、エンドツーエンドの複雑な法務タスクを評価するLegal Agent Benchmarkで13.3%(Opus 4.8は10.4%)を記録したと報告しました。
弁護士による定性評価では、契約書のドラフト作成や「カウンターパーティの赤入れ(redline)分析」に特に強みを持つ一方、税計算やファンドのウォーターフォールモデリングといった複雑な定量タスクについては、「結果にばらつきがある」と明記されています。
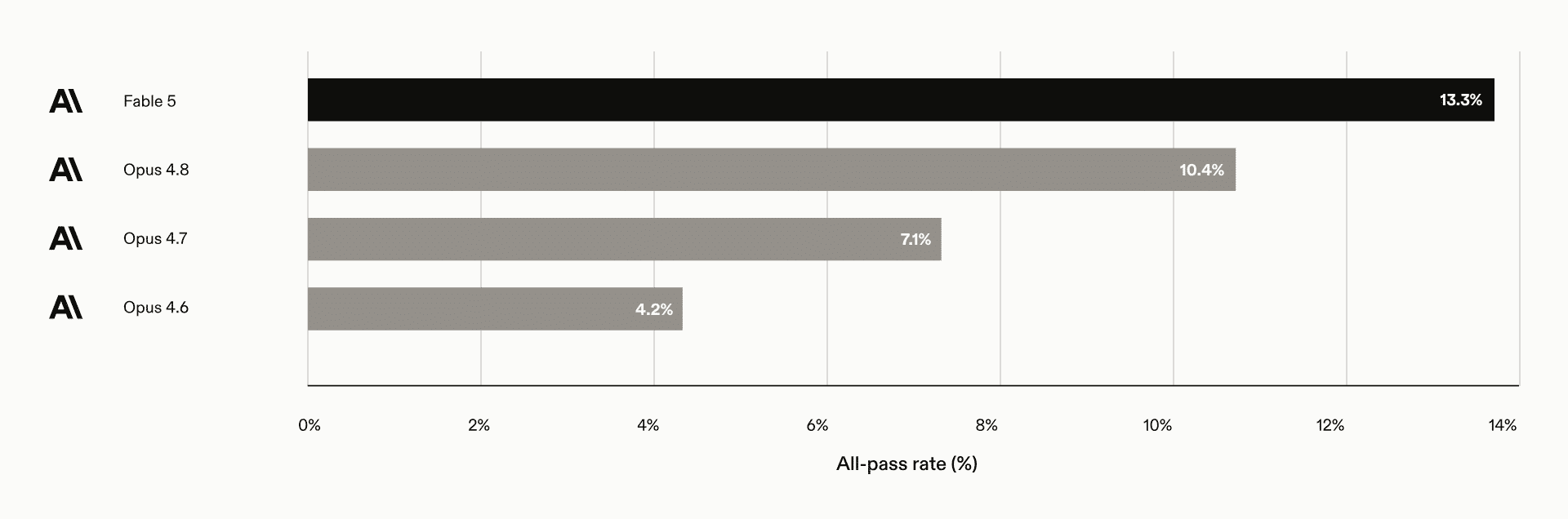
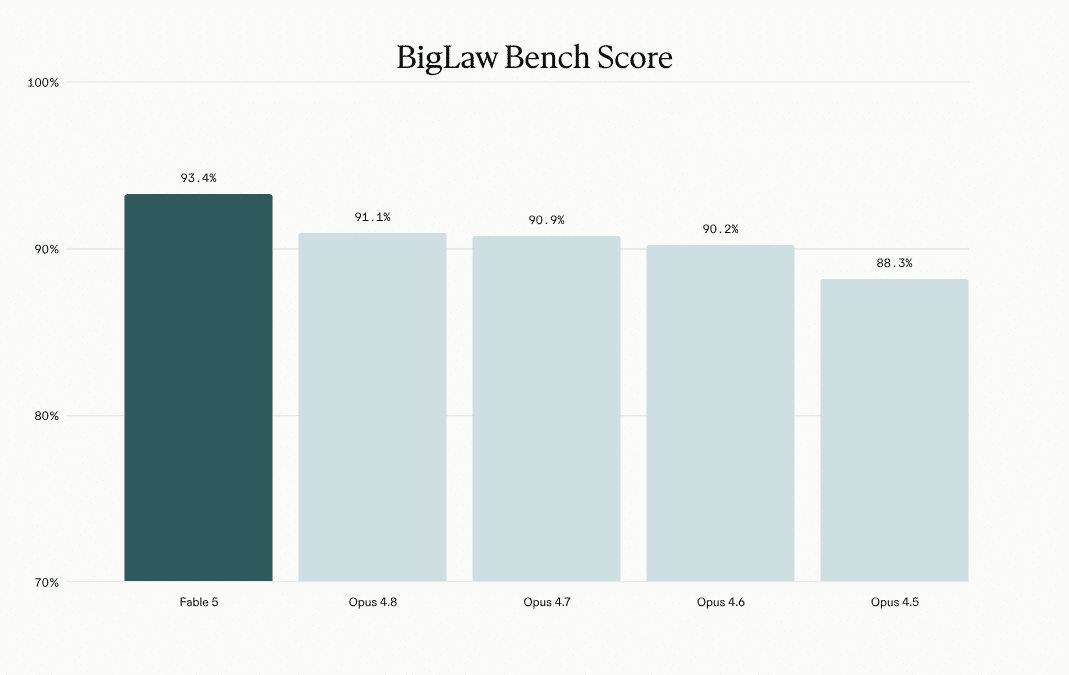
Hex・Replit・Hebbia:分析、アプリ制作、金融
Hex(データ分析):長時間の複合分析タスクを測る自社コアベンチで初の90%超え。Opus 系から10ポイントのジャンプと報告しています。
Replit(アプリ制作):アプリを丸ごと作らせる ViBench でテスト史上最高性能。より少ない時間・トークンで完成に至るという報告です。
Hebbia(金融):シニアアナリスト級の推論を測る Finance Benchmark で全モデル首位。文書推論、チャートと表の解釈で2桁の伸びとしています。
コミュニティの反応——歓迎と、財布への懸念
元OpenAI・Teslaで、現在はAnthropicに所属するAndrej Karpathy氏:
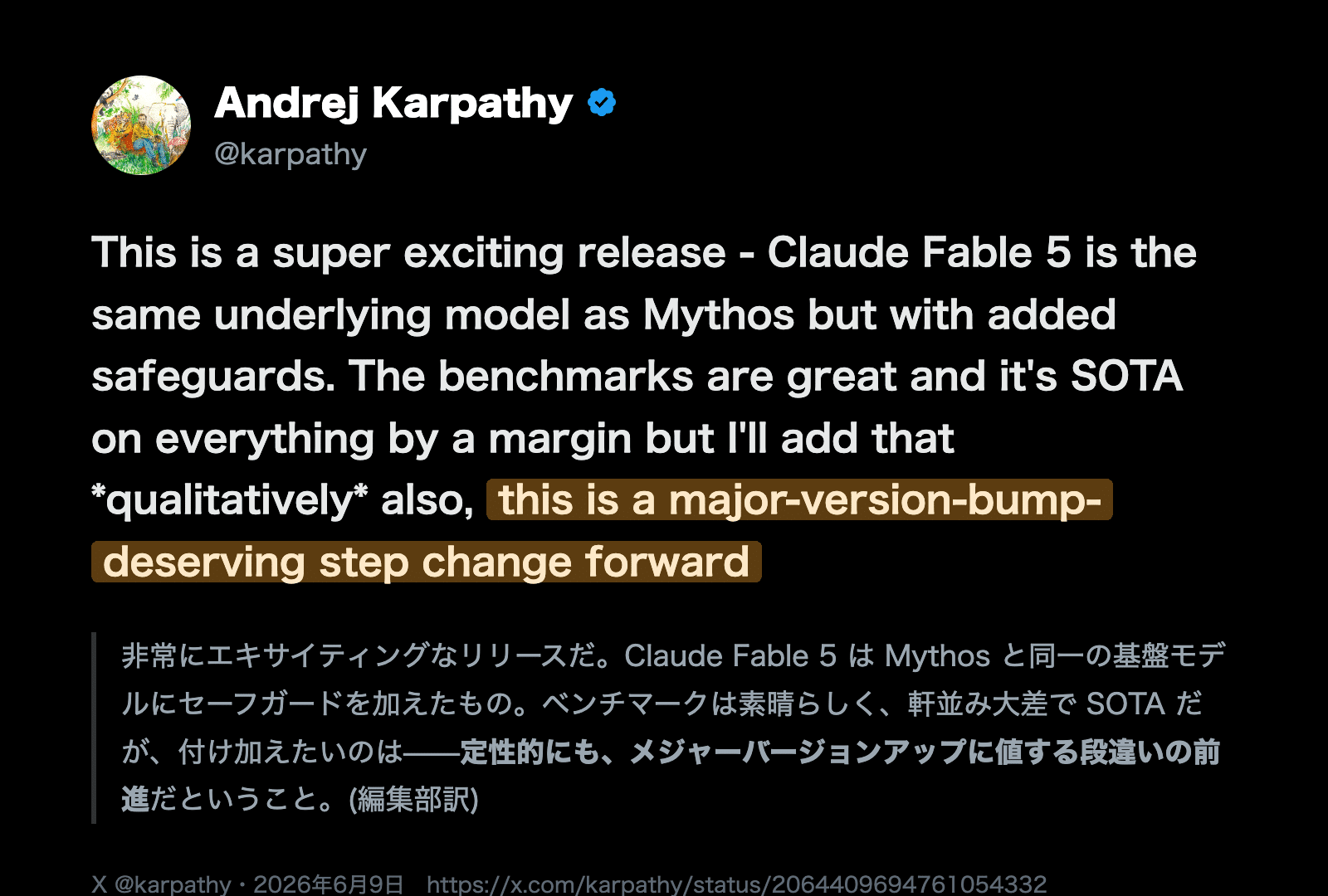
Cursor の発表も、評価の公表と提供開始が同時でした。

その他のコメント:
「一旦無料で提供して、後で取り上げる」というやり方はやや眉をひそめる。従量課金へ移行させたいように見える。
— eggbrain(Hacker News、2026年6月9日。6月22日までの無料提供について)
$100 の Max プランだが、5時間の利用枠を8分弱で使い切った。その後 $15 の超過課金が積み上がった。
— joshstrange(同)
エンタープライズアカウントでは「Fable 5 を使うにはゼロデータ保持を無効化せよ」と表示されて使えない。
— smith7018(同。30日データ保持の影響)
提供形態と価格——「2倍」をどう考えるか
利用できる場所
Claude API(claude-fable-5)、Amazon Bedrock、Google Cloud Vertex AI、Microsoft Foundry で本日から利用可能
GitHub Copilot でも同日に一般提供が始まっています
Claude.ai のサブスクリプション(Pro / Max / Team / Enterprise)では、6月22日までは追加費用なしで利用できます。6月23日以降は利用クレジット制に移行する予定です
価格
入力 $10/出力 $50(100万トークンあたり)。プロンプトキャッシュで入力90%割引
Opus 4.8($5/$25)の2倍、Sonnet 4.6($3/$15)の3倍超
Claude.ai 上では利用枠を2倍消費します
Opus 4.7→4.8 が「性能向上・価格据え置き」だったのに対し、今回は明確な値上げです。
【実戦検証】長時間・複合タスクを3件、丸ごと任せる(AGIラボ実機)
検証A:継続ベンチ「自転車に乗るペリカンの SVG」
AGIラボでは、GPT-5.4・Opus 4.7・Opus 4.8 の各記事で同じプロンプト(「森の中を自転車に乗って走るペリカンの、超詳細な SVG アニメーション」)を使い続けています。公式ベンチに含まれず、視覚設計のセンスと細部の制御力が出る試験として、世代間の比較がしやすいためです(元ネタは Simon Willison 氏の定番ベンチマークです)。
今回も同一プロンプトを、クリーンな文脈の Fable 5 に既定設定・1発出力で投げました。

実際の動きは GIF (4秒ループ)。

ソースコードをfable-5に解説してもらったところ、ペダルを漕ぐ脚を逆運動学(IK)で計算し、車輪の半径から算出した進行距離を地面のスクロール速度と同期させる処理が行われていました。
「車輪が滑らずに走る」ことがコードレベルで保証されています。背景は7層のパララックス構造で、まばたきや土埃など約35のアニメーションが実装されているようです。
一方で、胴体部分の描写にはブレが見られます。「1枚絵」としての完成度は Opus 4.8(xhigh)に軍配が上がると感じました。
追加検証では、ライダーのパーツ一式が画面左上へと飛んでいく、描画の崩壊が確認されました。

原因は、位置決めの transform 属性が CSS アニメーションによって上書きされるという、SVG特有の古典的なバグにあるようです。
静的解析では検知できないタイプのエラーです。3回の試行で結果は「良・可・破綻」が1回ずつ。凝ったロジックを組むほど、こうした罠に陥りやすい傾向があります。
検証B:マッキンゼーのレポートを渡して「同レベルを作って」
もう1件はコンサルティングファームの公式レポート PDF を渡し、「これと同レベルのレポートを作成してほしい」とだけ指示する検証です。構成力、データの扱い、図表、長工程の一貫性が全部問われます。
原本は McKinsey 公式配布の「The state of AI in 2025」(2025年11月、32ページ)。
テーマには今回の主題そのものを選び、「フロンティアモデルの二層化と企業の AI エージェント戦略」というレポートをサブエージェントの Fable 5 に依頼しました。条件は2つ。チャートはすべて自前で描く(インライン SVG)こと、架空の数値を一切使わないことです。

全文はこちら:
結果は、A4縦11ページ、Exhibit 7点、所要約8分。表紙、Key findings、本文4セクション、提言、出典一覧という構成で、サイドバーや全ページのフッター免責文まで自分で入れてきました。
検証C:「Harder, Better, Faster, Stronger っぽい曲を作って」
3件目は創作タスクです。claude.ai のウェブ版で、「Harder, Better, Faster, Stronger ぽい30秒のメロディーを作成して。Artifactsで再生可能な形式で出力して」という、俗なプロンプトを投げてみました。
出来上がったのがこちら:
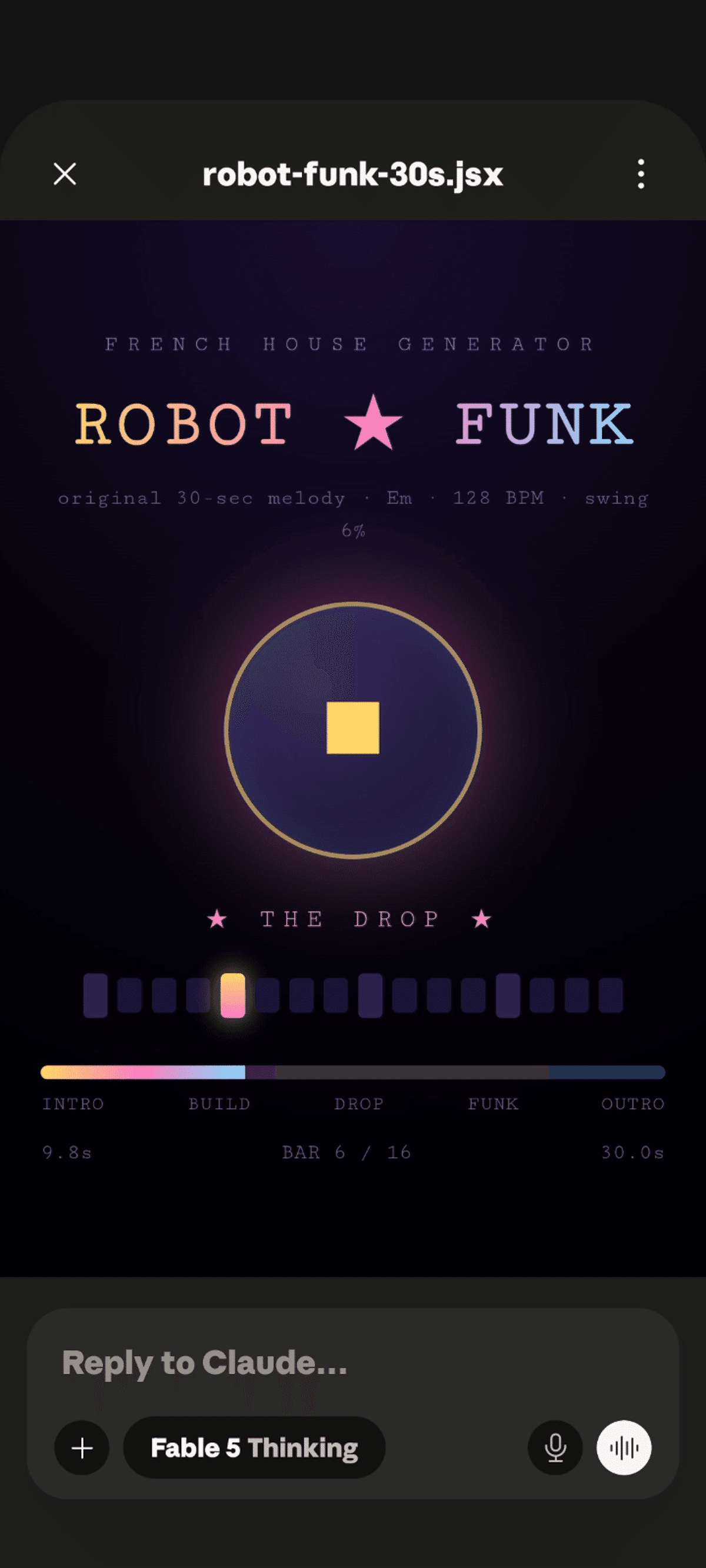
ほぼワンショット+数回の調整でこのクオリティ、というのが驚きです。ただし、音楽の専門家ではないので、プロ視点の意見をぜひコメントで教えてください。
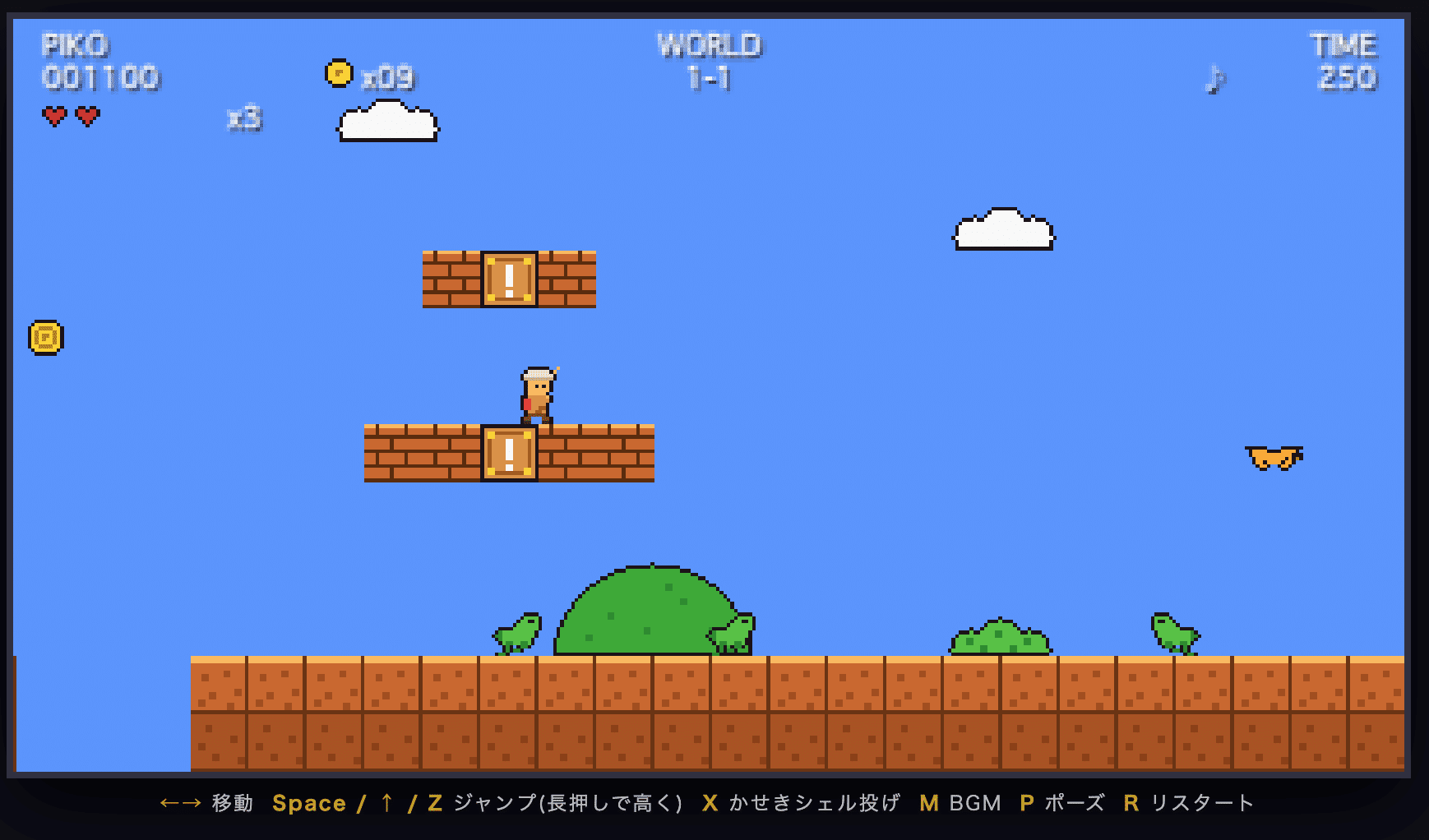
コミュニティでの検証:マリオ風ゲームの一発生成
AGIラボのDiscordでも、リリース当日から検証報告がありました。マリオ風のゲーム制作を依頼したところ、一発で遊べるものが生成されたとの報告です。
Opus 4.8のときに見られた「ジャンプ力が足りずブロックに登れない」といったゲーム性の不具合が、今回は出なかったとのことです。
一方で消費は激しく、「あっという間に12%消費」、さらに調整の途中でOpus 4.8への自動切り替えも経験しています。本記事で見てきた「品質・消費・フォールバック」の三点が、1つの検証に揃った例です。
まとめ
Fable 5 は「Opus 4.8 の上位互換」ではありません。日常の大半のタスクでは、速くて半額の Opus 4.8 が引き続き合理的です。変わったのは、数時間〜数日かかる仕事を、途中確認なしで丸ごと任せるという選択肢が現実的になったこと。外部評価6件の一致と、「11ページのレポートが8分で、破綻なく」という実機の体験は、その方向を裏づけていました。
試すなら、6月22日までの無料提供期間に、いつもなら分割して指示する大きめの仕事を1件だけ丸投げしてみてください。短い質問では、おそらく違いは分かりません。
残る宿題は、利害から独立した長時間検証(Andon Labs の Vending-Bench など)と、セーフガード誤発動の実際の頻度です。
残る宿題は、利害から独立した長時間検証(Andon Labs の Vending-Bench など)と、セーフガード誤発動の実際の頻度です。
リリースから数時間検証した限りでは、まず図解の精度が非常に高いと感じます。この記事の図もグラフも Fable 5 が描きましたが、数値の誤りやレイアウト崩れを直す手間がほぼ発生しませんでした。並行して作成させたビジネスレポートも、ローカルデータから緻密に情報を拾い、旧モデルで起きていたエラーもなく迅速に仕上がっています。
ただ、現時点での検証はごく一部に過ぎません。このモデルの本領が「数日にわたる業務」にあるなら、真の評価には時間が必要であり、本記事はその入り口にすぎないからです。むしろ課題は人間側にあります。AIに丸ごと任せるなら、仕事の切り出し方やワークフローから見直すべきでしょう。Anthropic 社員が語る「働き方の変化」を自分自身が実感し、言葉にできるまで使い込んでから、改めて続報をお届けします。
制作ノート:この記事自体も Fable 5 が作っています
最後、この記事は Claude Fable 5 によって執筆・制作されました。AGI Cockpit 上で Master Agent として起動され、過去記事665本の分析、一次情報の収集と照合、図解の作成、2件の検証のディレクション、本文の執筆とセルフレビューまでを、人間の途中確認なしで行っています。
AGIラボについて
この記事のように「AI エージェントを実務でどう使い倒すか」を、AGIラボでは日々検証しています。
記事:日刊AI新聞と、深掘りの検証記事
ツール:AGI Cockpit / AGI Gestures / GAS Interpreter(Claude Code・Codex・Gemini を一画面で並行運用)
コミュニティ:Discord・Meetup・ハッカソン
講座:Claude Code 入門ほか、実践で学べるオンライン講座
7日間は無料で試せます。→ https://agi-labo.com
参考リンク
公式
Claude Fable 5 and Claude Mythos 5(Anthropic): https://www.anthropic.com/news/claude-fable-5-mythos-5
Claude Fable プロダクトページ(Anthropic): https://www.anthropic.com/claude/fable
外部評価
Vibe Check: Fable 5 Is the Best Coding Model in the World(Every.to): https://every.to/vibe-check/anthropic-mythos-our-fable-vibe-check
Cursor 公式 X(CursorBench 72.9%): https://x.com/cursor_ai/status/2064394824313376787 / docs: https://cursor.com/docs/models/claude-fable-5
Fable 5, Now Available in Harvey(Harvey): https://www.harvey.ai/blog/fable-5-now-available-in-harvey
Claude Fable 5 & Mythos 5: The Frontier, Split in Two(digitalapplied.com・ベンチ集約): https://www.digitalapplied.com/blog/claude-fable-5-mythos-5-release-benchmarks-2026
報道・コミュニティ
Anthropic releases Claude Fable 5 days after warning(TechCrunch): https://techcrunch.com/2026/06/09/anthropic-released-claude-fable-5-its-most-powerful-model-publicly-days-after-warning-ai-is-getting-too-dangerous/
Hacker News スレッド: https://news.ycombinator.com/item?id=48463808
Andrej Karpathy 氏の投稿: https://twitter.com/karpathy/status/2064409694761054332
Claude Fable 5 generally available for GitHub Copilot(GitHub): https://github.blog/changelog/2026-06-09-claude-fable-5-is-generally-available-for-github-copilot/
検証素材
McKinsey「The state of AI in 2025」(公式PDF・検証Bの参照原本): https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai





