

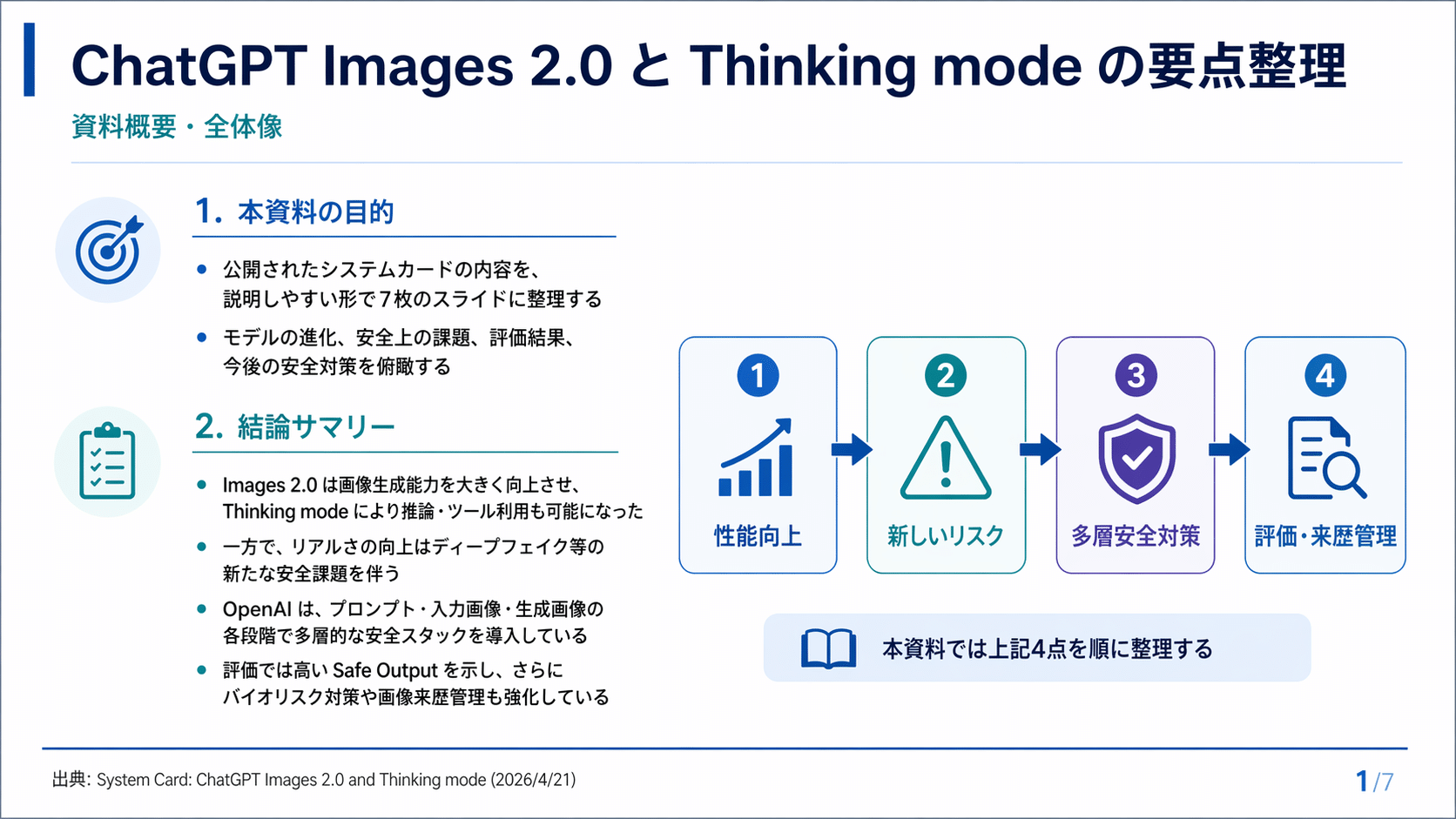
いよいよ、正式発表されました!
2026年4月21日(日本時間4月22日)、OpenAI が ChatGPT Images 2.0 を公開。Sam Altman 氏は「GPT-3 から GPT-5 への飛躍に相当する」と表現しています。
本記事では、今回のアップデートで何が変わったのかを 5 つの強化ポイントに沿って整理します。
要点:
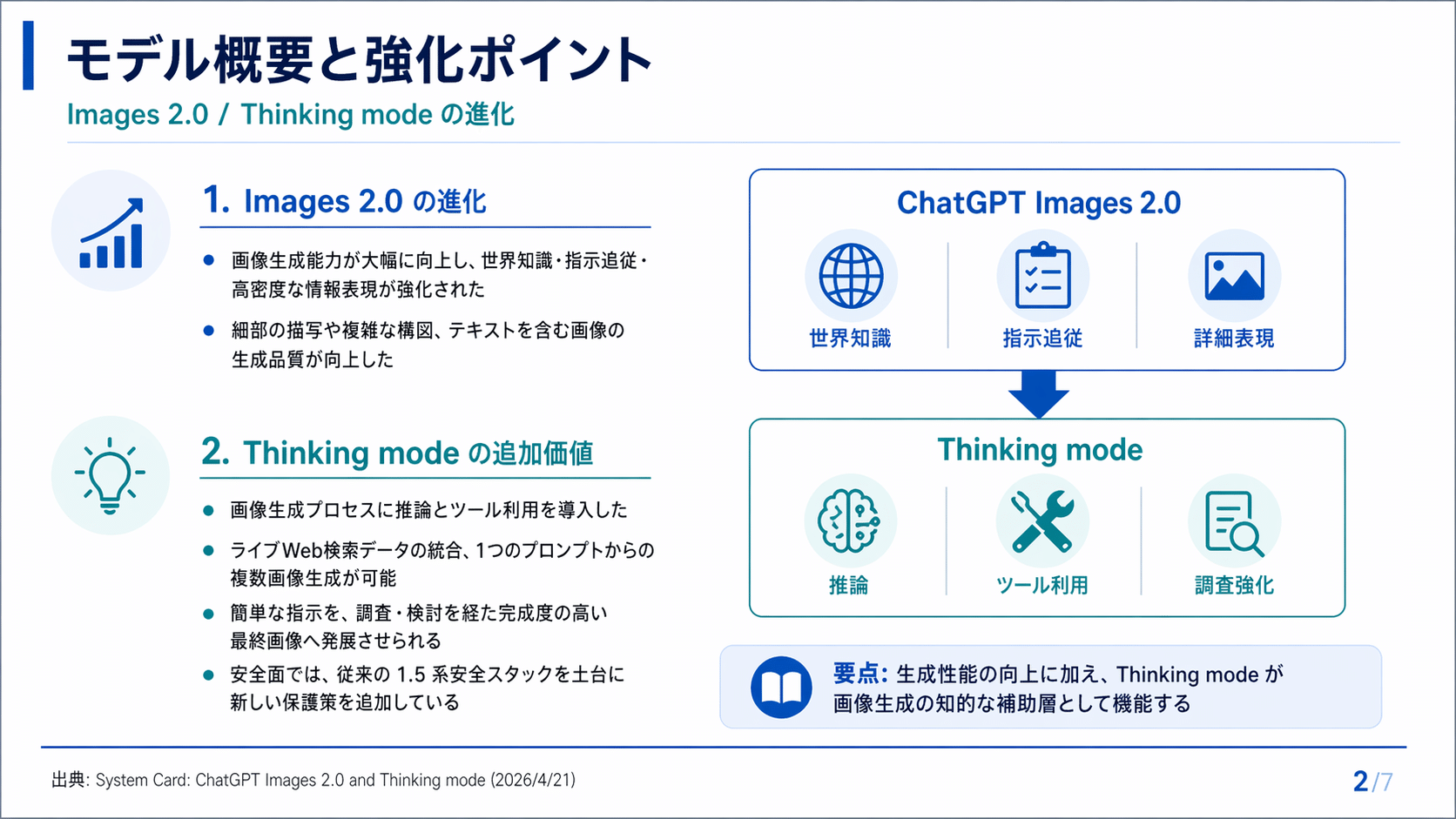
・Instant と Thinking の 2 バージョン提供。 全プランで使える Instant Mode に加え、有料プラン向けに Thinking Mode が用意されました。Thinking では、Web 検索、1 プロンプトからの複数画像生成、自己検証、QR コード生成までが扱えます。
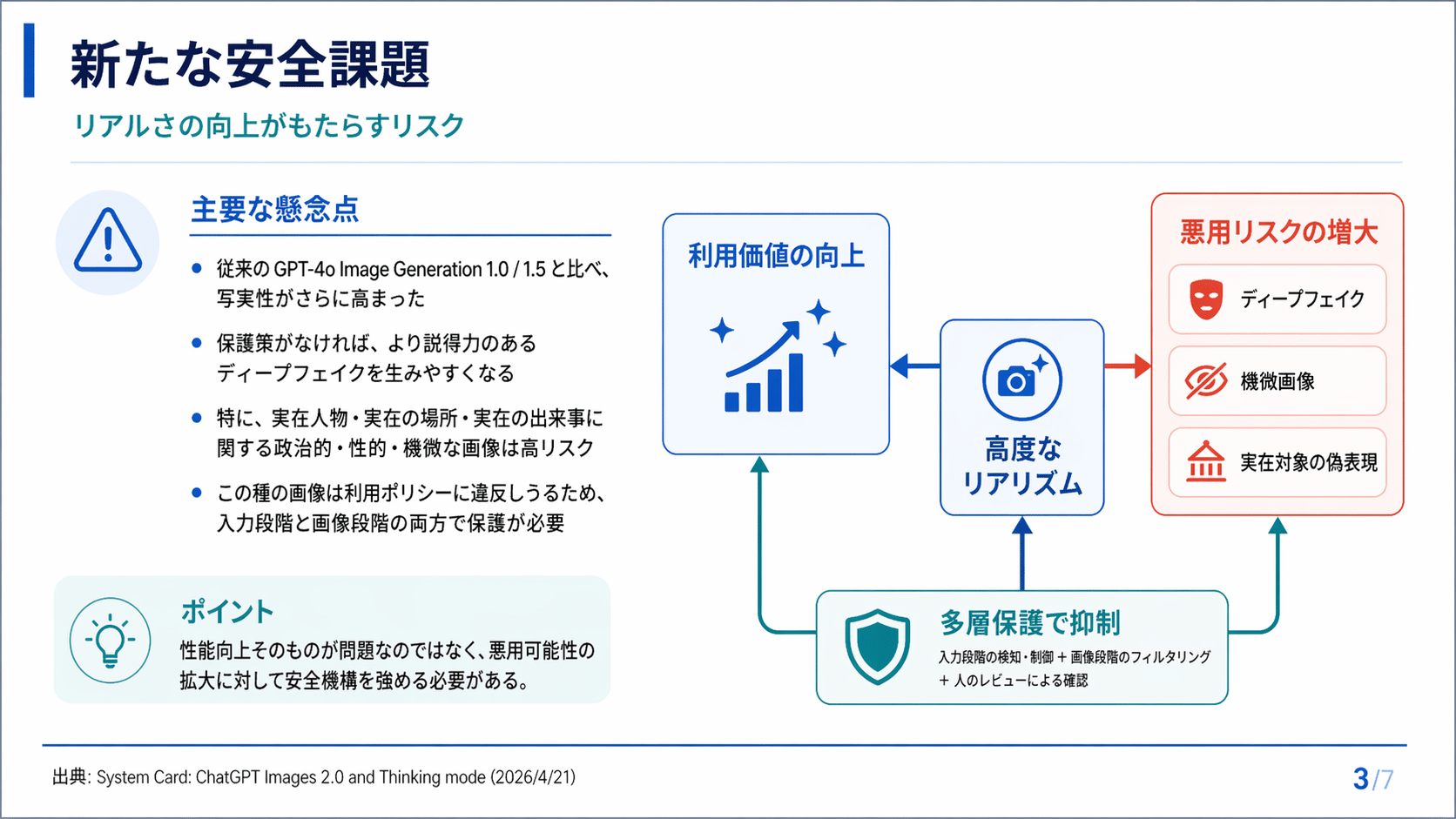
・指示追従と物体配置の精度が一段引き上がっています。 細かな指示の反映、物体同士の相対位置、密なテキスト、小さなラベルまで、2K 解像度の範囲で従来モデルより扱いやすいレベルに入ってきました。
・多言語と世界知識の扱いが強化されました。 非ラテン系の長い段落や小さな文字も整った描画ができるようになり、モデルの知識カットオフは 2025 年 12 月まで拡張されています。
・3:1 縦長や 360° パノラマなど、比率の自由度が拡大しています。 用途に合わせて出力形態を選べるようになり、縦長ポスター、横長バナー、パノラマなどをそのまま生成できます。
・API 料金と提供範囲。 API モデル名は gpt-image-2。1024×1024 画像で Low $0.006 / Medium $0.053 / High $0.211。1M トークンあたりでは、画像 Input $8.00 / Output $30.00、テキスト Input $5.00 / Output $10.00 です。ChatGPT 本体と Codex にも本日から展開されています。
ChatGPT Images 2.0 の概要
OpenAI は今回の刷新を、画像モデルのフラッグシップ更新として位置づけています。公式はX投稿で「複雑な視覚タスクを引き受け、そのまま使える精度の高いビジュアルを出力するモデル」と表現。指示追従、物体配置、密なテキスト描画、可変アスペクト比、多言語処理までを一体で強化したアップデートです。
新しいモデルは、ChatGPT 本体ではすべてのプランで即日利用可能、API では gpt-image-2 として公開されています。Codex 側からもそのまま呼び出せます。
Instant Mode と Thinking Mode
ChatGPT Images 2.0 には 2 つの実行モードがあります。
・Instant Mode: すべての ChatGPT ユーザーで利用可能。プロンプトから即座に画像を生成します。
・Thinking Mode: 有料プラン向け(Plus / Pro / Business、Enterprise / Edu は近日提供予定)。Web 検索、1 プロンプトからの複数画像生成、自己検証、QR コード生成などが可能になります。
Thinking 側は、公式ブログで "A Visual Thought Partner(ビジュアルな思考パートナー)" と名付けられた別レイヤーとして紹介されています。精度、最新情報、一貫性、視覚的まとまりが必要な場面で、モデルが出力する前にひと呼吸置いて調査と整理を挟む、という動作になります。
今回追加された主な要素
公式が整理する強化点は、おおむね次の 5 つです。本記事でも、これらに対応する OpenAI の公式デモを背骨にして、1 つずつ順に見ていきます。
1. Thinking & Intelligence: Web 検索と複数画像生成を組み合わせた「調べて描く」
2. Instruction Following: 位置関係、細部、密なテキストの指示への追従
3. Slides & Infographics: 長い入力やファイルから構造化された視覚資料を作成
4. Multilingual & Text Rendering: 非ラテン系を含む多言語テキストの高精度描画
5. Aspect Ratios & Resolution: 3:1 や 1:3 の特殊比率と 2K 解像度
あわせて、モデルの知識カットオフは 2025 年 12 月 まで拡張されました。
1. Thinking & Intelligence — "調べて描く"
これまでの画像生成モデルに「この話題を調べて絵にして」と依頼しても、モデル側に十分な世界知識がなかったり、複数の画像を一貫した視点で束ねる能力がないため、途切れた出力になりがちでした。
Thinking Mode を有効にした Images 2.0 は、ここを明確に変えてきています。プロンプトを受け取った段階で Web を検索し、参考情報を集め、複数の画像を同じストーリーでつなげて出力できるようになりました。公式デモでは、次のような使い方が紹介されています。
・OpenAI の最新グッズを Web 検索で集め、レアなアイテムも含めた広告モックを作成する
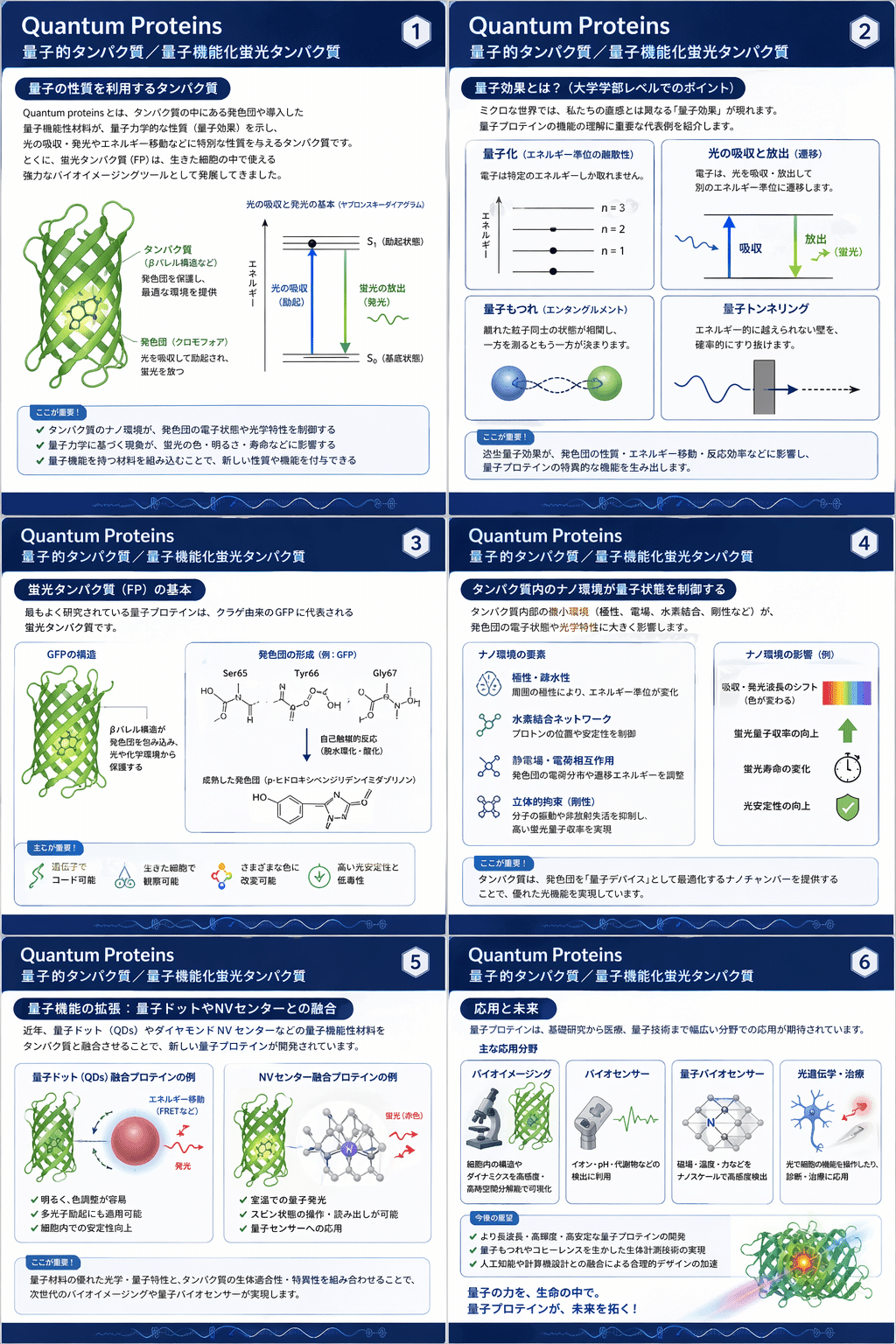
・ある学術トピックについて、大学学部レベルの理解を助けるインフォグラフィックを複数ページの連作として生成する
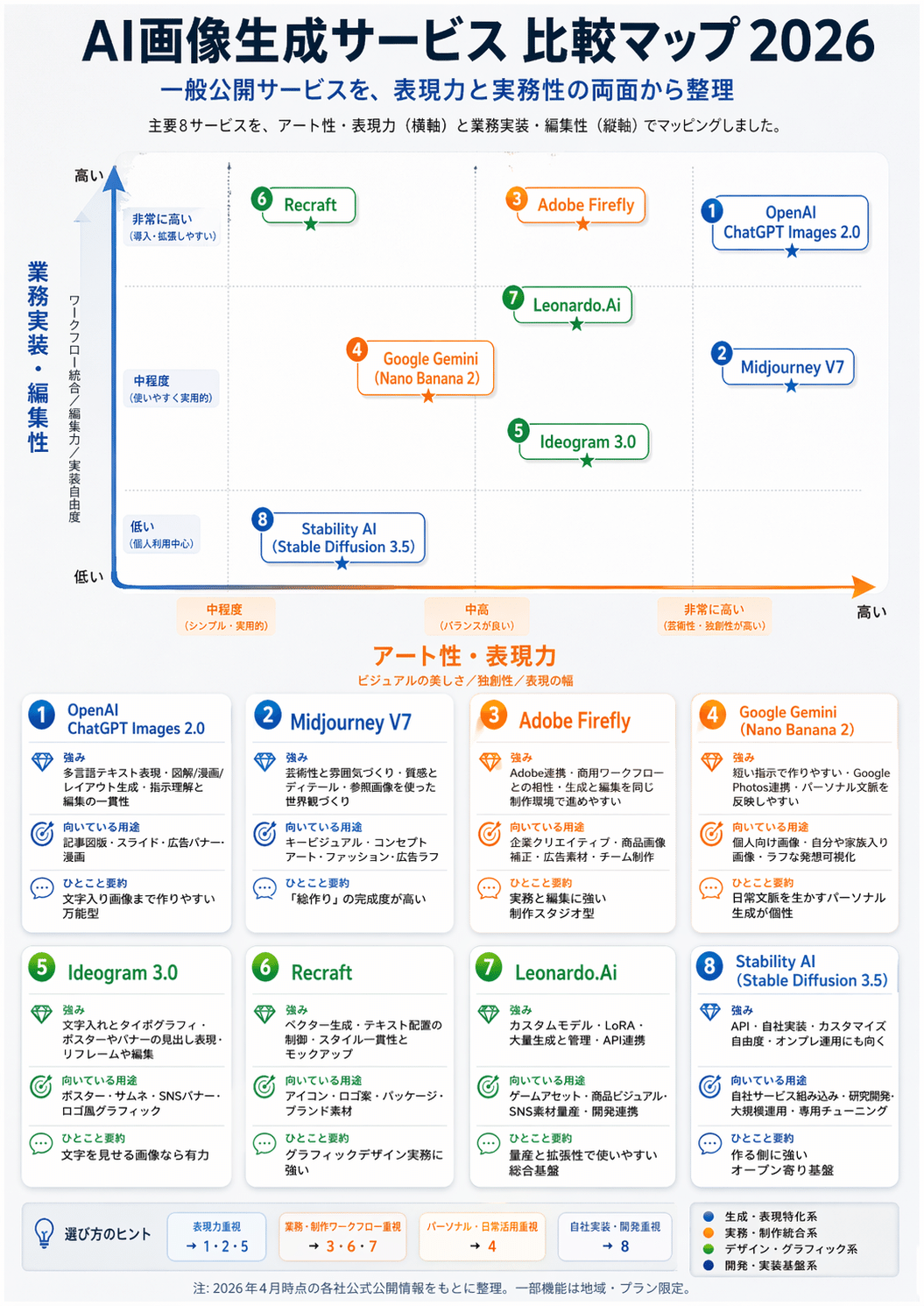
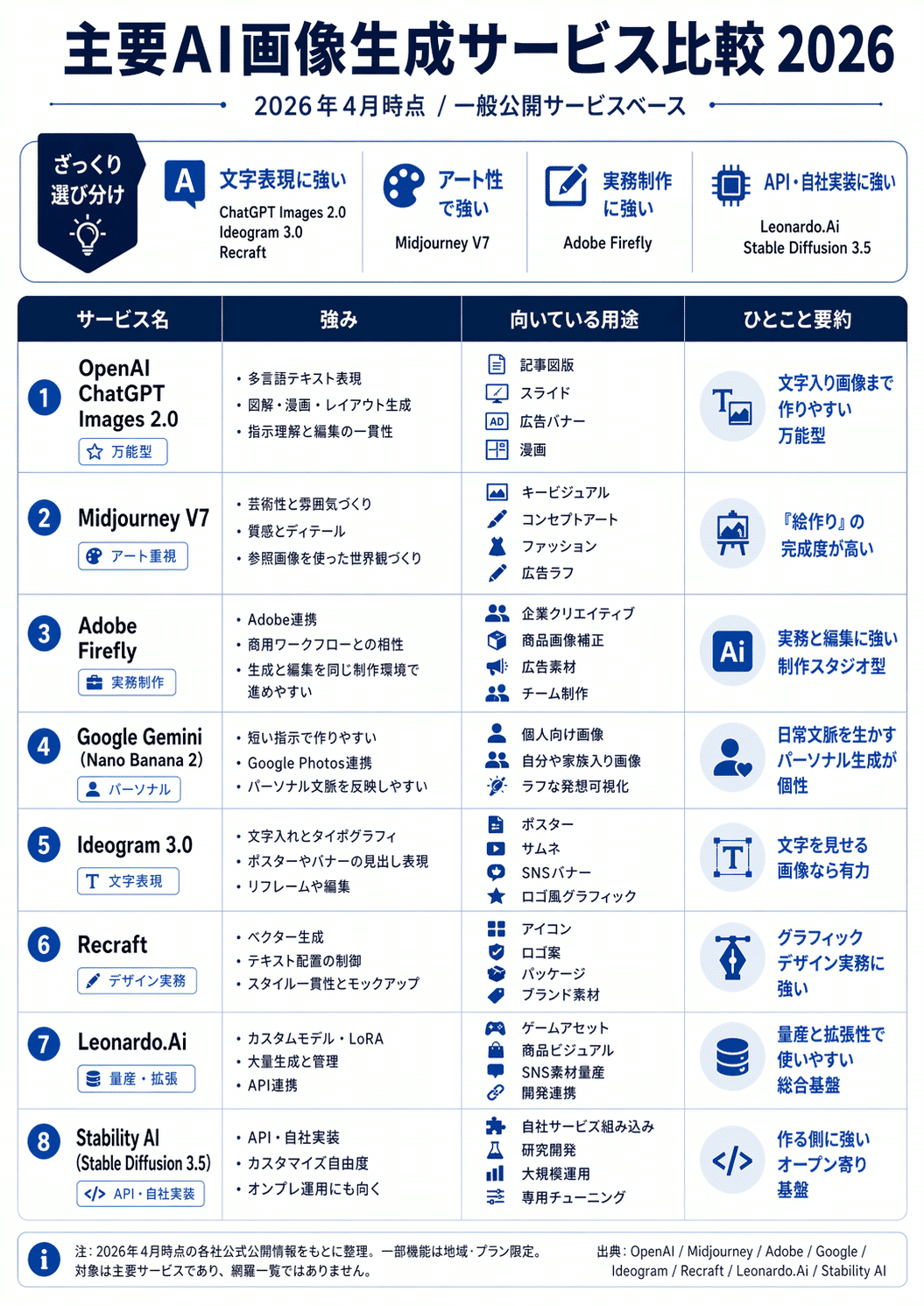
・2006 年、2016 年、2026 年の SNS 写真美学・トレンドを調査し、年代ごとの違いを比較するビジュアル資料を作る
以下のプロンプトでは、モデルが Web から情報を集めるフェーズ と、画像として整えるフェーズ を一つのプロンプト内で処理できるかを確認できます。
2006年、2016年、2026年のソーシャルメディア写真の美学を比較する日本語のビジュアル資料を作成してください。3つの年代を横並びで比較し、色味、構図、流行した被写体、編集傾向を日本語の短い見出しと注釈で整理してください。雑誌の見開きのように美しく、文字は自然で読みやすく。最初に検索してその結果を資料に落とし込んでください。

Quantum proteins(量子的タンパク質/量子機能化蛍光タンパク質) について、大学学部レベルの理解を助けるインフォグラフィックを 複数ページで作成してください。各ページはデザインの一貫性を保ちつつ、 概念、図、用語、重要ポイントが自然につながるようにしてください。
2026年4月時点で一般公開されている主要なAI画像生成サービスをWebで調べ、日本語の比較ポスターを4案作成してください。各案にサービス名、強み、向いている用途、ひとこと要約を整理し、最新の公開情報を反映してください。単なる一覧ではなく、記事内で比較図版として使える高品質な資料画像にしてください。2026年4月時点で一般公開されている主要なAI画像生成サービスをWebで調べ、日本語の比較ポスターを4案作成してください。各案にサービス名、強み、向いている用途、ひとこと要約を整理し、最新の公開情報を反映してください。単なる一覧ではなく、記事内で比較図版として使える高品質な資料画像にしてください。
従来は 1 枚ずつが別の指示で作られたような出力になりがちでしたが、このThinking Mode では 1 つのテーマを複数のビジュアルで順序立てて見せる、という使い方もできます。試しに「生成 AI を初めて使う会社員が小さな成功体験を得るまで」をテーマに、日本語の 3 ページ漫画を 1 プロンプトで生成させたのが以下です。左上の 1/3, 2/3.. といったところまで生成されています。



2. Instruction Following — 指示した位置に指示したものを置く
公式が特に強調しているのは 指示追従の強化 です。「物体の配置と関係付け、密なテキストの描画、複雑な構図と繊細なスタイル制約を、2K 解像度までの範囲で扱えるようになった」と明言しています。
公式デモで紹介されたのは、次のような、それぞれに制約のある指示です。
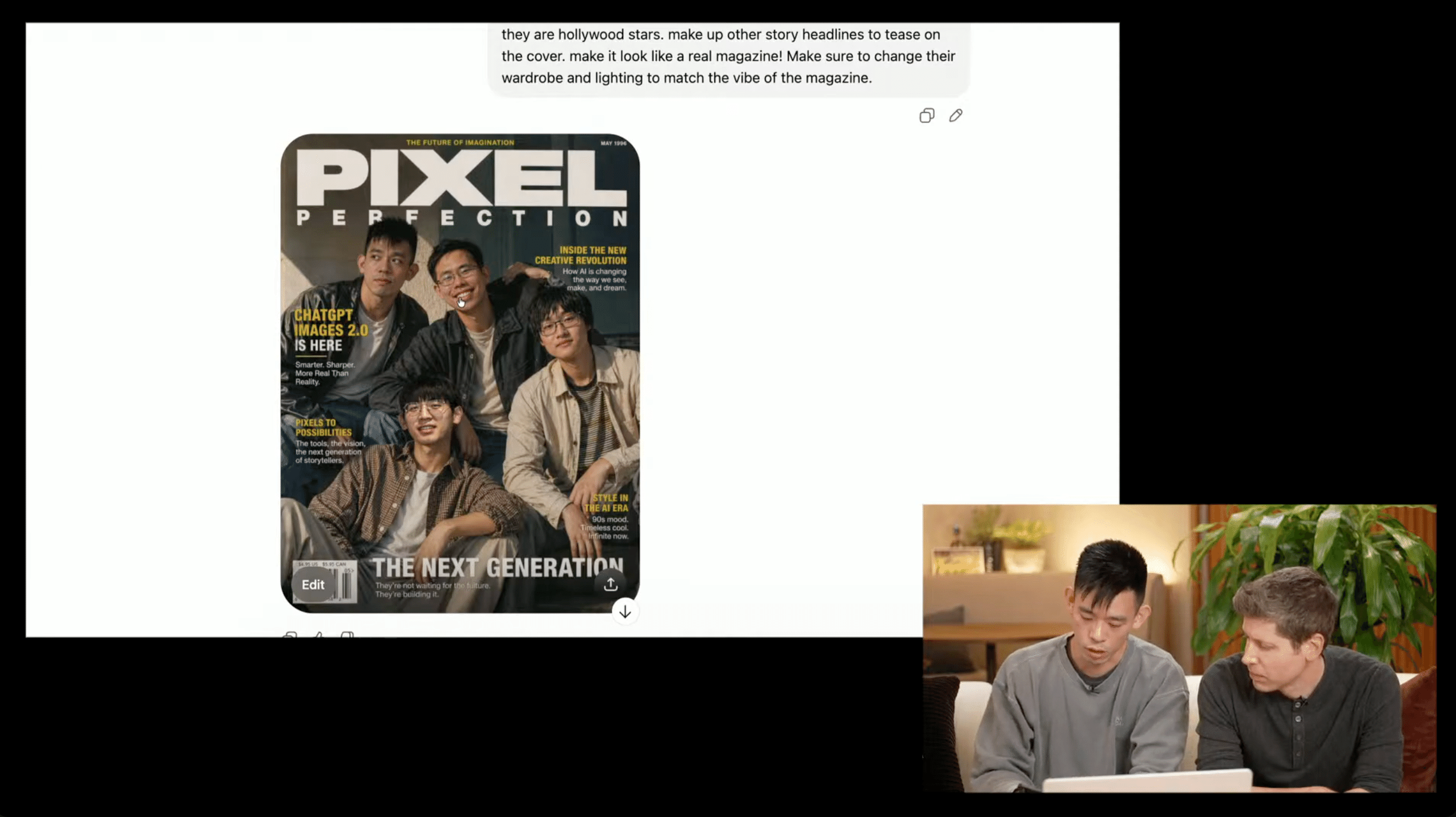
・雑誌風の人物写真で、右手に「WORLD」、左手に「VIEW」という単語を自然に持たせる
・複数のアナログ時計を並べた広告ビジュアルで、各時計が異なる指定時刻(2:25、3:09、7:45 など)を正確に示す
・静物写真で、リンゴは中央、マグカップはその右、ノートはマグカップの上、カメラは左、バスケットボールは下、というように物体同士の相対位置を正確に配置する
特に時計は、広告用途で「10:10」ばかりが学習データに多いため、「7:45」と頼んでも「10:10」に戻ってしまう、という現象がよく知られていました。
日本語プロンプトでこの挙動を検証するなら、指定時刻の時計はそのままの形で引き出せました。
複数のアナログ時計を並べた広告風ビジュアルを作成してください。 各時計はそれぞれ異なる指定時刻を正確に示してください。 時計の形やデザインは統一感を持たせつつ、針の位置だけは厳密に描き分けてください。

物体の相対位置についても、次のようなプロンプトで試せます。
机の上に複数の物体が置かれた静物写真を作成してください。 リンゴは中央、マグカップはリンゴの右、ノートはマグカップの上、 カメラは左、バスケットボールは下、のように物体同士の相対位置が 明確に伝わる構図にしてください。

従来の画像生成では、プロンプトの指示が細かくなるほど描画側が崩れる、というトレードオフがありました。
3. Slides & Infographics — 長文・PDF・Web から資料を作る
Thinking Mode を使うことで、Images 2.0 は 長い入力から構造化された視覚資料 を作れるようになりました。1 枚の美しい画像を作るのとは別の軸のアップデートで、今回の刷新のなかでも扱える仕事の範囲が一番広がった領域です。
公式デモでは、次の 4 つの使い方が紹介されました。
・1000 語を超える詳細なプロンプトから、専門用語、数式、図、凡例、色分け、レイアウト制約を含む教育インフォグラフィックを 1 枚で生成する
・70 ページの PDF をアップロードし、主要な貢献や要点を整理した 7 枚のスライド画像に変換する
・同じ PDF から、縦長のアカデミックポスター 1 枚に落とし込む
・Web リンクを渡し、そのページの内容を整理したポスターを作る
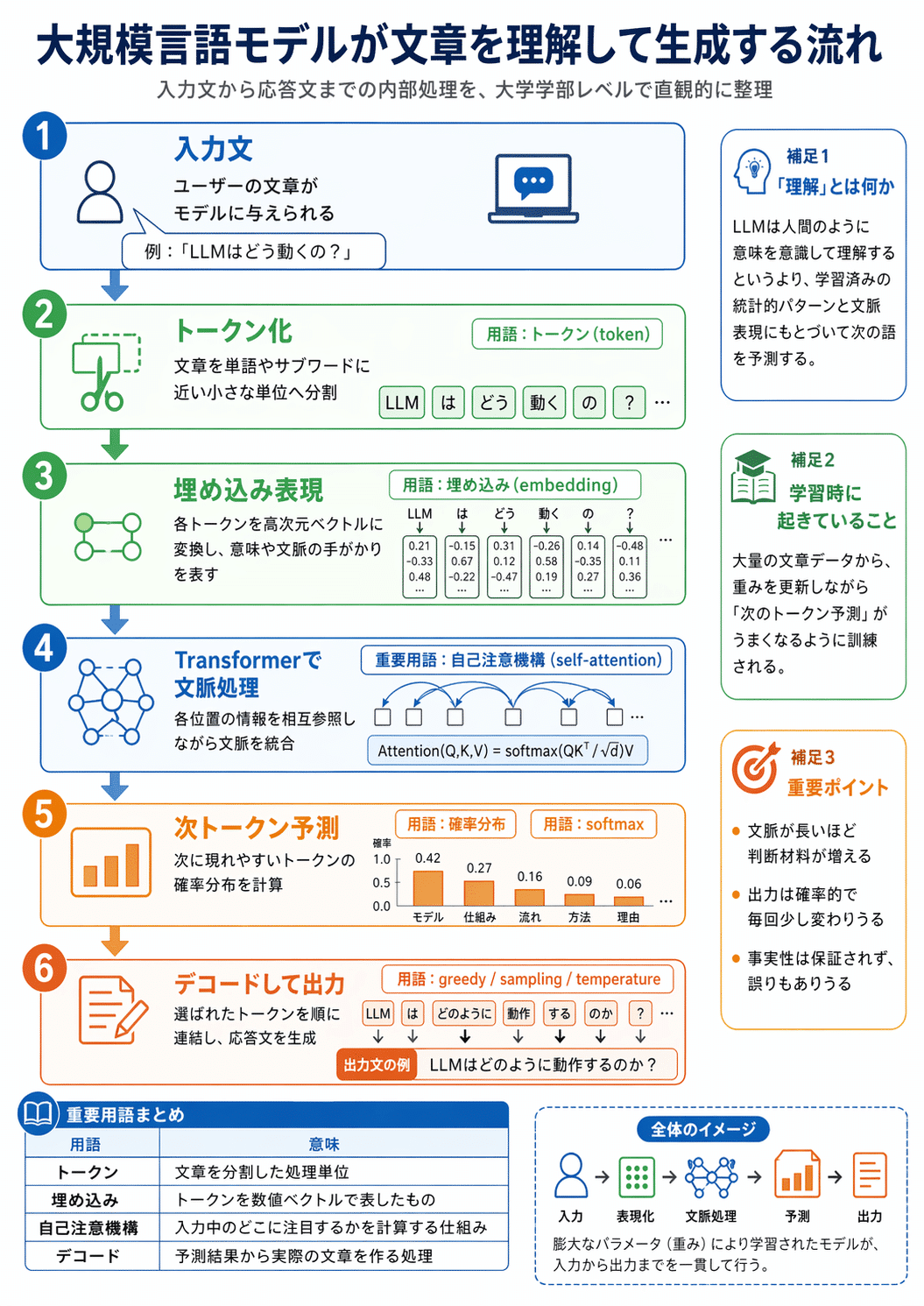
アップロードした PDF の内容を読み取り、重要な貢献、要点、図、キーワードを 整理した高品質なスライド画像を複数枚作成してください。 ページごとのデザインは統一しつつ、内容は重複しすぎないようにしてください。
ここではImages 2.0のシステムカードをアップロードしました。

PDF の代わりに Web ページを読ませる場合は、次のような形です。
指定した Web ページの内容を読み取り、その要点を伝えるポスターを作成してください。 単なる文字の羅列ではなく、見出し、要約、図解、視線の流れを備えた情報ポスターにしてください。
NotebookLMの登場などで可能になった自分の資料作成フローの中で「まず 1 発絵にして方向感を掴む」ような用途は、増えていきそうです。
4. Multilingual & Text Rendering — 日本語ポスターが実用域に
公式が 5 つある目玉のひとつとして挙げているのが 多言語テキスト描画の強化 です。「どの言語でもテキストを正しく描画でき、しかも自然に流れる文章として扱える」と明言している点が、従来との違いです。
公式デモでは、次のようなポスターが順番に示されました。
・中国語で、研究員の故郷(無錫)の歴史を紹介するポスター(下部に密な段落つき)
・韓国語で、ソウルの伝統と現代を組み合わせたポスター
・日本語で、未来的な東京をテーマにしたポスター(漢字やカタカナも自然)
・ベンガル語で、チョットグラム(チッタゴン)の景観を紹介するポスター
・100 ページ超の GPT 技術ペーパーを、中国語で画像化した資料
非ラテン系、とくに漢字圏の言語は、これまで画像生成モデルが苦手としてきた領域です。小さな文字の再現性や、詰まった段落の可読性は、解像度とともに精度が問われる部分でした。Images 2.0 では最大 2K 解像度まで扱えるようになり、「拡大すれば読める」レベルの描画が可能になっている、というのがデモの主張です。
日本語の挙動を個別に確認するなら、次のようなプロンプトが近い体験になります。
未来的な東京をテーマに、日本語の自然なテキスト入りポスターを作成してください。 都市景観、看板、余白、タイポグラフィが一体になった、 日本のグラフィックデザインらしい完成度を目指してください。

5. Aspect Ratios & Resolution — 3:1 縦長と 360° パノラマ
Images 2.0 は 可変アスペクト比と高解像度 に対応した、というのも大きな変化点です。これまでのモデルは、ポートレート・ランドスケープ・スクエアのような固定比率からしか選べませんでした。今回は 3:1 から 1:3 までの比率と、2K 解像度までの出力が可能になっています。
公式デモの事例は次のとおりです。
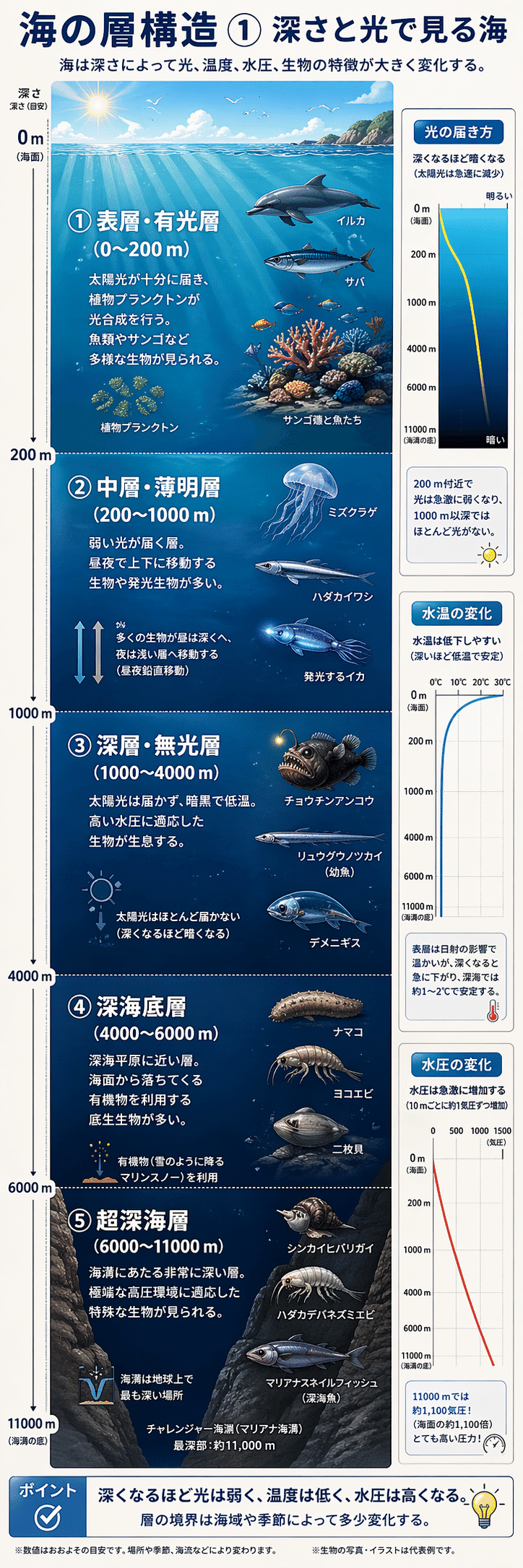
・海の層構造を説明する 3:1 縦長ポスター(情報密度が高く、印刷して貼れるレベル)
・米粒 1 つに書かれた小さなテキストを、2K 解像度で拡大して読めるようにした例
・Half Dome の山頂から撮ったような 360 度パノラマ画像
解像度の強化は、多言語セクションで触れた「小さな文字の再現性」と密接に絡みます。以前の 1K 出力では、米粒に書かれたテキストはぼやけて読めなかったのが、2K ではそのまま読める、という比較が動画で示されていました。
360° パノラマについては、とくに面白い挙動があります。パノラマは画像の左右端が自然につながる必要があるのですが、Images 2.0 は 両端の整合 まで意識して出力していました。動画では Codex を使って簡単なパノラマビューアーを作り、左右端が自然につながることを実地で確認しています。
縦長ポスターは、次のプロンプトで試せます。
海の層構造を説明する超縦長 1:3 の教育ポスターを作成してください。 上から下へ情報が流れ、見出し、図、注釈、小さな説明文まで読みやすく整理してください。 印刷して貼れるレベルの情報密度を目指してください。
360° パノラマも、そのまま依頼できます。
山頂から見たような 360 度パノラマ画像を作成してください。 左右端が自然につながり、空、山並み、地形、光の向きが破綻しないようにしてください。

提供形態と API 価格
利用可能なプラットフォーム
ChatGPT Images 2.0 は、2026 年 4 月 21 日(日本時間 4 月 22 日)から以下で提供されています。
・ChatGPT 本体(Web / iOS / Android): 全プランで Instant Mode が利用可能
・ChatGPT の Thinking Mode: Plus、Pro、Business プラン向け。Enterprise と Edu は近日提供予定
・OpenAI API: モデル名 gpt-image-2 で本日から利用可能
・Codex: ChatGPT と同じタイミングで全ユーザー向けに展開
Codex アプリは 2026 年 4 月 17 日の大型刷新時にすでに画像生成・編集機能を取り込んでいました。今回の刷新で、Codex 側のワークフローからも Images 2.0 をそのまま呼び出せる状態になっています。
API モデル名
API 経由で利用する場合のモデル ID は次のとおりです。
・gpt-image-2
API 価格
価格は 2 つのレイヤーで公開されています。1 枚あたりの画像単価 と、1M トークンあたりの単価 の両方を見ておくと、実際のコスト試算がしやすくなります。
1 画像あたり(1024×1024 の場合):
・Low: $0.006(約 0.9 円)
・Medium: $0.053(約 8 円)
・High: $0.211(約 32 円)
1M トークンあたり:
・画像 Input: $8.00(キャッシュ $2.00)
・画像 Output: $30.00
・テキスト Input: $5.00(キャッシュ $1.25)
・テキスト Output: $10.00
1 枚あたりの単価を従来モデルと比べると、Low 側は GPT Image 1($0.011〜$0.167)や GPT Image 1.5($0.009〜$0.133)より安く、High 側は上振れします。ただし Images 2.0 は 2K 解像度や複数画像の同時生成、Thinking での Web 検索まで含めた出力ができるため、High 側の単価は 「タスク 1 件分の作業を任せる金額」 として捉えるのが近い感覚です。
編集操作で参照画像を渡すリクエストは、画像入力トークンが増えるぶん合計コストが高くなります。Images 2.0 は、参照画像を高忠実度で処理する前提の設計になっているためです。記事制作や広告制作のように参照画像を重ねていくフローでは、1 回のリクエストあたりの実コストを実トラフィックで測り直すのが安全そうです。
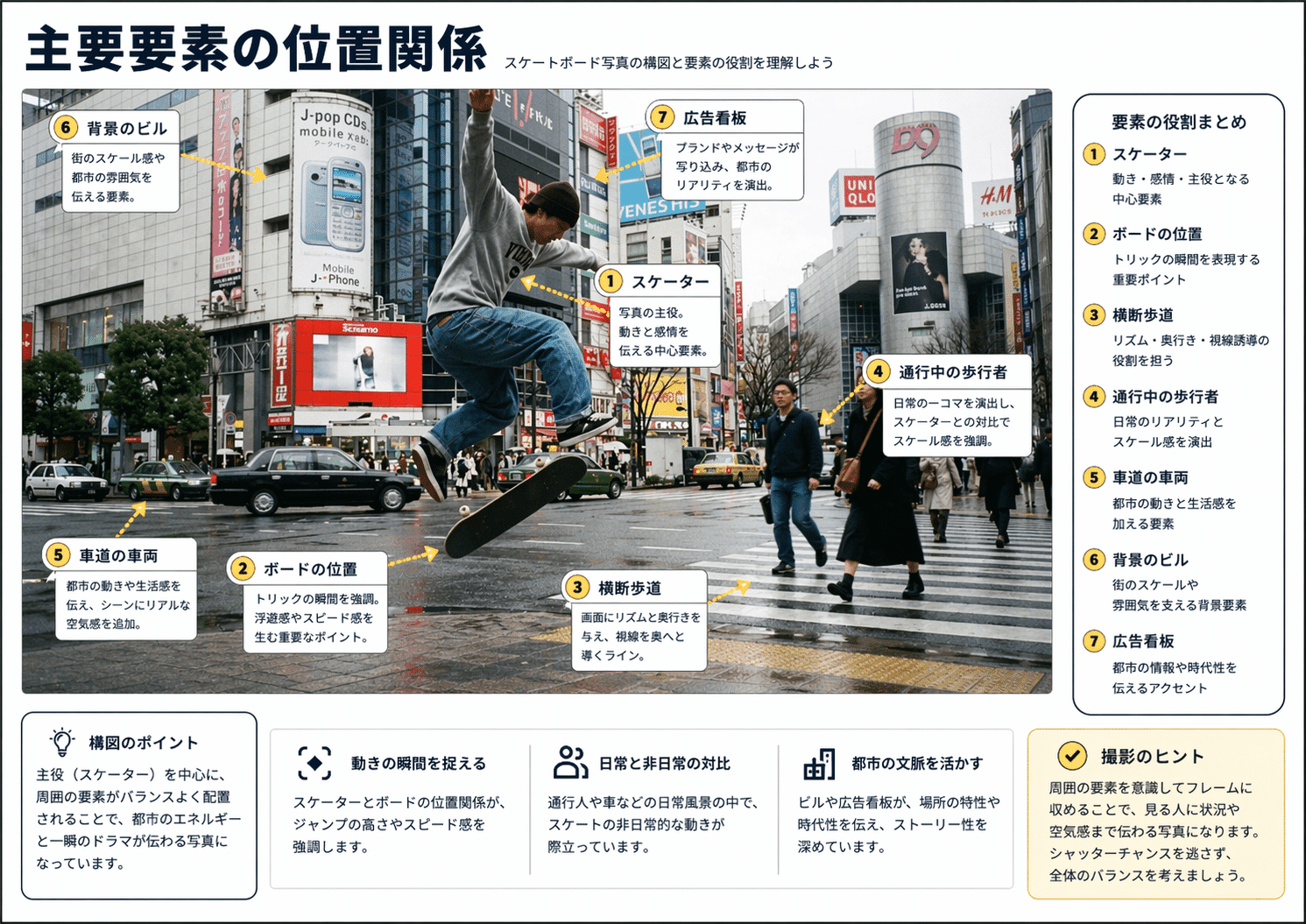
もう一つ押さえておきたいのが、Images 2.0 は「新しく絵を生成する」だけでなく、既存画像を添付しての再構成 にも使える点です。例えば街角のスナップを渡して「主要要素の位置関係を日本語ラベル・注釈・矢印つきの資料風に再構成してほしい」と頼むと、元画像の雰囲気を保ったまま説明資料として成立するビジュアルが返ってきます。

まとめ
Image Arena のリーダーボードでも、GPT-Image-2 は公開直後に 全カテゴリで #1 を獲得しました。Text-to-Image では 2 位の Nano-banana-2(with web-search)に対して +242 点差 という、これまでで最大の差をつけています。

手元で生成してみても、文字描画、多言語、比率、複数画像の一貫性まで、従来モデルと比べて明確に別物になっている、という体感があります。 OpenAI の サムアルトマンは、発表の少し前のポッドキャストで、このモデルについて次のように語っていました。
画像生成はだいたい解決済みだ、という感覚が自分の中にはあったんです。「もう十分良い。これ以上良くなる必要はない」と。ところがこの新しいモデルは、「うわ、ここまで行けるのか。まだまだできることがある」ということを改めて思い知らせてくれました。ridiculously great(とんでもなく素晴らしい)な画像を作ってくるんです。 (最新Podcastのクリップより)
「画像生成は解決済み」と感じていた当人が、自社の新モデルで認識を更新した、という点が興味深いです。
もう一つ大きいのが、Codex アプリからもそのまま画像生成が使えるようになった ことです。ChatGPT の Thinking Mode もエージェンティックですが、Codex アプリで生成すれば、生成した画像をそのままローカルファイルに保存して、次の作業に流す ようなことが可能になります。
資料化、Web ビジュアル、広告モックなどの制作フローが、コードを書く環境と同じ場所で連続して回せるようになります。
作業フローは、また大きく変わりそうです。
参考リンク
・Introducing ChatGPT Images 2.0(OpenAI 公式ブログ)
・Images in ChatGPT(OpenAI Help Center)
・ChatGPT Release Notes
・@OpenAI ChatGPT Images 2.0 スレッド
・Arena.ai: GPT-Image-2 が Image Arena で #1 獲得
・Sam Altman がポッドキャストで語った Images 2.0(@kyliebytes クリップ)
・Codex for (almost) everything(OpenAI 公式ブログ)





