

日本時間2025年12月17日、OpenAIは最新の画像生成モデル「GPT-Image-1.5」を発表しました。
前モデルと比較し、生成速度が最大4倍に向上。指示追従性、編集の精密さ、そしてテキストレンダリング能力の大幅強化が強調されています。
本記事では、GPT-Image-1.5のモデル概要、API仕様・価格、そして実際に検証した結果をまとめます。
要点:
GPT-Image-1.5発表。 生成速度が最大4倍向上し、指示に対する忠実度とテキスト描画能力が大幅に進化。
「意図通り」の精密な編集。 人物の顔立ちや全体の構図、照明を維持したまま、指定した要素のみを追加・削除・変更する編集機能が実用レベルに到達。
APIは2系統:前モデル比で20%の低価格化を実現。
Images API:gpt-image-1.5 による単発生成・編集に対応
Responses API(image_generationツール):現時点は gpt-image-1 / gpt-image-1-mini のみ(gpt-image-1.5 は対応準備中)
GPT-Image-1.5の概要
指示追従性と生成スピードの進化
GPT-Image-1.5は、OpenAIの画像生成モデルの中で最も高性能な最先端モデルです。 最大の特徴は、ユーザーの意図を正確に汲み取る指示追従性(Instruction Following)の向上。
従来モデルで発生しがちだった「指示の一部が無視される」「構図が崩れる」といった問題が改善され、複雑なプロンプトでも忠実な出力が可能になりました。また、生成速度は最大4倍高速化されています。
高度な「編集」能力
「編集(Editing)」機能が大きく強化されました。 アップロードした画像のスタイルや、人物の顔、照明、構図といった重要な要素(Invariants)を維持しながら、「変えたい部分だけ」を正確に変更できます。
要素の追加・削除: 背景にオブジェクトを追加する、特定の物体を消す。
スタイル変換: 写真をイラスト風にする、あるいはその逆。
一貫性の保持: 編集を重ねても、被写体のアイデンティティが崩れにくい。

テキストレンダリング
画像内のテキスト描画能力向上も強調されています。 看板の文字、製品ラベル、インフォグラフィック内の説明文など、密度が高く小さな文字でも潰れずに生成可能になります。

左:従来モデル 右:新モデル
新機能:「Images」
ChatGPTのサイドバーに、画像生成に特化した「Images」セクションが追加されました。
過去の生成履歴へのアクセスや、フィルターのプリセットを使用できます。
提供形態とAPI情報
利用可能なプラットフォーム
ChatGPT: 順次提供開始(*研究所所有のアカウントでもすでに利用可能になっています)。新しいImagesタブ/My images は Free/Go/Plus/Edu/Pro で利用可能で、Business/Enterprise は後日対応予定。
API: gpt-image-1.5 として利用可能。
API機能と価格
Input Fidelity(入力忠実度): input_fidelity パラメータを high に設定することで、入力画像のディテール(顔やロゴなど)を強力に保持した編集が可能。
Multi-turn Editing: Multi-turn 編集(会話しながら段階的に改善)は Responses API で可能だが、現時点の対応画像モデルは gpt-image-1 / gpt-image-1-mini。gpt-image-1.5 は準備中と記載されています。
価格
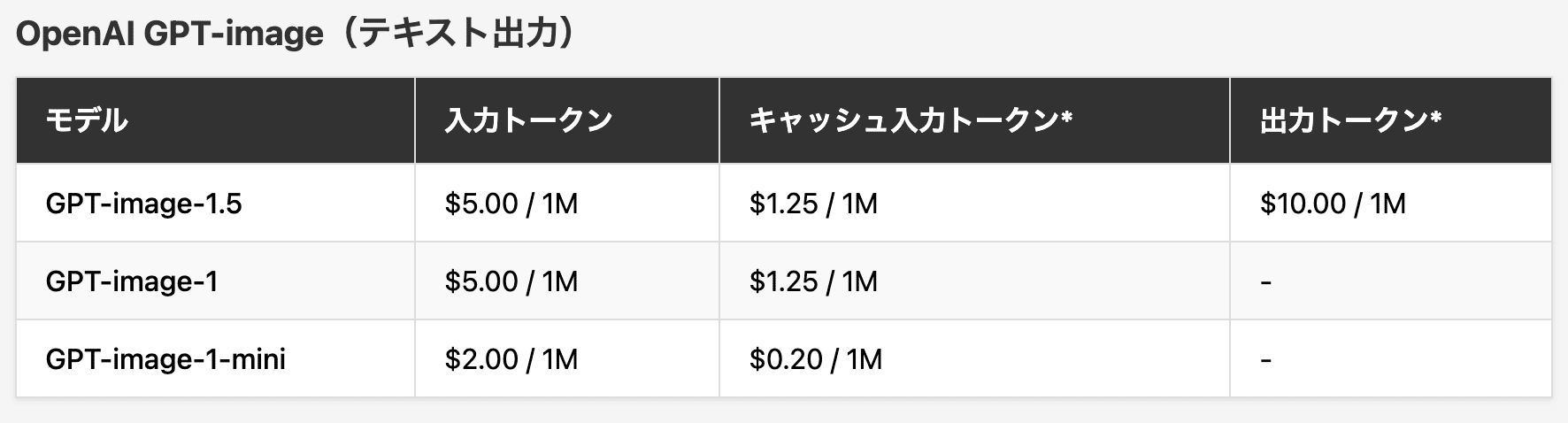
※ Responses API経由で利用可能
※ テキスト出力トークンにはモデルの推論トークンを含む
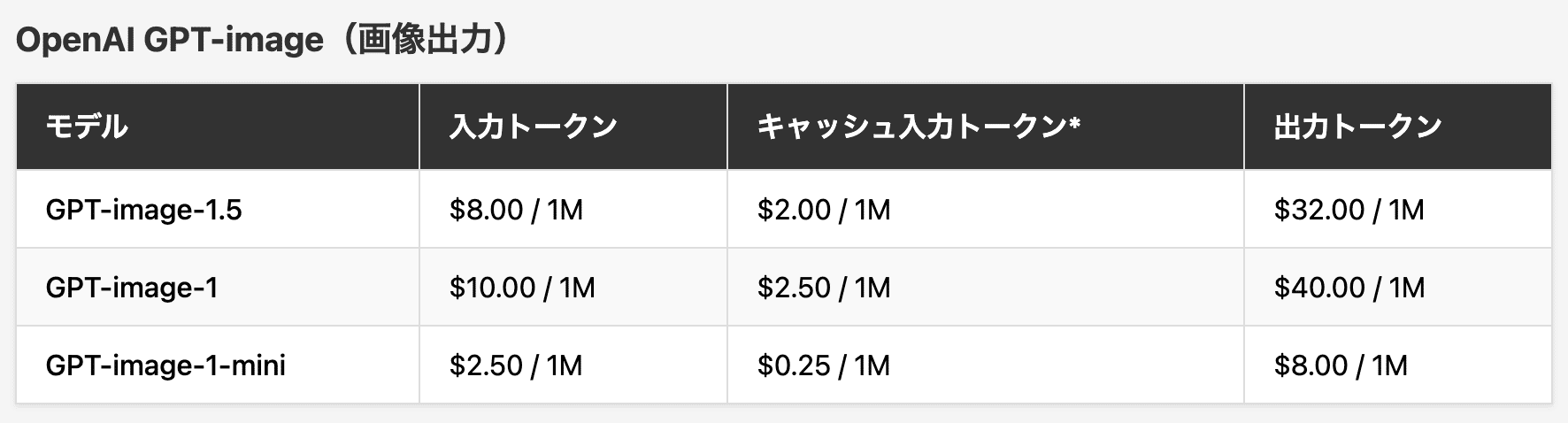
プロンプトは他のGPTモデルと同様に課金されます。
画像出力は正方形画像の場合、1枚あたり約 $0.01(low)、$0.04(medium)、$0.17(high)です。
Nano Banana Pro 🍌 の価格:

※ 画像を読み込む場合:約 $0.001 / 枚
※ 画像を生成する場合:約 $0.13〜0.24 / 枚(解像度による)
【検証】5つのクリエイティブなテストをやってみた
GPT-Image-1.5の性能を検証するため、人物の顔写真およびキャラクターなどを使用した5つのタスクを実施しました。
比較対象として、前モデルである「GPT-4o *こちらから利用」、およびGoogleの「Nano Banana Pro」出力も併記しました。
① IPキャラクターの実写合成
2Dのキャラクターイラストを、実写の風景(東京・表参道)に違和感なく合成できるかを検証します。
照明や影の落ち方を背景に合わせて調整しつつ、キャラクターのアイデンティティ(顔、髪型、特徴的な衣装)が維持されるかがポイントです。
添付画像:

プロンプト:
このキャラクターを、表参道にあるお洒落なカフェのテラス席に座らせてください。
条件:
・一貫性: 顔や髪型、衣装のデザインはそのままで維持してください。
・環境への馴染ませ方: 午後の自然な光に合わせて、影や光の反射もリアルに入れ、背景に自然に馴染ませてください。
・スタイル: 背景はスマホで撮ったような実写スタイル。キャラクターはフィギュアのような質感にし、「現実に存在しても違和感がない」レベルのリアリティを出してください。
実行結果:

GPT-Image-1.5は、キャラクターの「塗り」や「2Dらしさ」を完全に維持したまま、環境光だけを現実に馴染ませることに成功しました。「フィギュアが現実に存在している」ような絶妙なリアリティです。 対してGPT-4oは実写化(コスプレ風)しすぎてキャラクター性を失い、Nano Banana Proは切り貼り感が目立つ結果となりました。
② マルチターン編集
GPT-Image-1.5の真骨頂は、一度生成・編集した画像に対して、さらに指示を重ねていくマルチターン編集(Multi-turn Editing)にあります。
ここでは、実際の人物の顔写真を使い、まずは「バーチャル試着」を行い、そこからさらに「スタイルを変換」してみました。
Step 1:
まずは、以下の写真を「テックカンファレンスの登壇用ジャケットスタイル」へ変更してみます。
添付画像:

プロンプト:
服装だけを変更し、テック企業のCEOのような「洗練されたジャケットスタイル」にしてください。
維持する要素:顔、髪型、ポーズは全てそのままで。「私であること」は絶対に変えないでください。
変更する要素:服装のみ。高級感のあるネイビーのジャケットと白Tシャツの組み合わせに変更してください。服のシワや質感もリアルに表現すること。
光の当たり方は元の写真に合わせてください。首元のつながりも自然にし、「合成っぽさ」が出ないようにしてください。
実行結果(Step 1):

GPT-Image-1.5とNano、ほとんど顔のパーツや骨格を動かさず、首から下だけを完璧に差し替えました。4oは顔が変わってしまっています。
Step 2:
Step 1で生成された「ジャケット姿の人物」に対し、今度は大きくスタイル変換を指示しました。
プロンプト:
上記の人物を、1980年代のVHSフィットネス番組に出てくるような、象徴的なインストラクター風に変換してください。
顔の骨格や表情など、私らしさはそのまま維持してください。
顔には、当時の写真・映像らしい質感を直接反映させてください。
具体的には、やわらかなハレーション、わずかなぼかし、控えめなノイズ、軽い色にじみ、肌や輪郭にかかる繊細な走査線などです。
服装は、鮮やかな80年代のフィットネスウェアにしてください。
テリー素材のヘッドバンドやリストバンド、ネオンカラーがアクセントのスポーツウェアを取り入れてください。
髪型は、今の長さや質感を活かしつつ、80年代らしいボリューム感のあるスタイルにしてください。
全体の雰囲気に合う場合のみ、明るめのレトロメイクを加えても構いません。
照明はパステル調のスタジオライトにし、顔と体の雰囲気が揃うよう、全体に軽く劣化したVHS風の質感を統一して加えてください。
エアロビクスを指導している最中のシーンにしてください。
実行結果(Step 2-A):

GPT-Image-1.5は、「画質の劣化表現(VHSノイズ)」と「被写体の構造維持」を両立できてます。派手な衣装になっても「Step 1と同じ人物」と認識できます。 他モデルは顔が別人になってます。
③ 日本語広告クリエイティブの作成
画像生成AIが苦手とする「日本語テキスト」を含んだ広告バナーを作成します。
キャラクターを使用し、架空のイベントポスターを生成させてみました。
添付画像:

プロンプト:
このキャラクターを使用して、テックイベントの縦長ポスターを作成してください。
テキスト(一字一句正確に描画すること):
タイトル:「生成AIの未来」
サブタイトル:「AGILab 2025」
日付:「12月25日 開催」
デザイン指示:
スタイル:サイバーパンクでありながら、日本のミニマリズムも取り入れた、洗練されたモダンなデザインにしてください。
配置:キャラクターを中央に配置し、タイトルを上部に大きく、日付を下部に配置してください。
タイポグラフィ:太めのゴシック体を使用し、視認性を高くしてください。文字化けや不要な記号は絶対に入れないでください。
実行結果:

GPT-Image-1.5とNano Banana Proは、「生成AIの未来」といった漢字を崩さずに生成し、指示した世界観も維持してくれました。
④ 連続編集
生成→編集→要素追加→グッズ化→再帰的着用という、文脈を維持し続ける高度なタスクをテストしてみました。
Step 1: ベース画像の生成
プロンプト:
渋谷のスクランブル交差点で、ダイナミックにスケボーをしている瞬間を撮ってください。
スタイル指定:
90年代後半のドキュメンタリー風ストリートスナップ。
35mmフィルム(ライカM型 + 35mmレンズ)で撮影したような、Kodak Portra 400風の色味。
自然光、ソフトなコントラスト、フィルム特有の粒子感を入れて。HDRやデジタル的なシャープさは完全に排除してください。
実行結果(Step 1):

Step 2: 特定要素の編集
プロンプト:
彼のTシャツを鮮やかな「赤」に、被っているキャップを「黄色」に変えてください。 背景に走っている「日本のパトカー」を追加してください。
実行結果(Step 2):

「赤Tシャツ・黄キャップ・パトカー」への変更を同時に実行。特筆すべきは、指定していない部分(スケボーの角度や背景)がStep 1から完全に維持されている点です。
Step 3: カオスな要素の追加
プロンプト:
画像をもっと賑やかにして。
左側に、彼の技を見て驚いている外国人観光客の群衆を追加。
右側のガードレールの上に、「ハチ公(銅像ではなく本物の柴犬)」を座らせて。
遠くの空には飛行船を飛ばして。
実行結果(Step 3):

「群衆」「本物のハチ公」「飛行船」というカオスな要素を追加しても、ベースとなるスケーターの存在感は損なわれず、破綻しませんでした。 他モデルは、要素追加の影響でメインの人物が変わってしまったり(Consistency Failure)、空間認識がおかしくなる現象が見られました。
Step 4: 生成した画像を使った画像の生成
プロンプト:
今作ったこの画像が、前面にフルプリントされた「ストリートブランド風のパーカー」を作ってください。 そのパーカーが、白い壁の前のハンガーにかかっている写真にしてください。
実行結果(Step 4):

これは明確な差がでました。Nano Banana Proは Step 3の画像を素材として再利用し、パーカーのデザインとして生成するタスクにおいて失敗したところGPTの方は両モデルとも成功しています。1.5の方は、シワなどもリアルです。
Step 5: 再帰的な生成
プロンプト:
最初のスケーターの画像に戻って。 彼に、さっき作った「自分の写真がプリントされたパーカー」を着せてください。
実行結果(Step 5):

⑤ ウェブバナー作成
ウェブサイトのヒーローイメージやバナーとして即座に使用できるデザイン生成を検証してみます。
特定の構図(左に文字、右にイラスト)とスタイルを指定し日本語テキストも生成してもらいます。
添付画像:

プロンプト:
添付画像のテイストで、横長16:9(1200×675)のバナーを生成してください。 左に大きく「施工後もずっと安心サポート」。 下に小さく「定期点検で見守ります」。 右に、カレンダーのフラットイラスト+手(実写風・手だけ)がチェックを入れている表現。アクセントはオレンジ、背景は白い紙。
実行結果:

全モデルが「左に文字、右にイラスト」という構図指定を厳守しています。ただ、画像全体の綺麗さでいえば1.5が優勢という印象です。
まとめ
実際にGPT-Image-1.5を検証して感じたのは、「画像生成自体のクオリティ」と「編集における圧倒的な一貫性(Consistency)」の高さです。
テキスト描画の精度に関しては、前モデルからの飛躍的な進化というよりは着実なアップデートという印象で、純粋な文字生成においてはNano Banana Proに軍配が上がる場面もありました。
しかし、Nano Banana Proが編集を重ねると指示を無視したり、整合性が崩れたりする(いわゆる「頭が悪くなる」ような挙動を見せる)のに対し、GPT-Image-1.5はどれだけ編集を重ねても文脈を見失いませんでした。
特に、人物の顔や固有の特徴を維持し続ける能力は他を圧倒している印象です。





