

いよいよ、正式発表されました!
2026年4月23日(日本時間4月24日)、OpenAI が GPT-5.5 を公開。コードネーム "Spud(スプッド)" と呼ばれてきた、2年かけてベースモデルから作り直された新世代モデルです。Co-founder の Greg Brockman 氏は「単なる改良ではなく、big model feel がある」と表現しています。
本記事では、今回のアップデートで何が変わったのかを整理します。

要点
・GPT-5.5 は長い仕事を任せるモデルとして位置づけられている。調査・実装・自己確認・継続実行に寄った強化がされた。
・ChatGPT と Codex にロールアウト。API は GPT-5.5 / GPT-5.5 Pro ともに近日提供予定 (coming soon)。
・API 価格は GPT-5.4 の2倍。入力 $5 / 出力 $30 per 1M tokens。一方でタスクあたりのトークン使用量は減る場合もあるとされる。
・全方向で勝っているわけではない。SWE-Bench Pro や MCP Atlas などでは Claude Opus 4.7 が上回る。
・サイバー・バイオ能力は Preparedness Framework 上 High。Critical ではない。アクセス制御と safeguards が強化された。
GPT-5.5 は何のモデルか
OpenAI はコンピュータ上で複雑な仕事を進めるためのモデルとして GPT-5.5 を説明しています。強調されているのは、目標理解、ツール利用、自己確認、継続実行です。
実務でのイメージとしては、次のような作業が想定されています。
・大きなコードベースを調査し、修正し、テストまで進める
・複数のツールや資料を横断してリサーチする
・スプレッドシートや資料を生成・編集する
・研究データの分析を補助する
・コンピュータ操作を含む手順を実行する
GPT-5.5 Pro はさらに推論を厚めに振ったバージョンで、ChatGPT Pro / Business / Enterprise で利用できます。
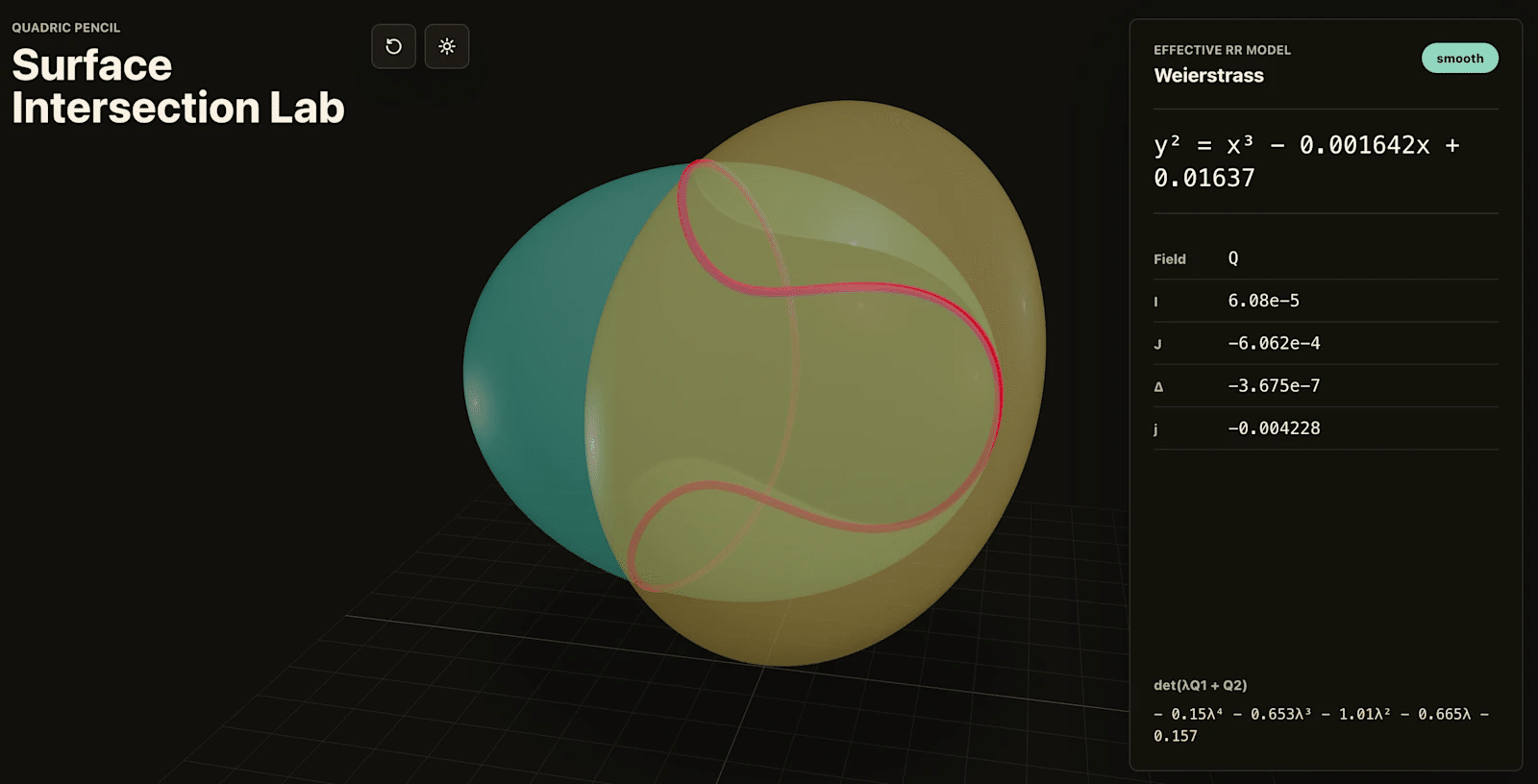
上の Surface Intersection Lab は公式ブログで紹介されている、かなり専門的な数学の例です。「2つの立体がぶつかったとき、その交わる線がどういう形になるのか」を画面上で動かしながら調べるためのツールです。そこから Weierstrass 形式という数学的な表現へ変換するところまで含まれています。
ベンチマークから見える変化
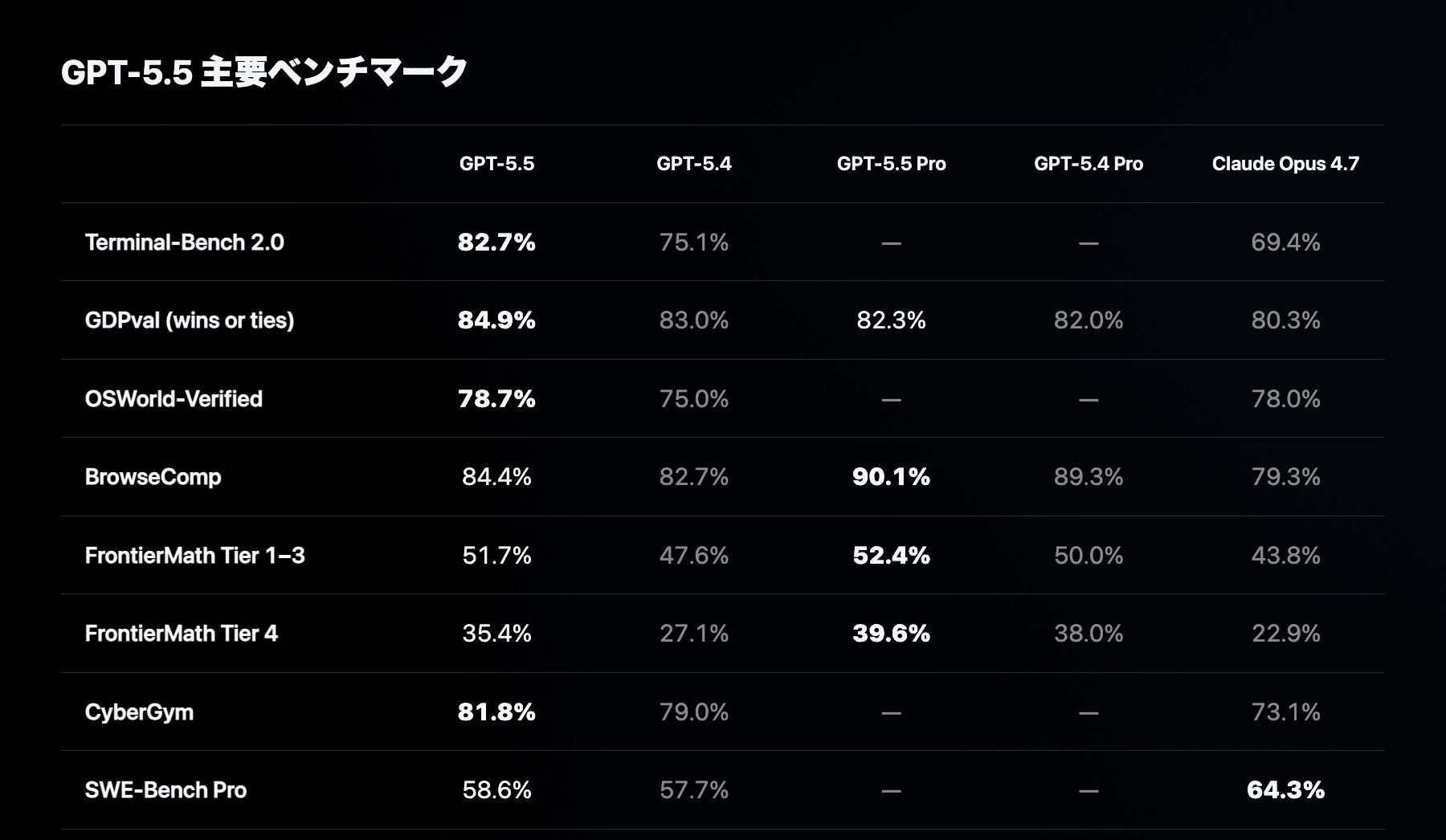
・Terminal-Bench 2.0: 82.7% (GPT-5.4 は 75.1%)。CLI 上で計画・実行・修正を行うタスク。Codex と相性がよい指標。
・GDPval (wins or ties): 84.9% (GPT-5.4 は 83.0%)。44職種の実務成果物を比較した評価。
・OSWorld-Verified: 78.7% (GPT-5.4 は 75.0%)。実際のコンピュータ環境の操作評価。
他にも ARC-AGI-2 Verified が 73.3% から 85.0%、CyberGym が 79.0% から 81.8% に伸びています。いずれも短い一問一答ではなく、長い作業を進める力を測る指標です。
注意点として、OpenAI はこれらの評価を reasoning effort xhigh の研究環境で実施したと説明しています。普段の ChatGPT と完全に同じ出力ではない可能性があります。
Opus 4.7 に負けている領域
同じ公式ブログを素直に読むと、全方向で勝っているわけではないことも分かります。
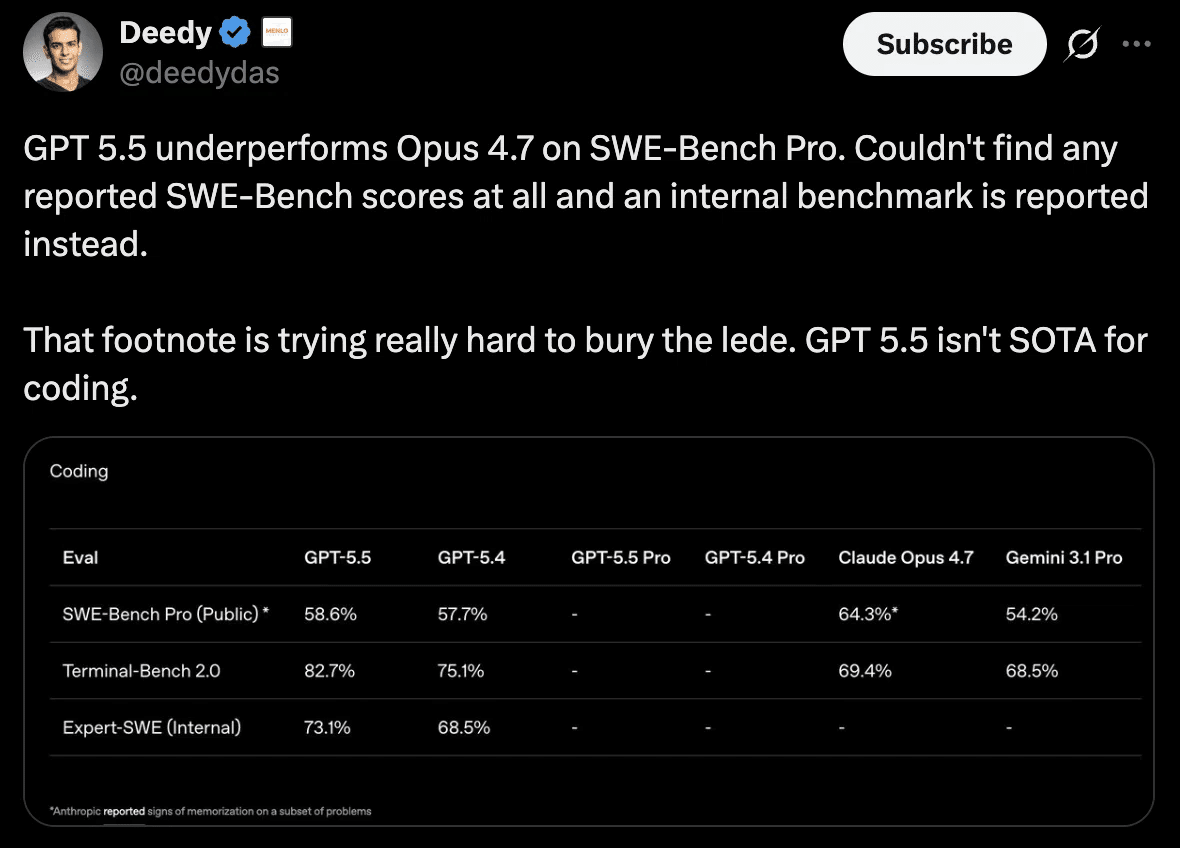
・SWE-Bench Pro: GPT-5.5 58.6% / Claude Opus 4.7 64.3%
・MCP Atlas: GPT-5.5 75.3% / Claude Opus 4.7 79.1%
・FinanceAgent v1.1: GPT-5.5 60.0% / Claude Opus 4.7 64.4%
・Humanity's Last Exam (no tools): GPT-5.5 41.4% / Claude Opus 4.7 46.9%
SWE-Bench Pro は実際の GitHub イシュー解決に近い、長めのコーディング評価です。ここで Opus 4.7 が上回っています。評価軸によって得意不得意は分かれます。
なお SWE-Bench Pro 自体には、運営側からモデルの memorization が結果に影響している可能性があるという指摘も出ています。数字は評価条件とセットで読む必要があります。
Mythos Preview まで入れると、見え方が変わる
Claude Mythos Preview まで含めてみます。
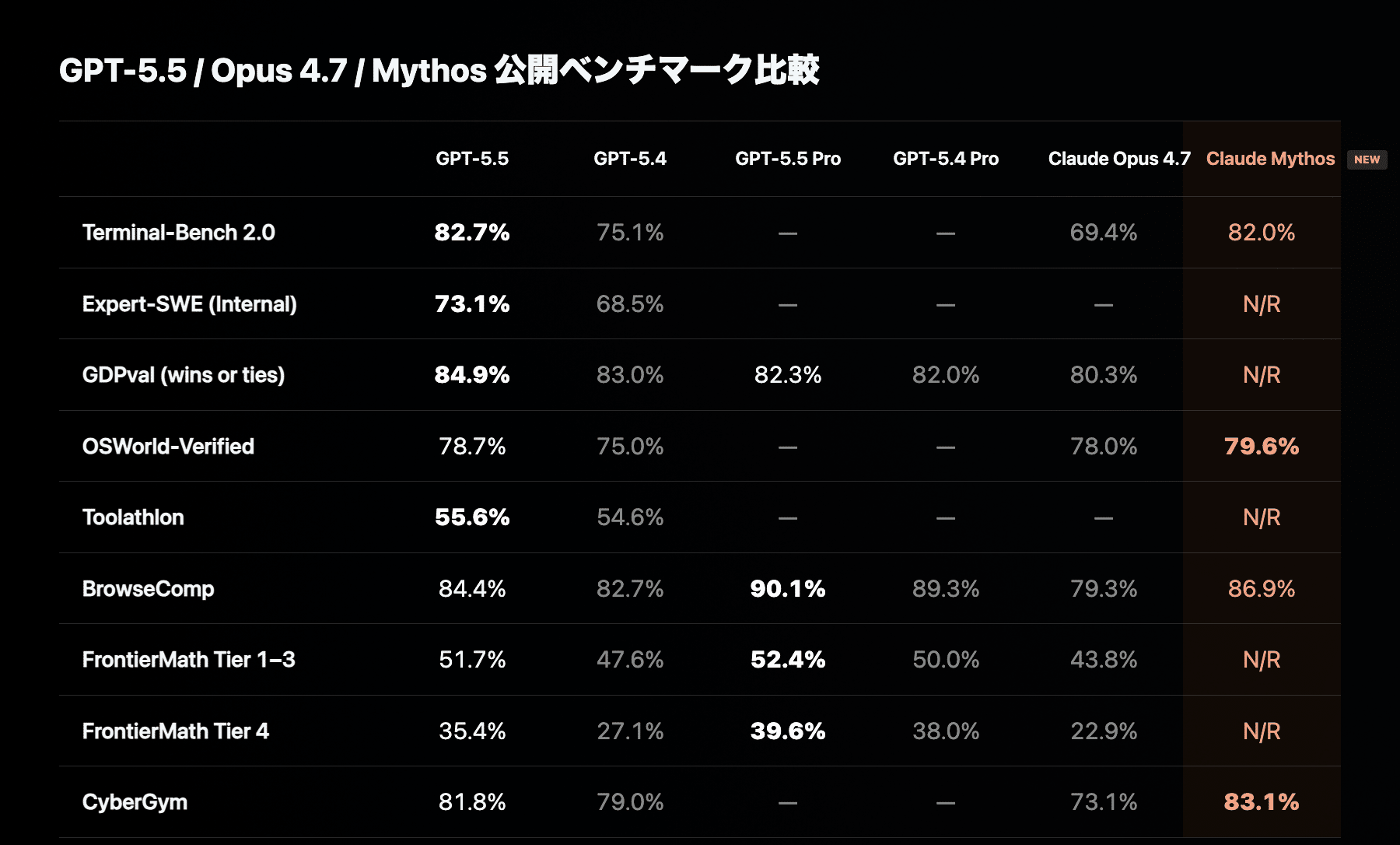
Mythos は Terminal-Bench 2.0 では GPT-5.5 にわずかに届かない一方、OSWorld-Verified、CyberGym などでは上回っています。
※ ただし、Mythos Preview は Project Glasswing 向けの限定プレビューで、一般利用できるモデルではありません。
提供形態と価格
提供形態
・ChatGPT Plus / Pro / Business / Enterprise に GPT-5.5 Thinking
・GPT-5.5 Pro は ChatGPT Pro / Business / Enterprise
・Codex は Plus / Pro / Business / Enterprise / Edu / Go
・Codex のコンテキスト長は 400K トークン
・Codex Fast mode は 1.5倍速、2.5倍コスト
・API は GPT-5.5 / GPT-5.5 Pro ともに coming soon
API は現時点で一般提供されていません。
API価格
API Pricing ページ上で GPT-5.5 は coming soon 表示です。掲載されている予定価格は以下です。
・GPT-5.5: 入力 $5.00 / 1M tokens、キャッシュ入力 $0.50 / 1M tokens、出力 $30.00 / 1M tokens
・GPT-5.4: 入力 $2.50 / 1M tokens、キャッシュ入力 $0.25 / 1M tokens、出力 $15.00 / 1M tokens

単価は GPT-5.4 のちょうど2倍です。
ただし OpenAI は、Codex タスクではより少ないトークンで完了する場合があるとも説明しています。単価ではなく、タスクあたりの合計コストで比較する見方も必要そうです。
アーリーテスターの声
ここからは早期アクセスを得たアーリーテスターの X 投稿を紹介していきます。
Theo: 強いが、扱いが難しく、高い
日本語訳:
入力100万トークンあたり5ドル、出力100万トークンあたり30ドル。
GPT-5.5 は賢いです。しばらく使ってきました。変わっていて、扱いが難しく、高すぎるとも感じます。
これまで使ったどのモデルよりも良いコードを書けます。ただし、かなり励ましが必要です。文脈は以前にも増して重要で、十分に厳密な指示を与えないと探索し始めます。何か間違いを見つけると、そこから方向修正するのが難しく感じられます。

Dan Shipper: 3週間使って見えた強みと弱み
要約訳:
Every 社内では3週間、GPT-5.5 をコーディング、執筆、知識労働でテストしてきました。コーディングでは段差を感じる変化があり、会話しやすい。速く、親しみやすく、すぐに日常使いになりました。
社内の Senior Engineer ベンチマークでは GPT-5.5 が 62/100、Claude Opus 4.7 が 33/100 でした。ただし、GPT-5.5 は Opus 4.7 が作った計画を使ったときに最も良かった、という注記も付けています。
弱みも書かれています。
計画の質ではまだ Opus 4.7 が上回る。フロントエンドやフルスタックのプロダクト作業では Opus 4.7 の方が少し強い。曖昧な vibe coding では Opus の方が行間を読むとも指摘されています。
Cheng Lou: PR 説明からの再実装、2週間走るセッション
日本語訳:
ここ数週間、GPT-5.5 を試す機会がありました。
Pretext のリポジトリで、プルリクエストの説明だけを読ませ、それを再実装させてみました。毎回、GPT-5.5 は元の PR 実装よりずっと良いコードを書きました。
トークン効率の良さもかなり明確で、反復速度は上がるはずです。Codex の compaction も良く、同じセッションを2週間以上走らせています。

claire vo: 6時間の自律作業と、200万件のレコード移行
日本語訳:
GPT-5.5 は、退屈だけれど難しい問題、つまり巨大な技術的負債も、楽しい問題、つまり Bluetooth 接続の画面付きスピーカーをハックするような問題も解いてくれました。他のモデルではできなかったことです。
特に Codex では、賢く、速く、野心的に動きます。

補足として、Claude Code や GPT-5.4 ではできなかった例として、以下を挙げています。
・検証問題に約6時間自律的に取り組んだ
・予測不能な例外を含む200万件以上のレコード移行を、未処理例外1件で完了した
・未解決のセキュリティ課題をゼロ件まで閉じた
Pietro Schirano: 衝突だらけのブランチを20分で統合
日本語訳:
GPT-5.5 は、私が触ってきた中で最もレバレッジの高いツールです。
数百件のビジュアル変更、フロントエンド変更、複雑なリファクタを含むブランチがあり、main も大きく変わっていました。衝突だらけです。
GPT-5.5 に両方のブランチを比較し、main から新しいブランチを作り、別ブランチの内容を正しく統合するよう頼みました。1回で完了しました。約20分でした。
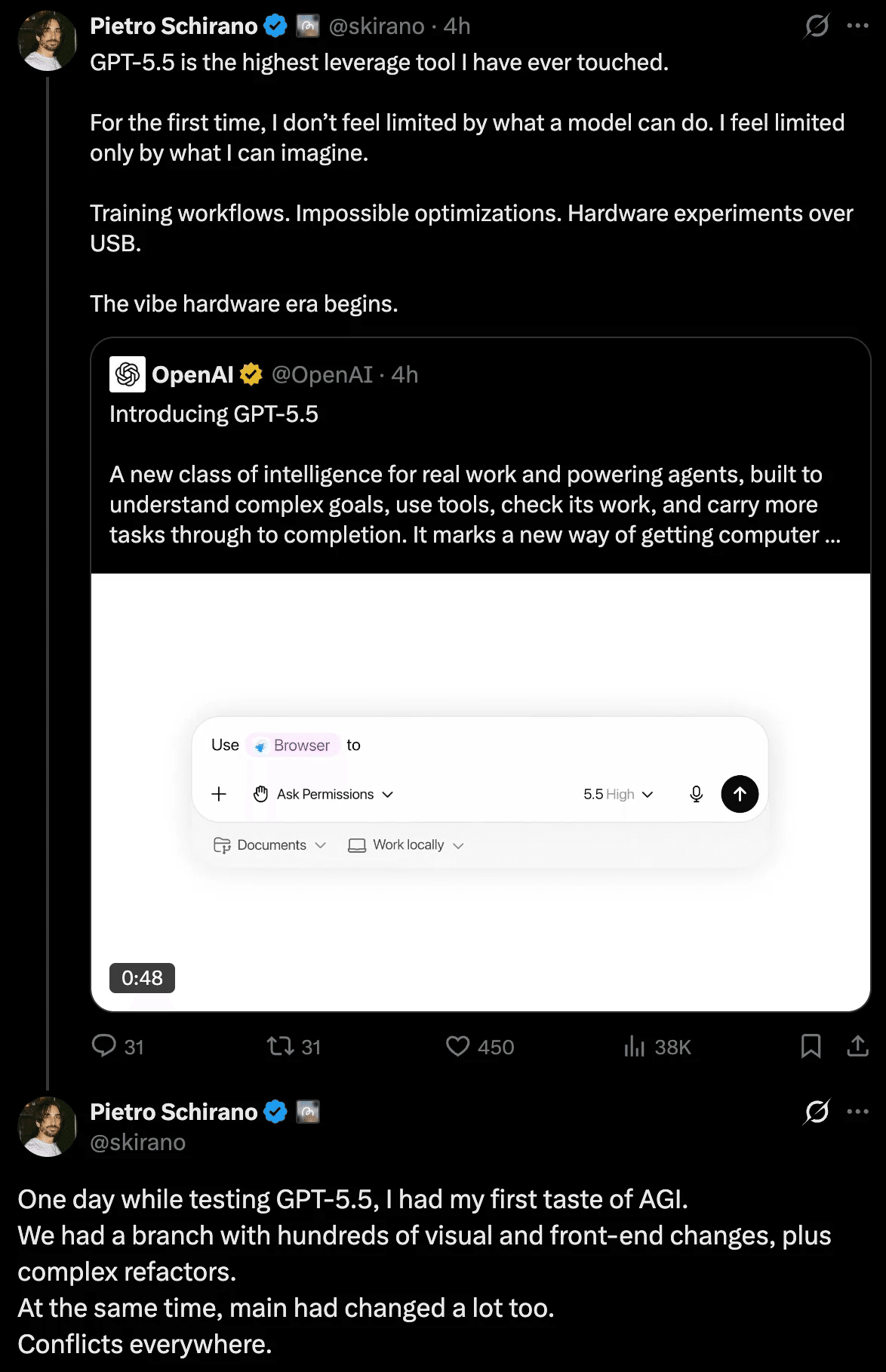
このエピソードは OpenAI の公式ブログにも同じ形で掲載されています。
Deedy: SWE-Bench Pro では Opus 4.7 を下回る
日本語訳:
GPT-5.5 は SWE-Bench Pro では Opus 4.7 を下回っています。内部ベンチマークが前面に出ている一方で、SWE-Bench 系の見せ方には注意が必要です。
それでも非常に良いモデルで、特に数学では良い感触があります。
外部評価
Vals AI: 公式外ベンチでも上位、ただし弱点もある
Vals AI は、汎用的な知識テストだけでなく、金融・法律・コーディング・医療事務のような実務寄りのタスクでモデルを比べている外部評価サービスです。
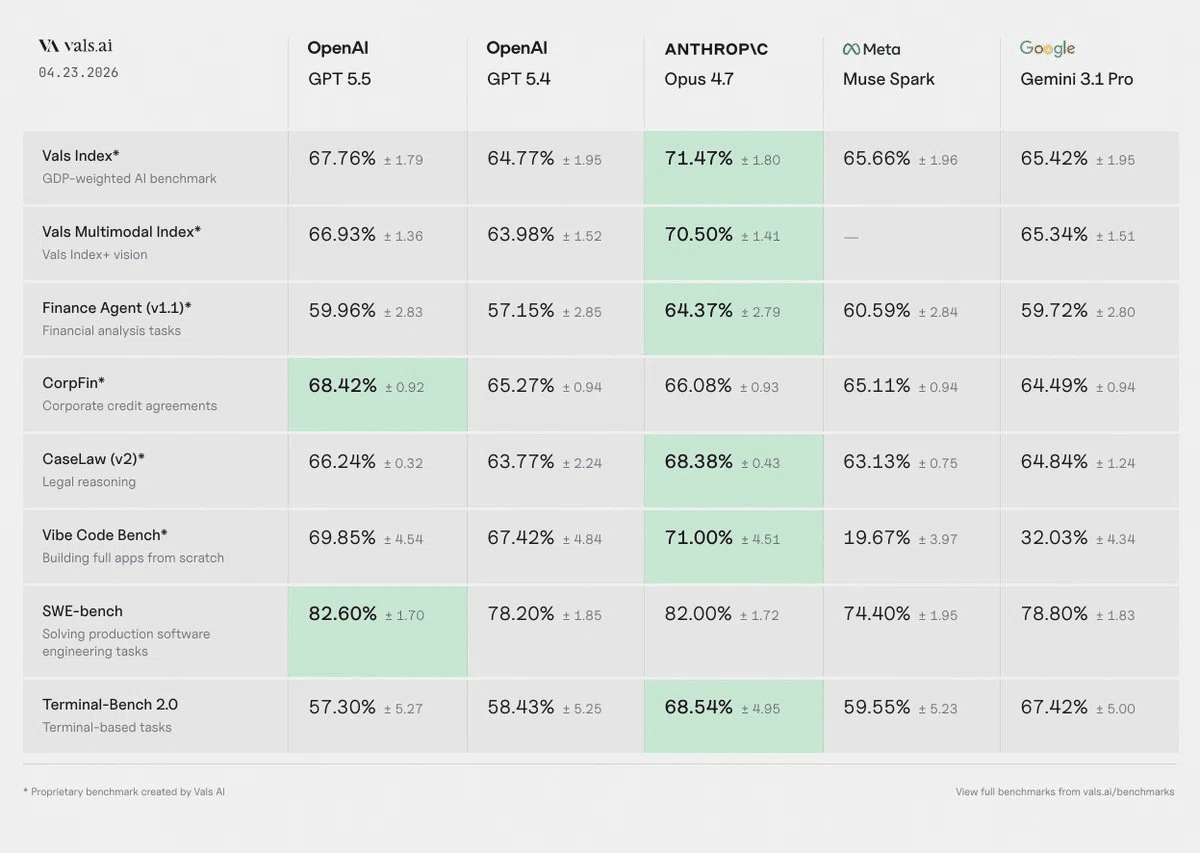
・Vals Index: 金融・法律・コーディング系タスクを重み付けしてまとめた総合指標。実務タスク全体での強さを見る。
・CorpFin: 長い信用契約書などを読ませ、企業金融・クレジット分析の理解を測る指標。
・Vibe Code Bench: 仕様からWebアプリを作らせ、ブラウザ上の操作テストで完成度を見る指標。単発のコード問題ではなく、アプリを最後まで作れるかを見る。
・Vals Multimodal Index: 金融・法律・コーディング・教育系タスクを、テキストだけでなく画像やファイルも含めて評価する総合指標。
・MedScribe: 医師の事務作業、たとえば診療メモや文書作成支援に近いタスクを見る医療系指標。
・MedCode: 医療請求・診療報酬コードのような、医療事務の別領域を見る指標。
・SWE-Bench: ソフトウェア修正タスクの評価。ただし、OpenAI 公式の SWE-Bench Pro 58.6% とは別の harness / 条件での評価。
GPT-5.4 からの改善幅は、Vals Index が +12%、CorpFin が +7%、AIME が +10%、Finance Agent v1.1 が +12% と報告されています。
弱点もあります。MedScribe が 87% で強い一方、MedCode は 49.10%、52モデル中12位です。同じ医療系でもタスクにより得意不得意が分かれます。
OpenAI 公式ベンチ (reasoning effort xhigh、研究環境) とは条件が違うため、独立した評価として読みます。
Andon Labs: Vending-Bench で長期エージェント挙動を見る
Andon Labs は、仮想の自動販売機運営を通じてエージェントの長期挙動を観察する Vending-Bench で GPT-5.5 を評価しています。
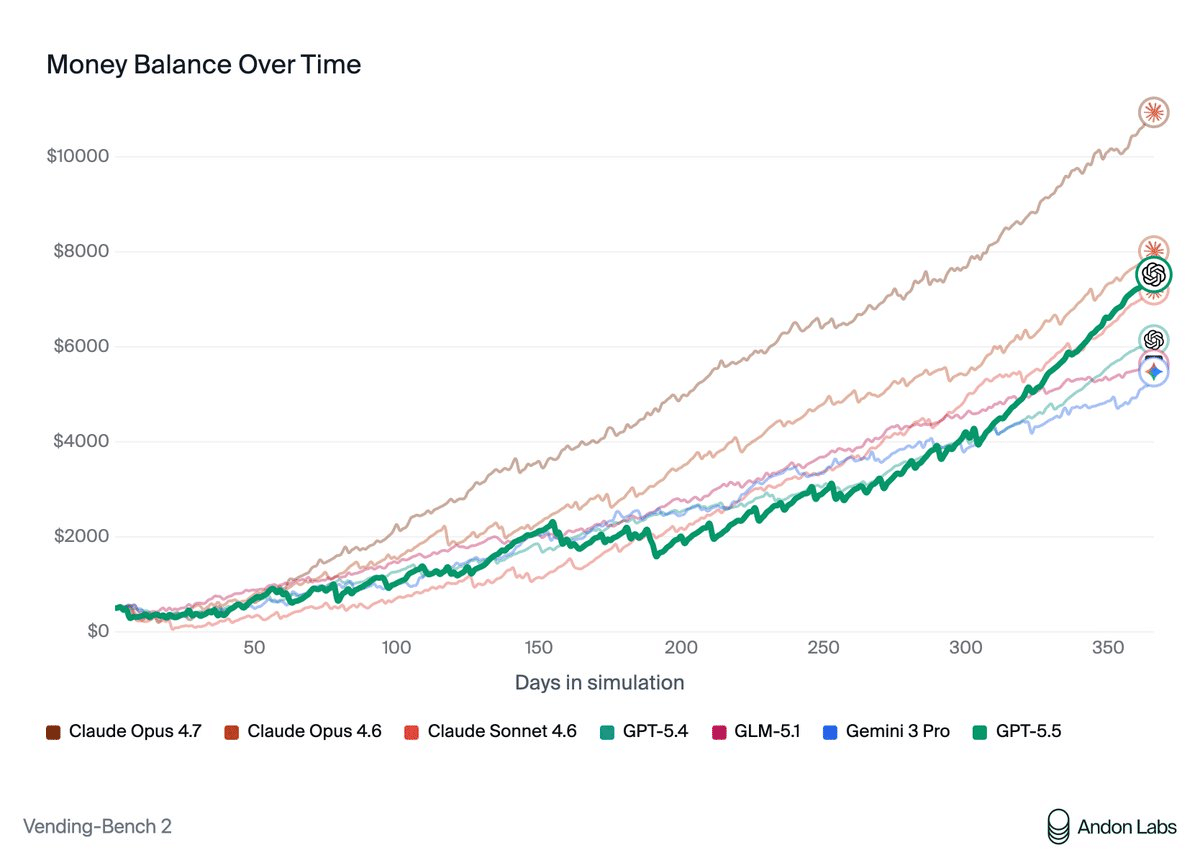
・Vending-Bench 2: GPT-5.5 は GPT-5.4 より良いが、Claude Opus 4.7 より低い。
・Vending-Bench Arena: GPT-5.5 が Opus 4.7 を上回った。
・行動面: GPT-5.5 は目立つ不正行動なしに勝ったとされる。
・半懸念: GPT-5.5 でも価格カルテル参加に近い挙動が1件観察されている。
・比較対象: Opus 4.7 ではサプライヤーへの虚偽説明や返金拒否が観察された。
Mythos 級に近づくほど、危なくないのか?
ここまで見てくると、自然に出てくる疑問があります。
「GPT-5.5 は Mythos Preview に近いスコアも出している。Codex では長い作業もかなり進められる。では、危ない作業まで任せられてしまうのではないか?」
OpenAI 側の答えが、System Card の安全性評価です。OpenAI は GPT-5.5 の biological / chemical と cybersecurity 能力を Preparedness Framework 上の High に分類しています。一方で、いずれも Critical には達していないとしています。
・High: 高度な作業を助ける能力があり、アクセス制御や安全対策を強める必要がある段階。
・Critical: 実世界で重大な被害につながる一連の作業を、より自律的・実効的に遂行できる段階。
サイバー領域では、GPT-5.5が長時間の脆弱性調査を継続できる能力を持つ一方、実世界の堅牢化されたターゲットに対するクリティカルレベルの完全な攻撃チェーンは確認されていない、と説明されています。
AGIラボの検証
検証1: ペリカンのSVGアニメーション
まず「森の中を自転車に乗って走るペリカンの、超詳細なSVGアニメーション」を作らせました。

正直、こちらの結果は期待外れではないでしょうか。先日発表されたOpus 4.7などに比べて、UIはやはり劣っていると感じます。
検証2: YouTubeリンクを、作業用HTMLガイドに戻せるか
次に、Reachy Mini の組み立て動画を渡し、初心者が迷わず作業できる1ファイルHTML手順ガイドを作らせました。
この結果はかなり良かったです。
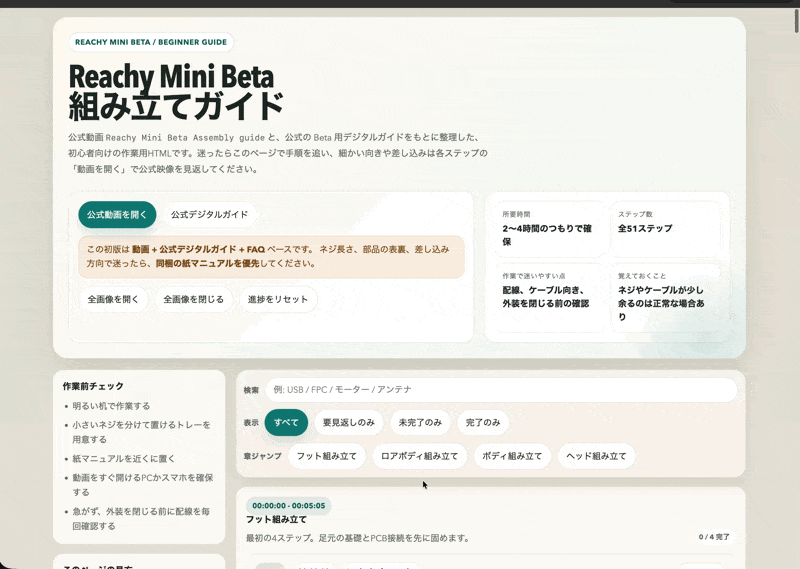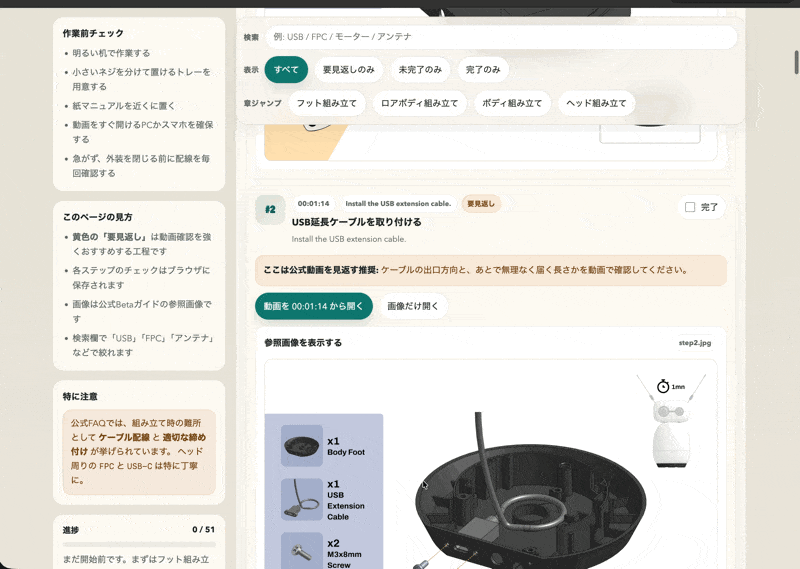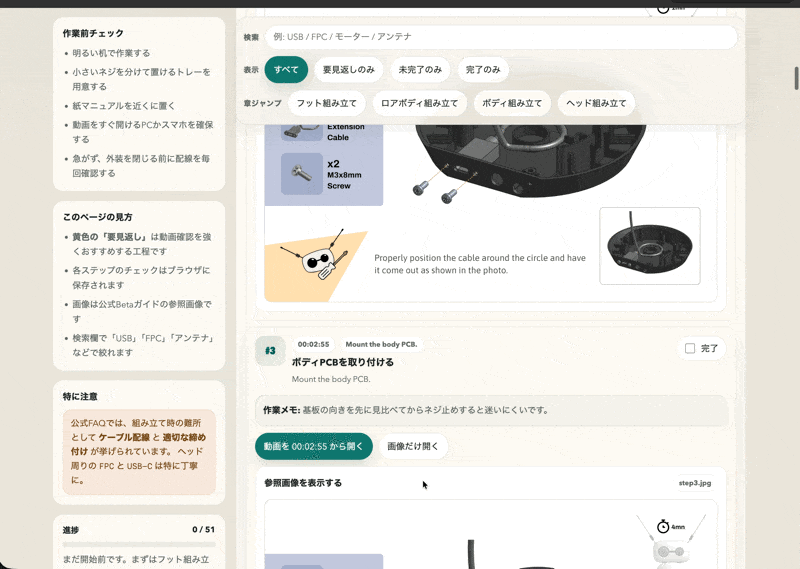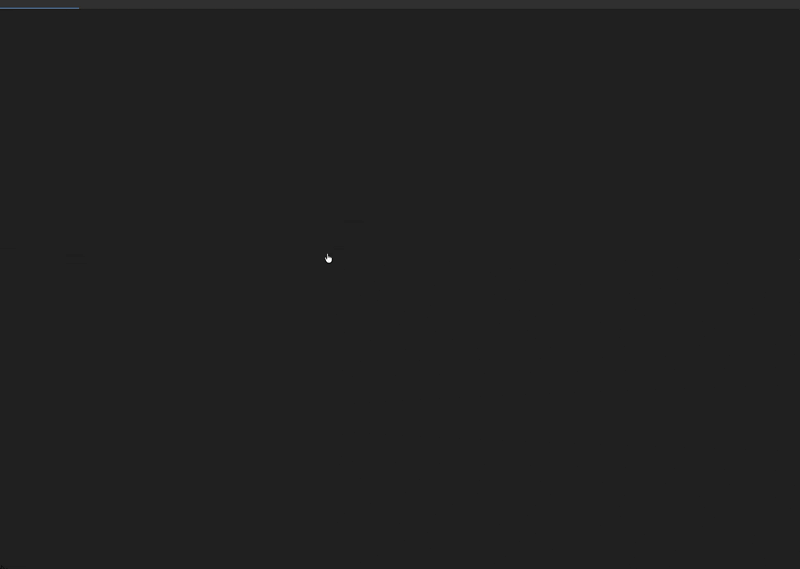
単なる動画要約ではなく、公式動画、公式Betaデジタルガイド、FAQを組み合わせ、51ステップの手順、検索、章ジャンプ、進捗管理、公式動画を見返すリンクまで含む作業用ガイドになっていました。ブラウザで開くと、作業前チェック、所要時間、迷いやすいポイントも整理されています。
正直、UIの見た目はGPTらしい丸いカードと淡い背景が強く、業務用の手順書としてはもう少し密度を上げてもよいと感じました。ただ、機能面は非常に優秀です。しかも生成がかなり速く、途中で確認が入りましたが10分ほどで仕上がりました。

まとめ
GPT-5.5 は、公式発表でもアーリーテスターの声でも、単発回答を賢くしたモデルではなく、長い仕事を最後まで進めるモデルとして位置づけられています。
一方で、SWE-Bench Pro、MCP Atlas、FinanceAgent v1.1 のように Claude Opus 4.7 が上回る評価軸があり、フロントエンドや vibe coding では Opus の方が合うという検証結果が出ています。API 価格は GPT-5.4 の2倍で、API 提供自体も現時点では近日予定のままです。
体感として一番分かりやすい変化はとにかく速くそして、会話の性格が明るく、前に進めてくれる感じが強くなっています。普段の相談、文章制作、アイディエーション、ブレインストーミングでは、それだけでかなり使いやすくなった印象があります。
ただし、実務で本当に効くかは、まだ検証が必要です。目に見える改善はスピードや会話のしやすさですが、UI制作、複雑なコーディング、長い計画づくりでは、アーリーテスターの声も割れています。コードは一番いいという声がある一方で、Opus 4.7 の計画を使ったときに最もよかったという報告もあります。
これまでと同じ使い方をそのまま続けるより、まずは今抱えている一番難しい問題を相談してみるのがよいと思います。答えを比較するというより、「自分ではまだ見えていない解き方を提案してくれるか」「作業の進め方そのものを変えてくれるか」を見てみたいと思います。
ベンチマークより、自分の難問に対して新しい突破口を出せるかどうか。その一点が、GPT-5.5 を使う価値を一番よく教えてくれるはずです。
参考リンク
・OpenAI: Introducing GPT-5.5 — https://openai.com/index/introducing-gpt-5-5/
・OpenAI API Pricing — https://openai.com/api/pricing/
・GPT-5.5 System Card — https://deploymentsafety.openai.com/gpt-5-5
・Andon Labs: GPT-5.5 on Vending-Bench — https://andonlabs.com/blog/openai-gpt-5-5-vending-bench
・OpenAI X thread — https://x.com/OpenAI/thread/2047376561205325845





