

デスクトップ型ロボット「Reachy Mini」にOpenAIのリアルタイム音声AI(gpt-realtime-1.5)を載せて、声だけでイベント受付ができるかを検証しました。
Codex(gpt-5.3-codex)とClaude Code(claude-opus-4-6)で実装し、デモでの受付に成功しています。
この記事で扱う内容:
Reachy Mini の概要とセットアップ
OpenAI Realtime API の仕組み
Realtime APIのFunction Callingを使ってイベント受付を自動化した検証結果
Reachy Mini って何?
Reachy Mini は、机の上に置けるサイズのロボットです。カメラ、マイク、スピーカーを内蔵していて、AIと組み合わせれば「見て、聞いて、話す」ことができます。

開発したのは、フランス・ボルドーのPollen Robotics社です。2016年に設立されたロボティクス企業で、もともとはフルサイズの研究用ヒューマノイド「Reachy 2」を手がけていました。Reachy Mini はそのエントリーモデルにあたります。
2025年頃にHugging Faceに買収され、ソフトウェアもハードウェアも本格的にオープンソース化が進んでいます。
ソフトウェアのライセンスはApache 2.0、ハードウェアの設計ファイルはCreative Commons(BY-SA-NC)です。
また大部分がオープンソースであることも大きいです。自分で好きなAIモデルを載せたり、動きをカスタマイズしたりできます。今回の「音声AIを載せてイベント受付を自動化する」という実験も、オープンだからこそ可能でした。
一言でまとめると、「机の上に置けるオープンソースのAIロボット」です。

スペックと外観
高さは約28cm、重さは約1.5kgです。500mlのペットボトル2本分くらいの感じです。首が伸びた拡張時のサイズは30×20×15.5cmで、ノートPCの横に置いても邪魔になりません。


動かせる方向の数(DOF: Degree of Freedom)は合計9つです。内訳を見てみましょう。
頭部: 6方向(前後・左右に傾ける、上下に動かすなど。6本のアクチュエータで1つの台座を支える特殊な構造を使っています)
胴体: 360度回転
アンテナ: 左右それぞれ1本が独立して回転
頭を傾けたり頷いたりといった動きが自然にできるのは、この頭部の機構のおかげです。フライトシミュレータの座席にも使われている仕組みで、ロボットの頭としてはかなり贅沢な構造のようです。
搭載しているセンサーとデバイスを見ていきます。
カメラ
Raspberry Pi Camera Module 3(Sony IMX708、12メガピクセル、オートフォーカス)を搭載しています。画角は約120度の広角です。目の前の広い範囲を一度に見渡せるので、「何が見える?」と聞いたときに周囲の状況をまとめて把握できます。


マイク
4つのマイクが頭部の周囲に配置されています。4つある理由は、音がどの方向から聞こえてくるかを判別するためです。この仕組みを「音源定位」と呼びます。1つのマイクだけでは方向は分かりませんが、複数のマイクに届く音の時間差から方向を計算できます。人間が左右の耳で音の方向を判断するのと同じ原理です。
ベースとなっているのはSeeed Studio reSpeaker(XMOS XVF3800)というモジュールで、マイクの品質自体も悪くありません。感度-26 dB FS、信号対雑音比64 dBAです。

スピーカー
5W(4オーム)のスピーカーを1つ搭載しています。ロボットの声はここから出ます。小さな会議室であれば十分に聞こえる音量です。
アンテナ
頭の上にある2本のアンテナはモーター駆動で、サーボモーターで制御されています。耳のようにピクピク動くイメージです。

このアンテナで、驚き・喜び・考え中といった感情を表現できます。「表情」があることの効果は意外と大きくて、ゆっくり動き続ける呼吸モーション(常に微かに動くアニメーション)を入れるだけで「生きている」感が生まれています。機械が、急に存在感を持ち始めます。
Lite版とWireless版の違い
Reachy Mini には2つのモデルがあります。
Lite版($299)
PCとUSB-Cケーブルで接続して使う
電源は壁コンセントから供給
Mac / Linuxに対応(Windows近日対応予定)
処理はすべてPC側で行う
Wireless版($449)
Raspberry Pi Compute Module 4(小型コンピュータ)を内蔵しており、PC不要で動く
Wi-Fi / Bluetooth接続
バッテリー内蔵で約2〜4時間駆動
加速度センサー搭載
持ち運んで単体で動かせる
判断基準としてはPCを常時つなげる環境で、まず試してみたいならLite版。持ち運びたい、あるいはPC無しで動かしたいならWireless版といった具合です。価格差は$150です。
今回の検証ではLite版を使いました。MacBook ProにUSB-Cで有線接続し、音声AIやPC操作の処理はすべてMac側で行っています。
セットアップ
本体は部品がバラバラの状態で届きます。自分で組み立てる必要がありますが、ロボット初心者でも約3時間で完成しました。公式の組み立てガイド動画もあるのでこちらも参考にしました。

Reachy Mini の制御にはPython SDKを使います。
インストールは uv が推奨されています。uv はPythonのパッケージマネージャーで、従来の pip と同じことができますが、速度が桁違いに速いです。初めての方は pip でも問題ありません。
# uvの場合(推奨)
uv pip install reachy-mini
# pipの場合
pip install reachy-mini
最小限のコード例:
以下のコードで、Reachy Mini の頭を動かせます。
from reachy_mini import ReachyMini
from reachy_mini.utils import create_head_pose
with ReachyMini() as mini:
mini.goto_target(
head=create_head_pose(z=10, roll=15, degrees=True, mm=True),
duration=1.0
)カメラの映像取得や音声の処理も、同じようなシンプルなAPIで制御できます。Pythonを触ったことがある方なら、すぐに動かせるはずです。
コードを書かずに動かす方法もあります。公式の「Reachy Mini Control」アプリを使えば、GUI上のコントローラーから各関節をリアルタイムに操作できます。動きの感覚を掴むのに便利です。

もう1つ特徴的なのが、Hugging Faceとの連携です。Hugging Face Spaces経由で、15種類以上のプリセットアプリ(会話、手の追跡、物語の読み聞かせなど)がワンクリックでインストールできます。ゼロからコードを書かなくても、まず動くデモを試せる仕組みが整っています。
また、MuJoCoシミュレータを使えば、実機がなくてもPC上でモーションの動作確認ができます。GitHubにシミュレーション環境が公開されているので、購入前に動きの雰囲気を掴むこともできます。
なお、本体はDIYキットとして届きます。組み立て時間は約2〜3時間です。公式のアセンブリガイドがHugging Face Spacesで公開されており、手順に沿って進めれば問題なく組み上がります。
OpenAI Realtime APIって何?
ChatGPTの「声」の裏側
ChatGPTの音声モードを使ったことがある方は多いと思います。スマホに話しかけると、AIが声で返してくれる機能です。Realtime APIは、あの体験の裏側で動いている技術を、開発者が自分のアプリに組み込めるようにしたものです。
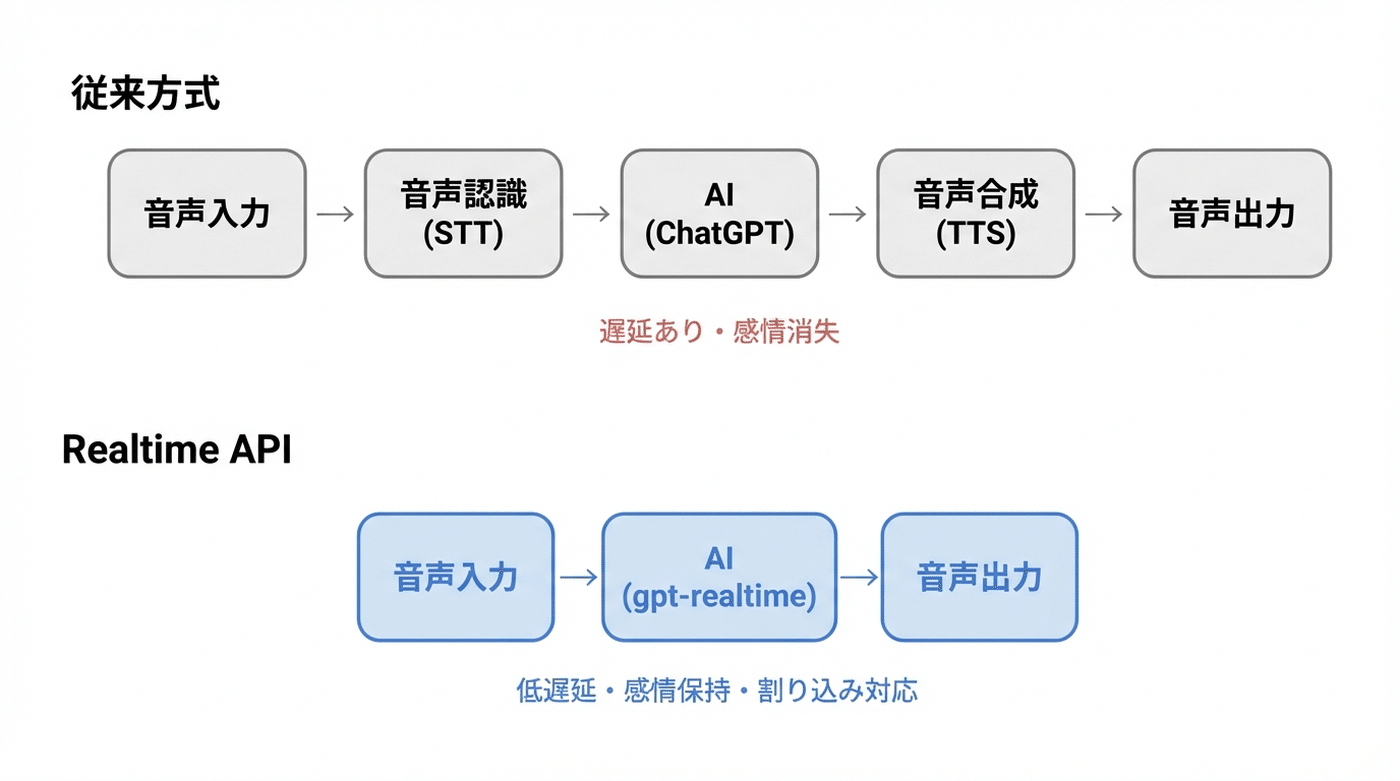
従来の方式では、3つのステップを順番に踏んでいました。
まず、人の声をテキストに変換する(音声認識)
次に、そのテキストをAIに渡して回答を得る
最後に、回答テキストを音声に変換する(音声合成)
この3段階を経由するため、どうしても待ち時間が生まれます。さらに、テキストに変換する時点で、声のトーンや感情のニュアンスが消えてしまいます。
Realtime APIはこの問題を根本から解消しました。音声を直接AIに渡し、AIが直接音声で返す。中間のテキスト変換を省いた「直通回線」です。応答が速くなるだけでなく、声の抑揚や感情も保持されます。さらに、AIが話している途中でも人が割り込んで中断できる(割り込み対応)という、自然な会話に近い振る舞いも可能です。
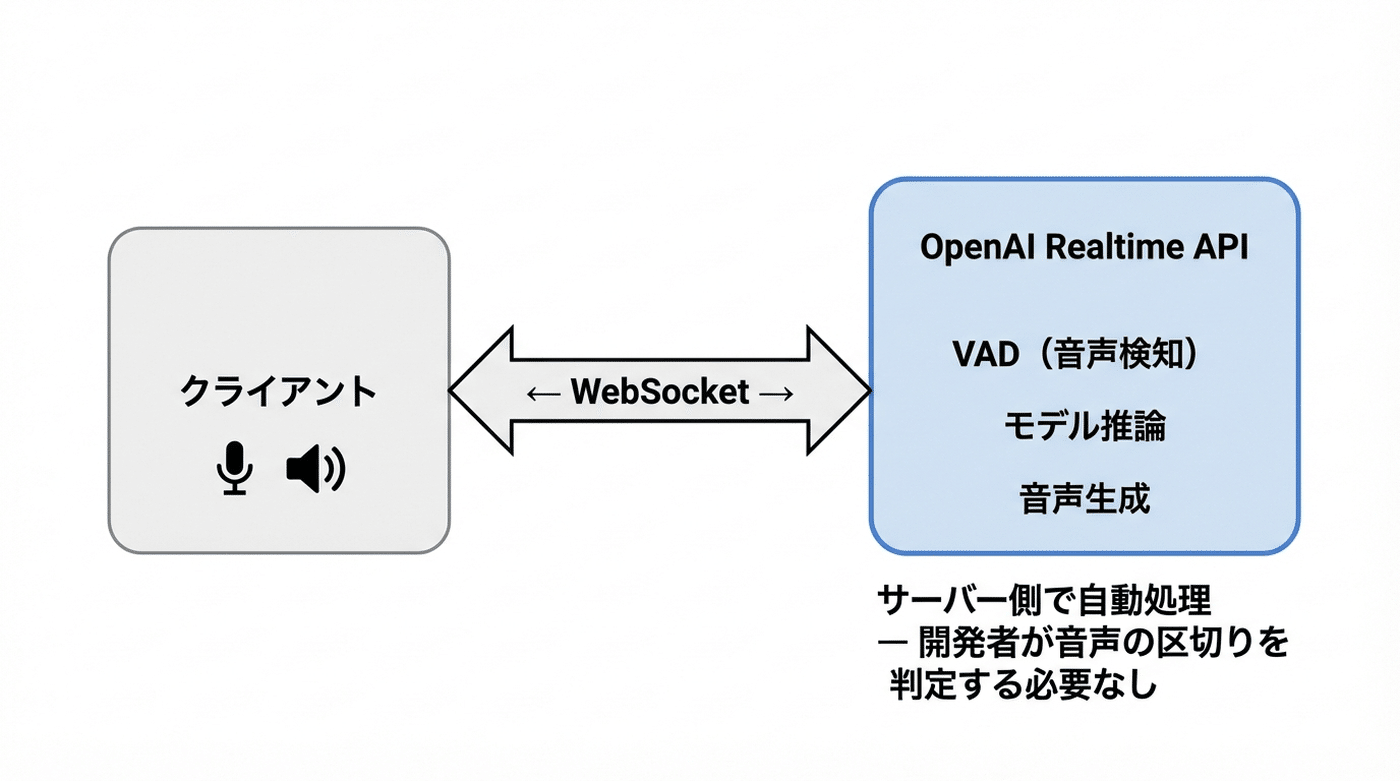
仕組み — リアルタイム通信と音声検知
Realtime APIは、リアルタイム通信の仕組み(WebSocket)を使って動いています。一度接続すると、サーバーとクライアントの間でデータを双方向にやりとりし続けられる通信方式です。電話回線のようなもの、と考えるとイメージしやすいかもしれません。
音声会話で重要になるのが、音声検知(VAD: Voice Activity Detection)という仕組みです。「人が話し始めたタイミング」と「話し終わったタイミング」を自動で判定してくれます。
VADには2つのモードがあります。
音量ベース(server_vad): 一定以上の音量を検知したら「話し始め」、一定時間の無音が続いたら「話し終わり」と判定する。しきい値(threshold)と無音判定時間(silence_duration_ms)を調整できる
意味ベース(semantic_vad): 文脈から「まだ話し続けるのか、もう終わったのか」を推測して判定する。「えーと...」のような言い淀みでも誤って「終わった」と判定しにくい
どちらのモードでも、VADはサーバー側で自動処理されます。開発者が自分で音声の区切りを判定する必要はありません。
ただし、VADには1つ大きな特性があります。「音声があるかないか」で判定するため、誰が話しているかは区別しません。マイクに入る音であれば、周囲の別の人の会話であっても「ユーザーが話した」と認識する可能性があります。この特性は、この記事の後半で再び登場します。
対応モデルは、2026年2月リリースの gpt-realtime-1.5 がフラッグシップです。従来の gpt-4o-realtime-preview 系と比べて、指示に対する追従精度やツール呼び出しの安定性、多言語対応が向上しています。低コスト版の gpt-realtime-mini もあります。最大セッション時間は60分です。
ツール呼び出し機能(Function Calling)
Realtime APIの中で、今回の検証において最も重要な機能がツール呼び出し機能(Function Calling)です。
通常の音声会話では、AIにできることは「話す」ことだけです。ツール呼び出し機能を使うと、会話の中で外部のツールを動かすことができます。「音声で何かをやらせる」を実現する仕組みです。
流れはこうなっています。
ユーザーが音声で指示を出す(「ニュースを検索して」)
AIが「これはツールを使うべきだ」と判断する
事前に定義しておいたツール(関数)を呼び出す
ツールの実行結果がAIに返る
AIが結果を音声で報告する(「OpenAIの最新ニュースを3件見つけました」)
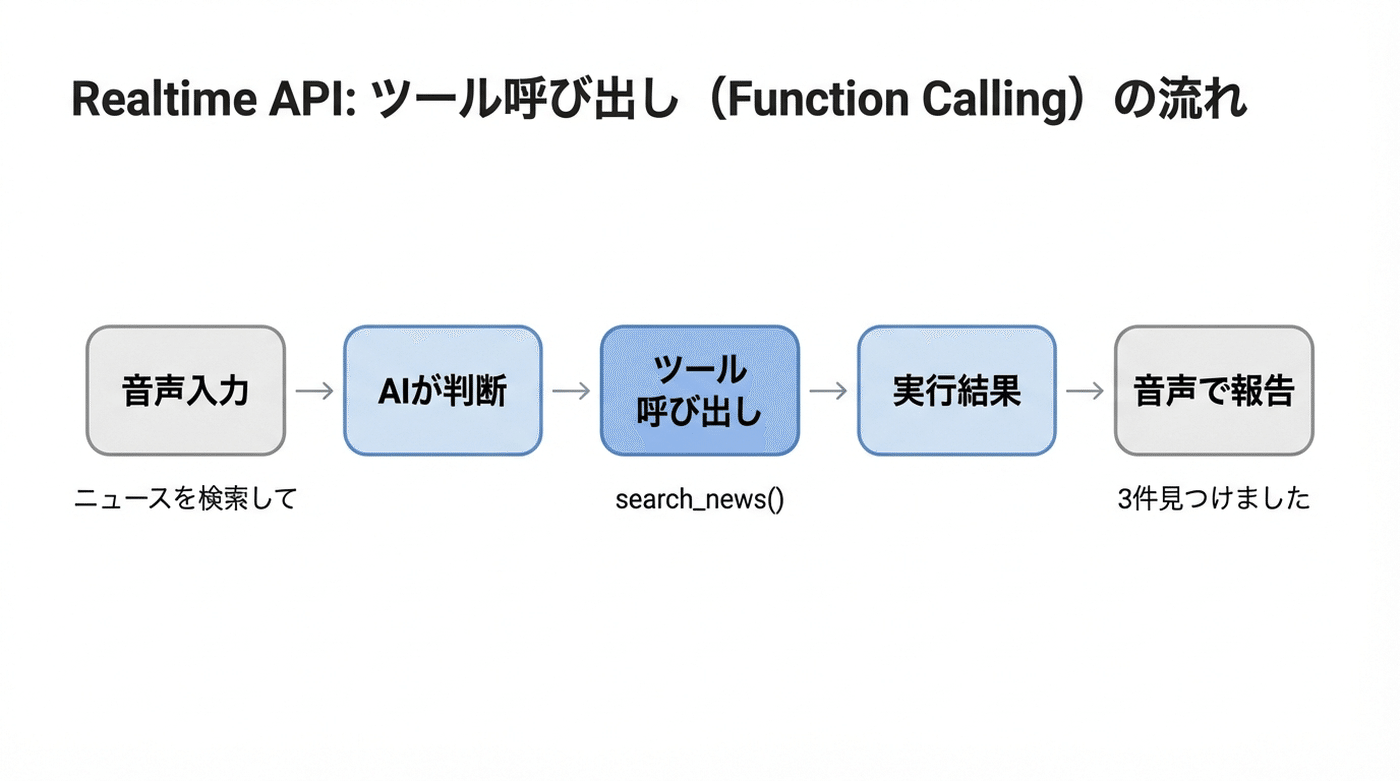
この流れの中で、ツールの部分にLumaのチェックイン機能を接続すれば、「声でイベント受付を実行して、結果を声で教えてもらう」という体験が成り立ちます。これが今回のシステムのキモです。
料金感
Realtime APIの料金は、テキストAPIと比べると高めです。
gpt-realtime-1.5の主な単価です。
音声入力: 100万トークンあたり $32.00
音声出力: 100万トークンあたり $64.00
テキスト入力: 100万トークンあたり $4.00
テキスト出力: 100万トークンあたり $16.00
音声トークンの単価は、テキストの約4〜8倍です(入力側は約8倍、出力側は約4倍)。音声1トークンは入力側で約100ミリ秒、出力側で約50ミリ秒に相当します。入力側で10秒間の発話がおおよそ100トークン、出力側は同じ10秒で約200トークンという換算です。
低コスト版の gpt-realtime-mini であれば、音声入力 $10.00 / 音声出力 $20.00 と約3分の1になります。
セッション維持の固定費用はかかりません。キャッシュを活用すれば、入力トークンのコストを大幅に抑えることも可能です。テキストAPIと比べると高価ですが、「音声→テキスト変換→AI→テキスト→音声合成」の3サービスを個別に呼ぶ従来方式と比較すれば、一概に割高とは言えません。
標準搭載のConversationアプリでまず会話してみる
Reachy Mini標準のConversationアプリとは
カスタムツールとの統合に入る前に、Reachy Mini単体でどこまでできるかを見ておきます。
Pollen Robotics公式が提供するConversationアプリは、Reachy Miniに音声会話機能を追加するアプリケーションです。Hugging Face Spacesや「Reachy Mini Control」アプリからインストールでき、OpenAIのAPIキーを設定するだけで動きます。

仕組みはシンプルです。Reachy Miniのマイクで声を拾い、AIが応答を生成し、スピーカーから返答が流れる。それだけでなく、応答に合わせて首を動かしたり、アンテナを振ったりするモーションも付きます。
実際に会話してみる
実際に使ってみた所感です。
応答の遅延はほとんど感じません。話し終わってから返答が始まるまで、体感で0.3秒前後です。1秒もかかりません。
5Wスピーカーの音量と明瞭さは、デスク上で使う分には十分です
首を傾げたり、アンテナがぴょこぴょこ動いたりしてくれるので、画面に文字が表示されるのとは異なり「ロボットと会話している」という感覚が自然に生まれます
できること、できないこと
標準のConversationアプリだけでも、音声対話とモーションの組み合わせは十分に成立しています。「冗談を言って」と頼めば首を傾げながら話してくれます。
ただし、できることは「会話」の範囲に限られます。「ブラウザでニュースを検索して」と頼んでも、ブラウザは開きません。「イベントの受付をやって」と言っても、PC上の操作は何も起きません。
また騒音がある場所や複数人から声をかけられると対応できません。
では、ここにカスタムツールを持った音声AIエージェントを組み合わせるとどうなるか。次のセクションで、Reachy Miniを「声だけでツールを操作できるロボット」に拡張していきます。
有料パートでは以下の2つの素材を掲載します。
Codexに渡した仕様書 — そのままCodexやClaude Codeに渡せば同じシステムが立ち上がります
API解析に使ったClaude Codeプロンプト — Claude in ChromeでDevToolsを解析させた実例です





