

2025年3月21日、OpenAIはライブストリーミングにて音声モデルに関する開発者向け大規模アップデートを発表しました。
今回の発表では、リアルタイム音声処理や高精度の文字起こし・自然な音声合成など、多岐にわたる改良がなされています。以下、主要なポイントをまとめます。

① Audio / Speech機能アップデートの概要
まず、音声関連のAPIが一斉に強化・拡充されました。
具体的には以下がポイントとなります:
新モデル: gpt-4o-transcribe(高精度な文字起こし)、gpt-4o-mini-tts(リアルタイム音声合成)
ストリーミング対応: 音声の入出力をリアルタイムでやり取り
マルチモーダル処理: テキスト+音声の両方を同時に扱える設計

多言語対応も引き続き強化されており、ファイルサイズなどの制約はあるものの、実用性は格段に向上している印象です。
② Realtime APIの強化
Realtime APIは、音声のリアルタイムな入出力処理を可能にするAPIです。
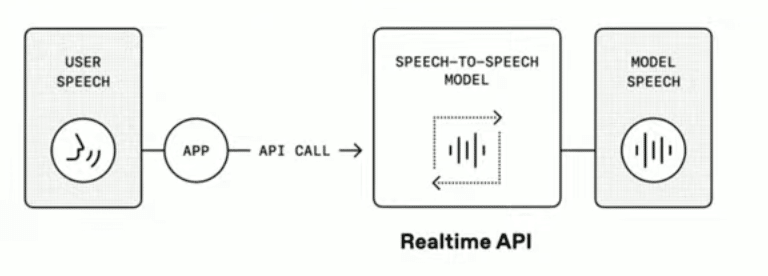
今回のアップデートにより以下の機能が追加されました。
新モデル gpt-4o-realtime-preview の利用
ノイズキャンセリング機能の搭載で背景音による誤認識を防止
Semantic Voice Activity Detector(セマンティック音声活動検出)により、ユーザーが発話を終えたタイミングを自動的に判断し、音声を適切に区切って処理可能
これにより、遅延の少ない、安定したリアルタイム音声対話が可能になります。
③ Speech to Text(文字起こし)の強化
これまでWhisperを中心に提供されていた文字起こし機能に、新たにgpt-4o-transcribeおよびgpt-4o-mini-transcribeが追加されました。
さらに:
翻訳機能: /audio/translations で英語への変換が可能
25MBファイル上限は継続だが、ストリーミングで大きいファイルにも実質対応
プロンプト指定やGPT-4oによる事後補正で固有名詞の認識精度を上げるなどの工夫も容易
Whisperシリーズよりも高精度・多機能といわれており、ビジネスユースでの評価が進みそうです。
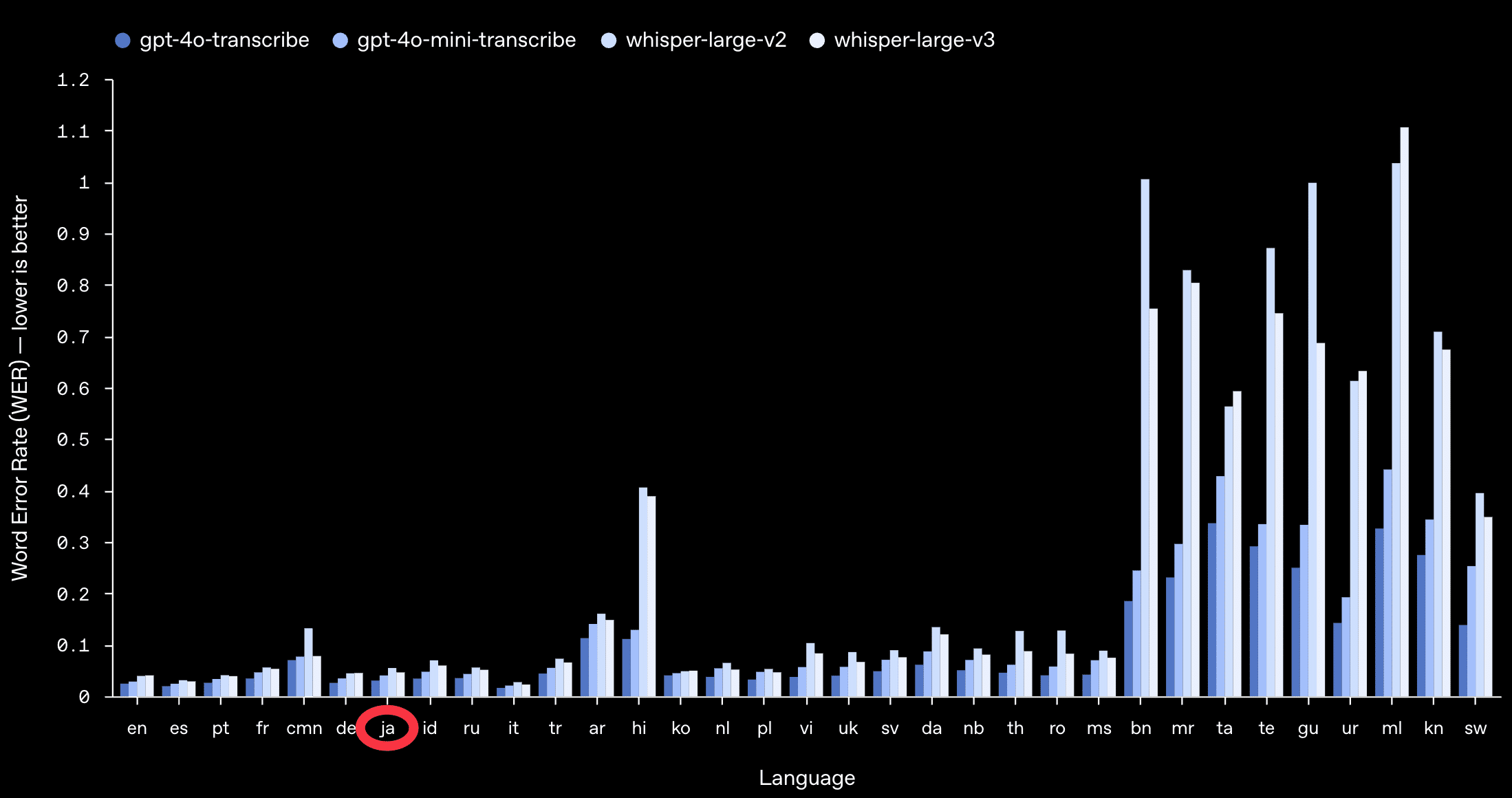
日本語は右端のJAの部分:
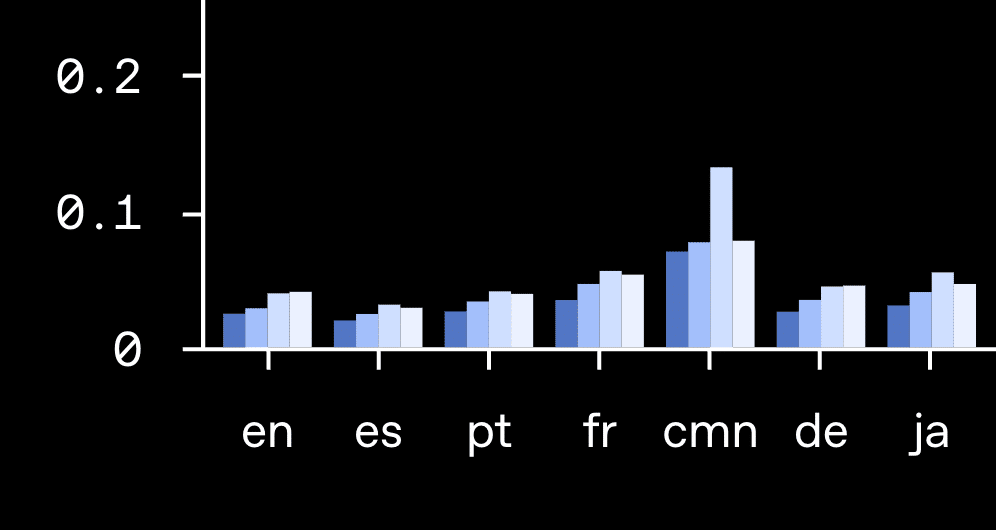
④ Text to Speech(音声合成)の改善
音声合成もgpt-4o-mini-ttsモデルを中心に一気に強化されました。
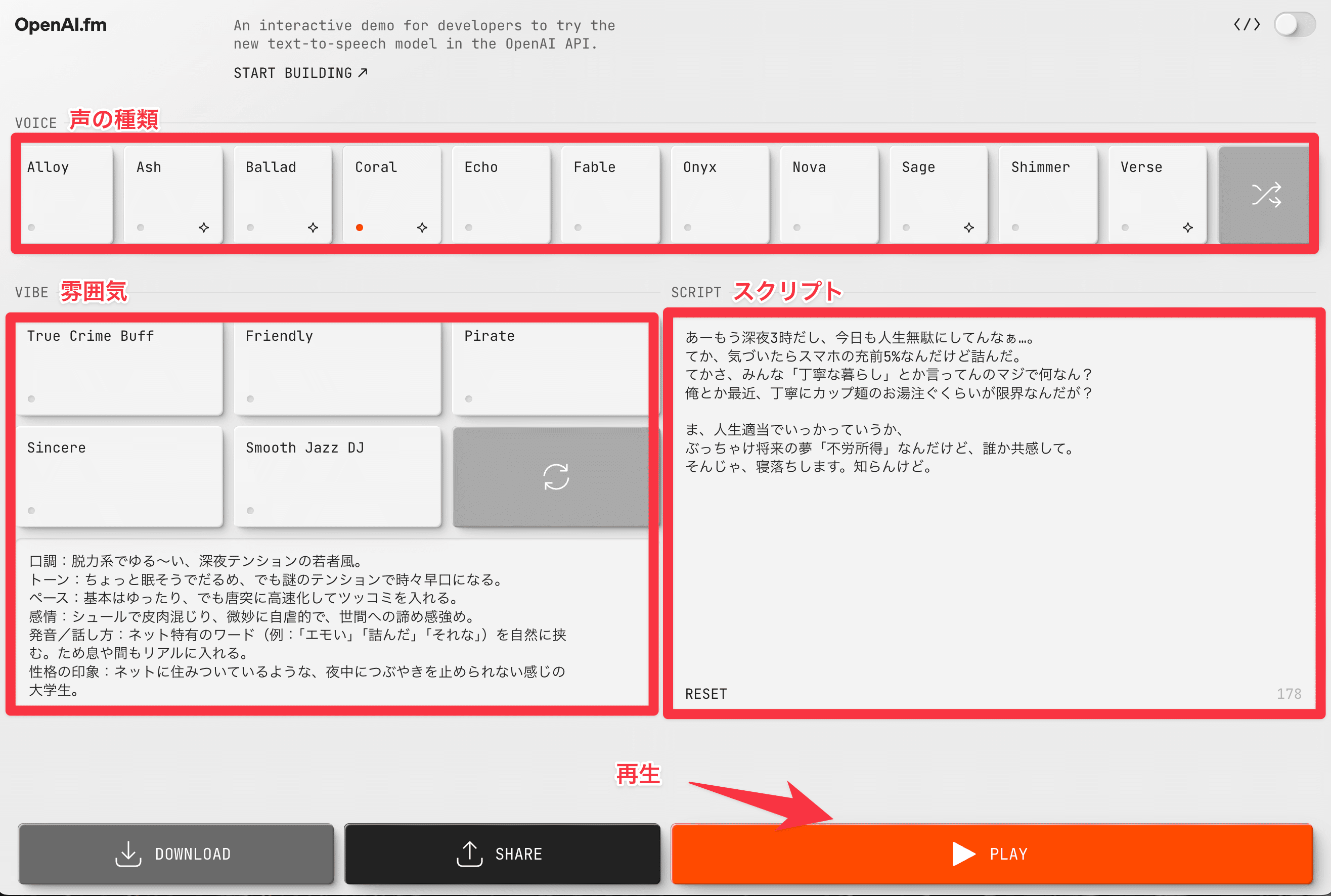
11種類のビルトイン音声: alloy, coral, ashなど、声質を選択可能
ストリーミング再生: 生成途中から音声を再生し始められるので、待ち時間を短縮
感情表現やイントネーションなどもある程度制御可能
以下の動画のとおり、日本語でも非常に高い精度が期待できます。
https://twitter.com/ctgptlb/status/1902780784769118383
現在 openai.fm から無料で誰でも試すことができます。
ただし、ユーザーにAI音声であると明示する必要があるなど、利用上のガイドラインは引き続き遵守する必要がある点には注意が必要です。
⑤ ボイスエージェントの構築が容易に
今回のアップデートにより、「音声入力+音声出力」による対話型エージェントの実装がさらに簡単になりました。
(1) Speech-to-speech(S2S)アーキテクチャ
マルチモーダルモデル:音声を直接入力→音声出力で返答
余計なテキスト変換が不要なので、ユーザーの抑揚や意図を聞き取りやすい
(2) チェーン型アーキテクチャ
一度テキスト化してLLMで処理→最後に音声に変換
ログ取得や内容の制御がしやすいメリットも
使うシーンに応じて、リアルタイム性重視か管理性重視かを選べるようになった点は大きいです。
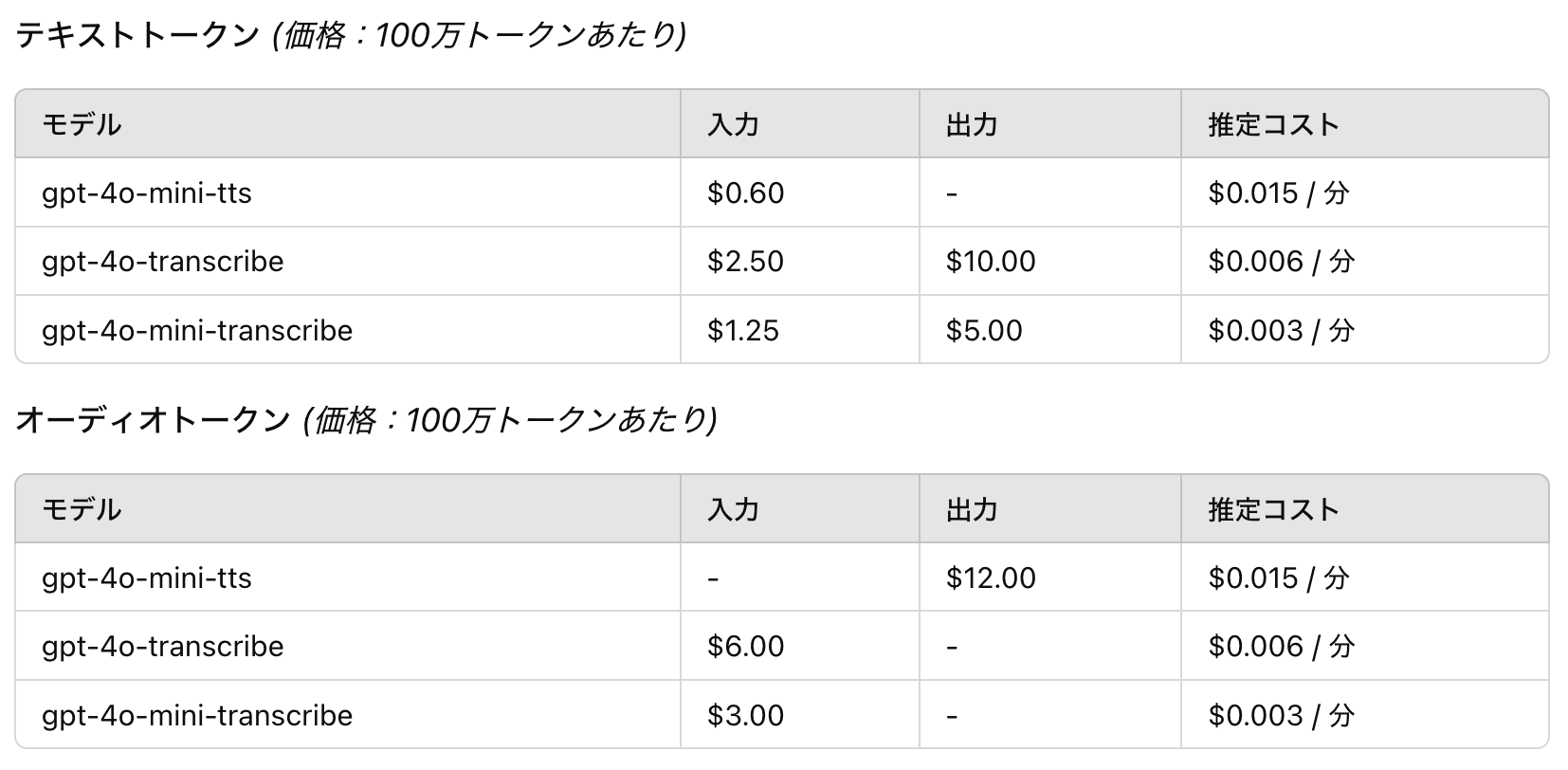
価格
価格は以下の通りとなっています:
gpt-4o-mini-tts: $0.60(テキスト入力), $12.00(オーディオ出力)
gpt-4o-transcribe: $2.50(テキスト入力), $10.00(テキスト出力), $6.00(オーディオ入力)
gpt-4o-mini-transcribe: $1.25(テキスト入力), $5.00(テキスト出力), $3.00(オーディオ入力)
OpenAIが音声プロンプト作成コンテスト『OpenAI Radio』を開催!
OpenAIは、今回発表した新しい音声プロンプト作成コンテスト『OpenAI Radio』を発表しました。オリジナルの音声プロンプトをOpenAIの音声プラットフォーム「OpenAI.fm」で作成し、Xに投稿することで、特製スピーカーが当たるチャンスがあります。

コンテスト概要
応募期間:2025年3月21日午前2時 ~ 3月22日午後3時59分(日本時間)
応募方法:
OpenAI.fmでオリジナルの音声プロンプトを作成。
「Share」機能を使用してリンクを生成。
生成したリンクをXの公開アカウントで投稿。
審査基準(50%ずつ)
「Vibe」プロンプト:声のトーンや話し方を工夫した表現。
「Script」プロンプト:30秒間のストーリーを音声で表現し、途中でトーンを変えるタグを活用するなど、創造性豊かな工夫。
賞品
OpenAI特製スピーカー『Teenage Engineering OB-4』
(600ドル相当・最大3名)
OpenAIロゴ付きです:

詳細リンク
コンテスト会場:https://openai.fm
コンテスト詳細ルール:https://openai.fm/contest.txt
ぜひこの機会に参加してみてください!
まとめ
今回の音声関連アップデートは、音声処理における速度・精度・多様性の面で一気にハードルを下げるものになりそうです。
リアルタイム会話や高度な文字起こし、自然な音声合成を一度に使いこなせるようになったことで、これから登場する音声AIアプリケーションがどんな形をとるのか、非常に楽しみなタイミングです。





