

日本時間2025年3月26日、OpenAIはChatGPTの基盤モデル「GPT-4o」に、ネイティブな画像生成機能を統合し、一般提供を開始しました。
今回のアップデートは単なる画像生成機能の追加ではなく、言語モデルの中核的な機能として画像生成を位置づける、非常に重要なアップデートです。特にテキストのレンダリング精度や複雑な指示への対応力が飛躍的に向上し、従来難しかった実用的な表現が可能となりました。
AIによるクリエイティブな画像生成が新たな段階に進んだことを実感できる、画期的な進化を遂げています。

GPT-4oによるネイティブ画像生成機能の詳細
今回のアップデートで最も大きな特徴は、画像生成能力がGPT-4oモデル自体にネイティブに組み込まれた点です。テキストと画像の連携がよりスムーズになり、以下の機能向上が実現しています。
特徴:
高精度なテキストレンダリング: 画像内に、標識、メニュー、手書き文字、ロゴやテキストを、自然かつ正確に描画できるようになりました。これまで難しかった表現が可能になります。

複雑な指示への追従性向上: 複数のオブジェクト(OpenAIによると10〜20個程度)の配置、属性、関係性を細かく指定したプロンプトに対応できるようになりました。

マルチターン対話による画像編集: チャット形式で対話を重ねることで、生成した画像を段階的に修正したり、洗練させたりできます。例えばキャラクターデザインで、一貫性を保ったまま試行錯誤を繰り返せます。


インコンテキスト学習: ユーザーがアップロードした画像をGPT-4oが理解し、そのスタイルや詳細情報を参照して新たな画像を生成できるようになりました。既存のビジュアル要素をもとにした制作ができるようになります。

世界知識の活用: GPT-4oが持つ広範な知識を、画像生成に直接利用できるようになりました。例えば、提示されたコードを解釈して3Dシーンを描画したり、複雑な科学実験を図解したり、レシピを視覚化したりできます。

フォトリアリズムと多様なスタイル: 写実的な画像生成能力に加え、漫画、水彩、レトロ印刷風など、非常に多様なスタイルでの画像生成や、既存画像のスタイル変換にも対応しています。


実用性を高める「有用な」画像生成の例
今回のアップデートでは、単に美しい画像を作るだけでなく、コミュニケーション、説得、分析といった目的に役立つ「使える」画像の生成に重点が置かれています。以下にその具体例を挙げていきます。
ホワイトボードの再現: 手書きメモや図を含むホワイトボードの様子をリアルに生成できます。会議の記録やアイデアの視覚的な共有に活用できるでしょう。

クリエイティブなテキスト表現: 文字そのものをデザイン要素として使うアート(具体詩など)や、画像内のテキスト配置によって意味を強調する表現も可能です。

マンガ・イラスト制作支援: 複数コマのマンガ制作や、キャラクターデザインを繰り返し試すといった用途に利用できるでしょう。

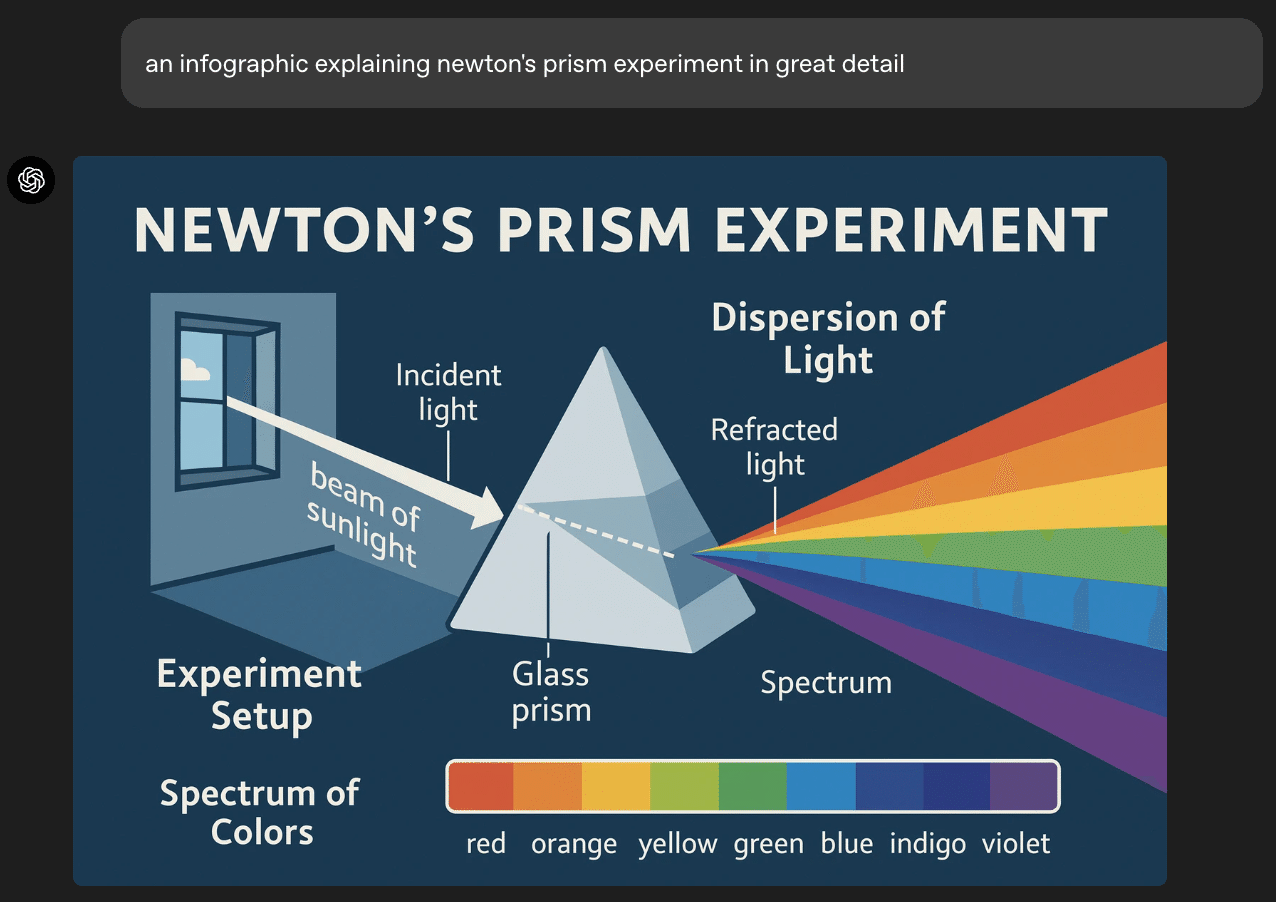
インフォグラフィック・説明図: 科学的な概念(ニュートンのプリズム実験など)や、特定の現象(サンフランシスコの霧の発生メカニズムなど)を、視覚的に分かりやすく解説する図を作成できます。
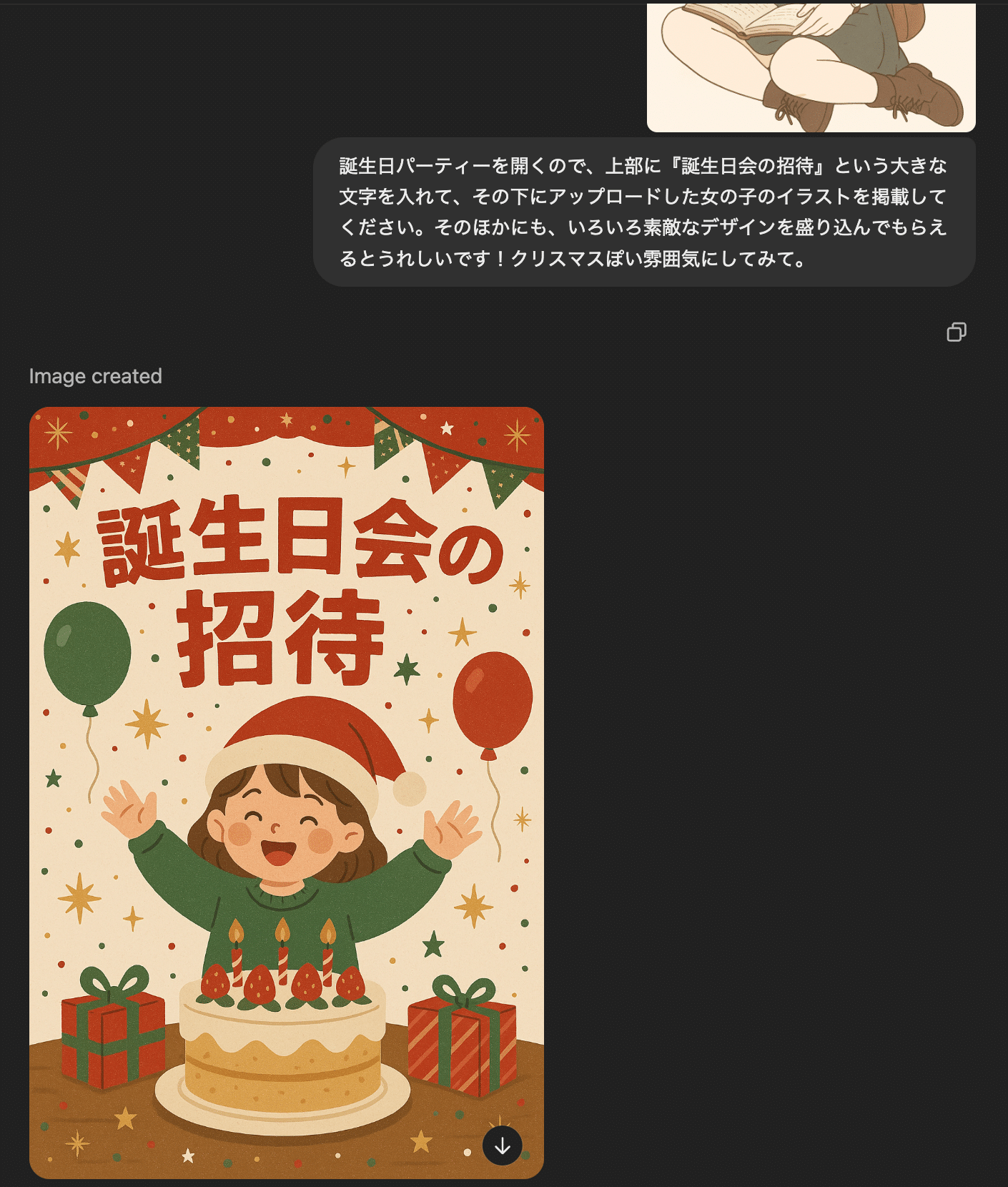
デザイン・広告制作: 料理イラスト入りのメニューデザイン、招待状のデザイン、キャッチコピーを含む広告用ビジュアルなどを、テキストによる指示ベースで作成できます。
ゲーム開発: キャラクター、UI要素、背景アートなどを、一貫性を保ちながら対話形式で生成・編集できるようになりました。

アクセスと使い方
GPT-4oの新しい画像生成機能は、発表日である本日3月26日から順次利用可能になっています。
提供開始と対象ユーザー:
ChatGPTのPlus, Pro, Team, そしてFreeプランのユーザーには、デフォルトの画像生成機能として段階的に展開されます。
Enterprise および Edu プランのユーザーへの提供は、近日中に開始される予定です。
開発者向けAPI:
開発者の方は、API経由でもGPT-4oの画像生成機能を利用できるようになります。こちらの提供は、今後数週間以内に開始される見込みです。
既存のDALL·Eについて:
従来のDALL·Eモデルを使いたい場合は、専用の「DALL·E GPT」から引き続き利用可能です。
利用方法:
画像の作成やカスタマイズは、ChatGPTとのチャット形式で行えます。
生成したい内容を記述する際、アスペクト比、特定の色(HEXコードでの指定も可)、背景透過といった詳細な指定も可能です。

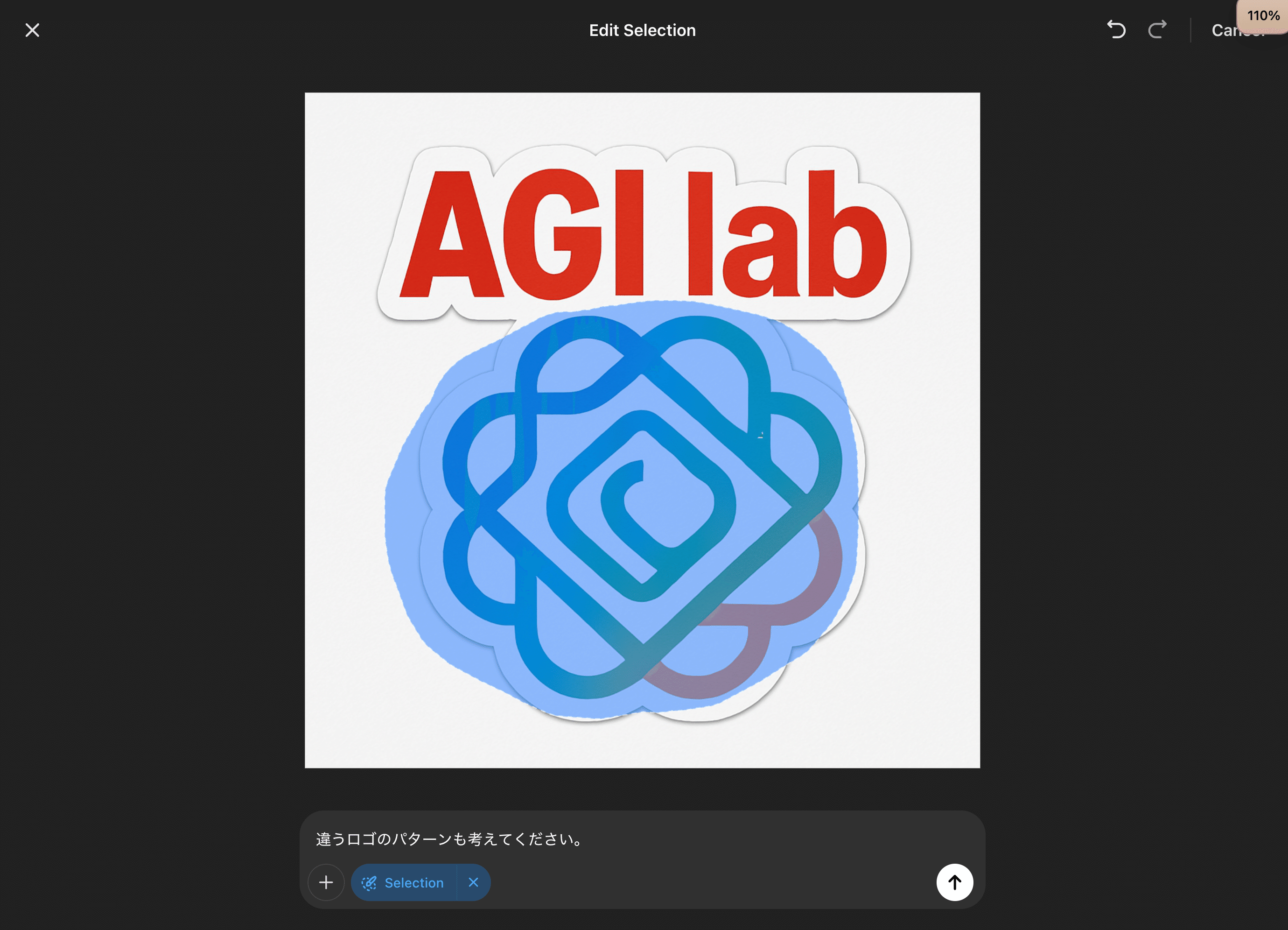
生成された画像をクリックして、編集したい部分を塗りつぶし、詳細な変更指示を追加することもできます。例えば、「違うロゴデザインにして」「この猫ちゃんに帽子を被せて」のように、具体的な変更を指示することが可能です。

Sora.com での利用:
この新しい画像生成機能は、動画生成モデルSoraのプラットフォーム (sora.com) でも利用可能です。
ChatGPTのPro, Plus, Team, そしてFreeプランのユーザーがSora上で画像を生成できます(Freeユーザーは1日に生成できる画像数に制限があり、動画生成機能を利用するには有料プランへの加入が必要です。)
Sora上では、生成した画像をシームレスに動画生成へ連携できる点が特徴です。
Soraのインターフェース内で、生成画像に対して「Remix」機能で編集指示を出したり、「Create video」を選択して動画化を開始したりできます。
※ 注意点:
より詳細な画像を生成するため、画像のレンダリングに時間がかかる場合があります。OpenAIによると、最大で1分程度かかることもあるようです。
既知の限界と今後の改善点
OpenAIは、今回のGPT-4o画像生成機能にもいくつかの限界点があるとしており、今後のモデル改善を通じて対処していくとしています。
主な課題:
クロッピング: ポスターのような縦長の画像を生成する際、特に下部が不自然に切り取られてしまうことがあります。

ハルシネーション: 他のテキストモデルと同様に、特に情報が少ないプロンプト(低コンテキスト)の場合、事実に基づかない情報を生成してしまう可能性があります。
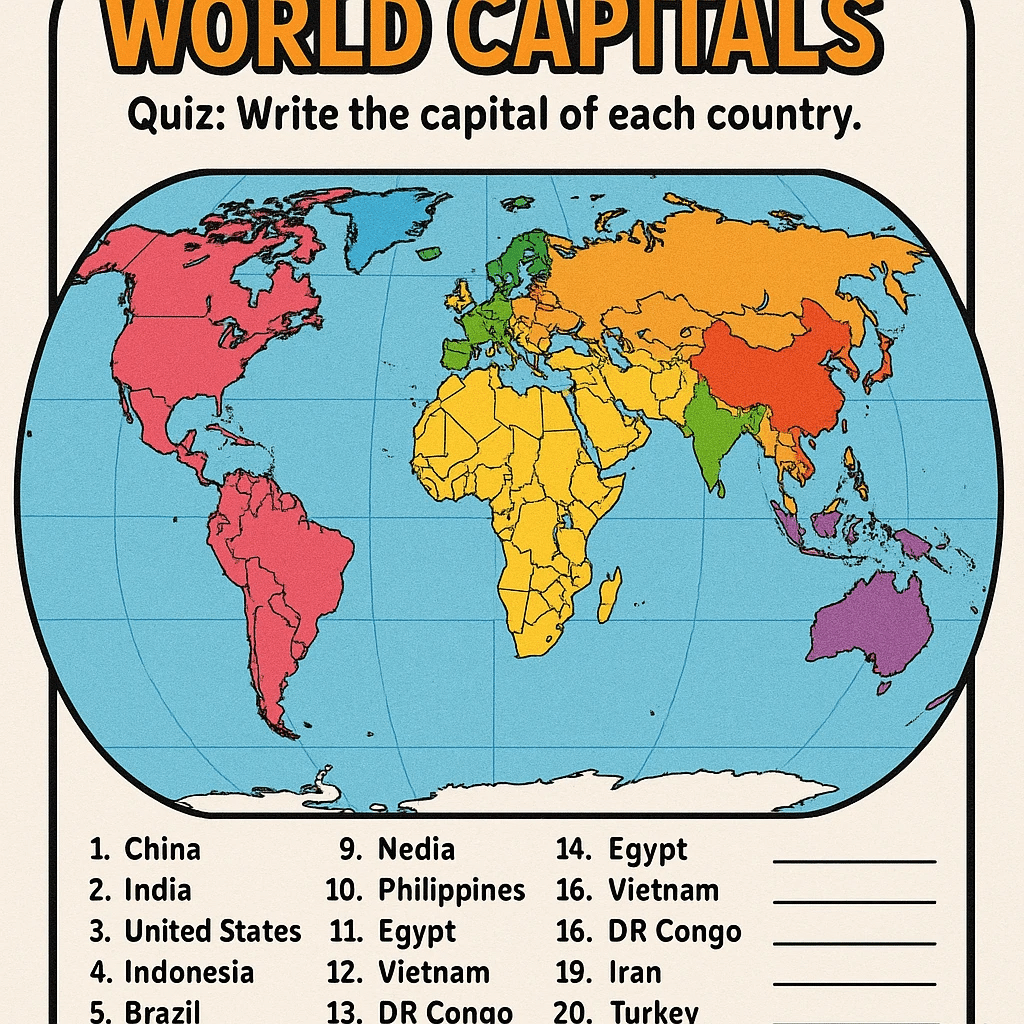
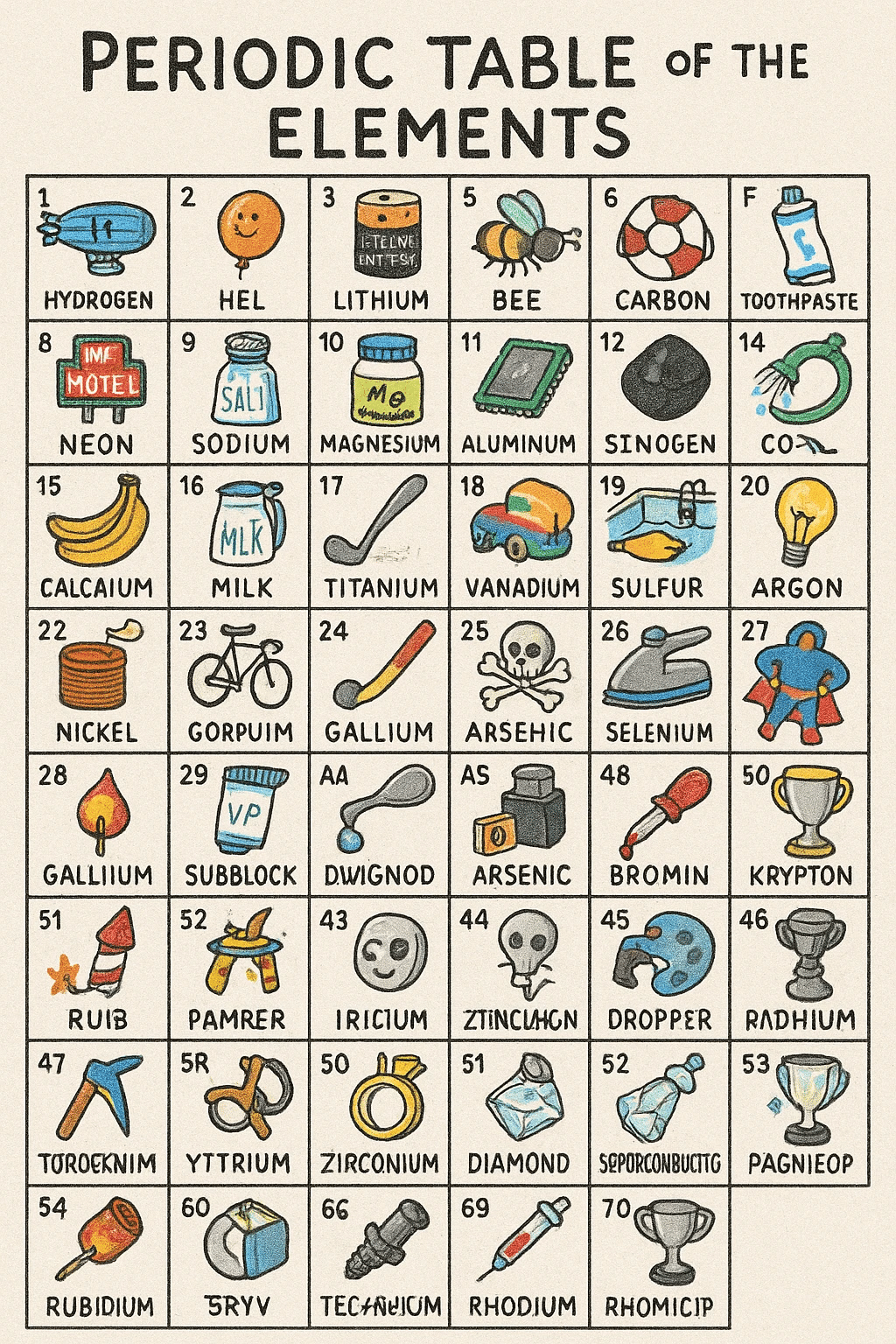
高密度情報のレンダリング: モデルの知識ベースに依存する画像を生成する際、10〜20を超えるような多数の異なる概念を一度に正確に描画するのは難しい場合があります(例えば、完全な周期表など)。
多言語テキスト: ラテン文字以外の言語のレンダリングには苦労することがあり、文字が不正確になったり、存在しない文字を生成したりする場合があります。これは、複雑さが増すほど顕著になる傾向があります。

編集精度: 生成された画像の一部(例えば誤字)を修正するよう指示しても、必ずしも完璧に修正できないことがあります。また、指示していない部分まで変更してしまったり、新たな間違いを発生させたりすることもあります。
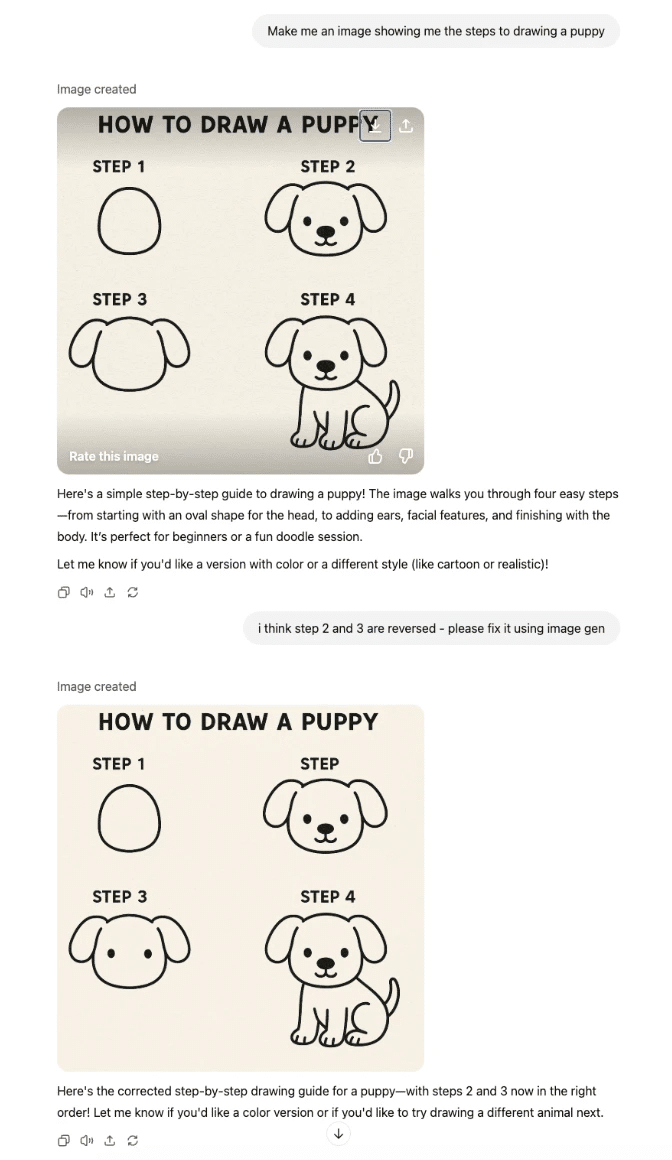
微細なディテール: 非常に小さいサイズで詳細な情報を描画するように求められると、うまく表現できません。

日本語の生成: 日本語のレンダリング精度は従来モデルより大きく改善しました。短い単語や簡単な漢字は比較的正確に生成できますが、長文や複雑な漢字、細かな書式指定については依然として課題が残っています。


画像生成における表現の自由度について
今回のアップデートに関して、OpenAIのCEOであるSam Altmanや製品責任者のKevin Weilは、これが同社にとって創造的な自由を許容する上で「新たな高水準」 になる、とXで投稿しています。
https://twitter.com/sama/status/1904598788687487422
https://twitter.com/kevinweil/status/1904595752380465645
これらの発言からは、OpenAIがユーザーの意図をこれまで以上に尊重し、画像生成における表現の幅を広げようとしている姿勢がうかがえます。
OpenAIが定めるポリシーの範囲内に限り、従来難しかった表現も実現可能になっています。
ただし、生成されるコンテンツは、常にOpenAIが定める安全基準や、社会的に許容される範囲とのバランスの中で判断されるため、不適切なコンテンツの生成を防ぐための仕組みは引き続き機能します。
使用に関するポリシーが気になる方はぜひこちらからご覧ください。日本語で確認できます:
https://openai.com/ja-JP/policies/usage-policies
安全性への取り組み
OpenAIは、同社の「Model Spec」に沿って、創造的な自由を最大限サポートしつつ、厳格な安全基準を維持することを目指しています。ゲーム開発や教育といった価値あるユースケースを支援する一方で、ポリシーに違反するリクエストはブロックすることが重要であるとしています。
主な安全対策:
有害コンテンツのブロック: 児童性的虐待コンテンツ (CSAM) や同意のない性的ディープフェイクなど、OpenAIのコンテンツポリシーに違反する可能性のある画像生成リクエストは、引き続きブロックされます。
実在人物に関する制限強化: コンテキストに実在の人物の画像が含まれる場合、生成できる画像の種類にはより厳しい制限が課せられます。特に、ヌードや過度な暴力表現に関しては、堅牢な安全策が講じられています。
出所の透明性 (Provenance):
生成された全ての画像にはC2PAメタデータが付与されます。これにより、その画像がGPT-4oによって生成されたものであることが識別でき、透明性が確保されます。
また、OpenAIは内部的な検索ツールを構築しており、生成物の技術的属性を用いて、コンテンツが自社モデル由来かどうかを検証するのに役立てています。
より詳細なアプローチについては、以下で公開されているので気になる方はチェックしてみてください。
https://openai.com/index/gpt-4o-image-generation-system-card-addendum/
まとめ
今回のGPT-4oへのネイティブ画像生成機能の統合は、これまでの画像生成ツールとは明らかに一線を画す、大きなブレイクスルーを感じさせるアップデートでした。実際に試してみたり、ユーザーの反応を見たりしても、その変化を強く実感しています。
特に、日本語を含むテキストの描画精度が飛躍的に向上している点や、チャット形式で具体的な指示を細かく反映できる柔軟性は印象的です。従来、画像生成領域ではOpenAIは競合に遅れを取っているという声もありましたが、今回のアップデートで一気に巻き返したと感じています。
また、安全性を維持しつつも、ユーザーの創造性を抑え込まない姿勢にも非常に好感を持ちました。今後のさらなる進化にも期待したいところです。





