

日本時間2025年8月26日、Googleは新たな画像生成・編集モデル「Gemini 2.5 Flash Image」(通称: nano-banana)をプレビュー版としてリリースしました。
かねてより「nano-banana」の通称で噂されていた、正体不明ながらも高性能な画像編集モデルの正体が、今回の「Gemini 2.5 Flash Image」です。自然言語による精密な部分編集やキャラクターの一貫性維持に優れているとコミュニティで話題になっていましたが、今回の発表でGoogle製のモデルであることが正式に確認されました。
今回のアップデートでは、複数の画像を自然に融合する機能や、同一キャラクターを異なるシーンで描画する一貫性維持機能、自然言語による精密な画像編集、Geminiモデルの持つ広範な知識の活用が可能になりました。
単なる画像生成に留まらず、より実用的な編集・対話機能が統合された点が大きな特徴です。

機能の詳細
客観的な性能評価として、公開ベンチマーク「Image Edit Arena」ではEloスコア1362を記録し、2位のモデルに大差をつけてトップの評価を獲得しています。
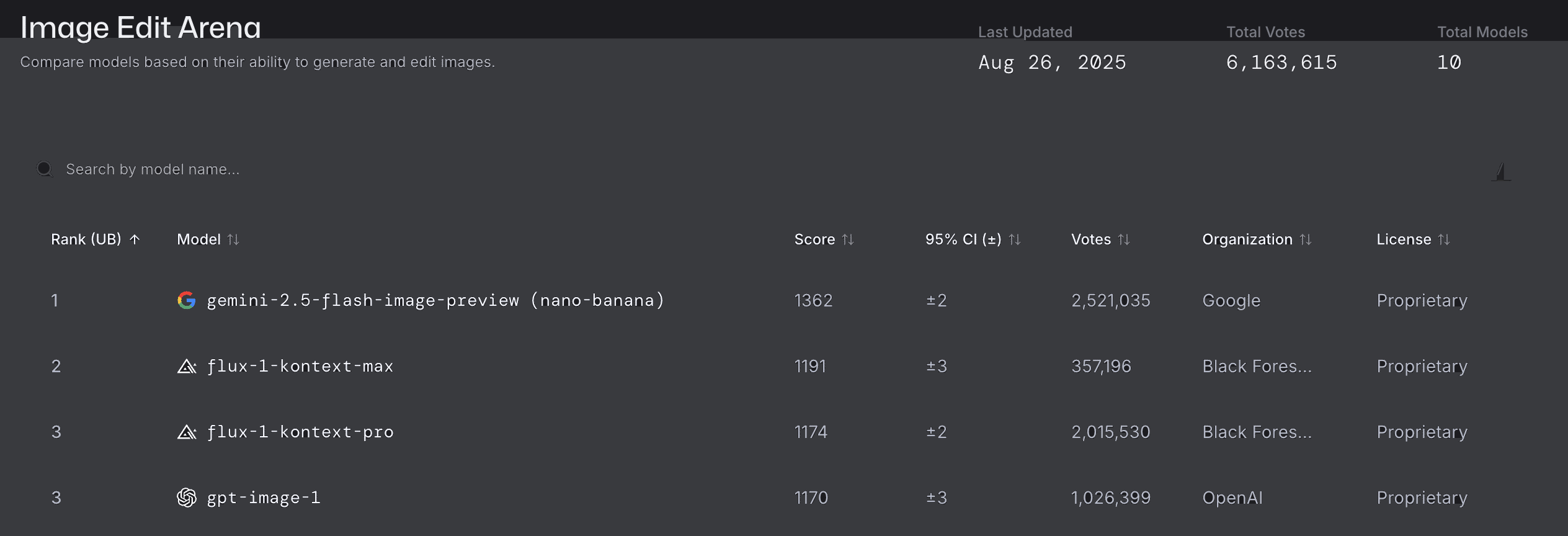
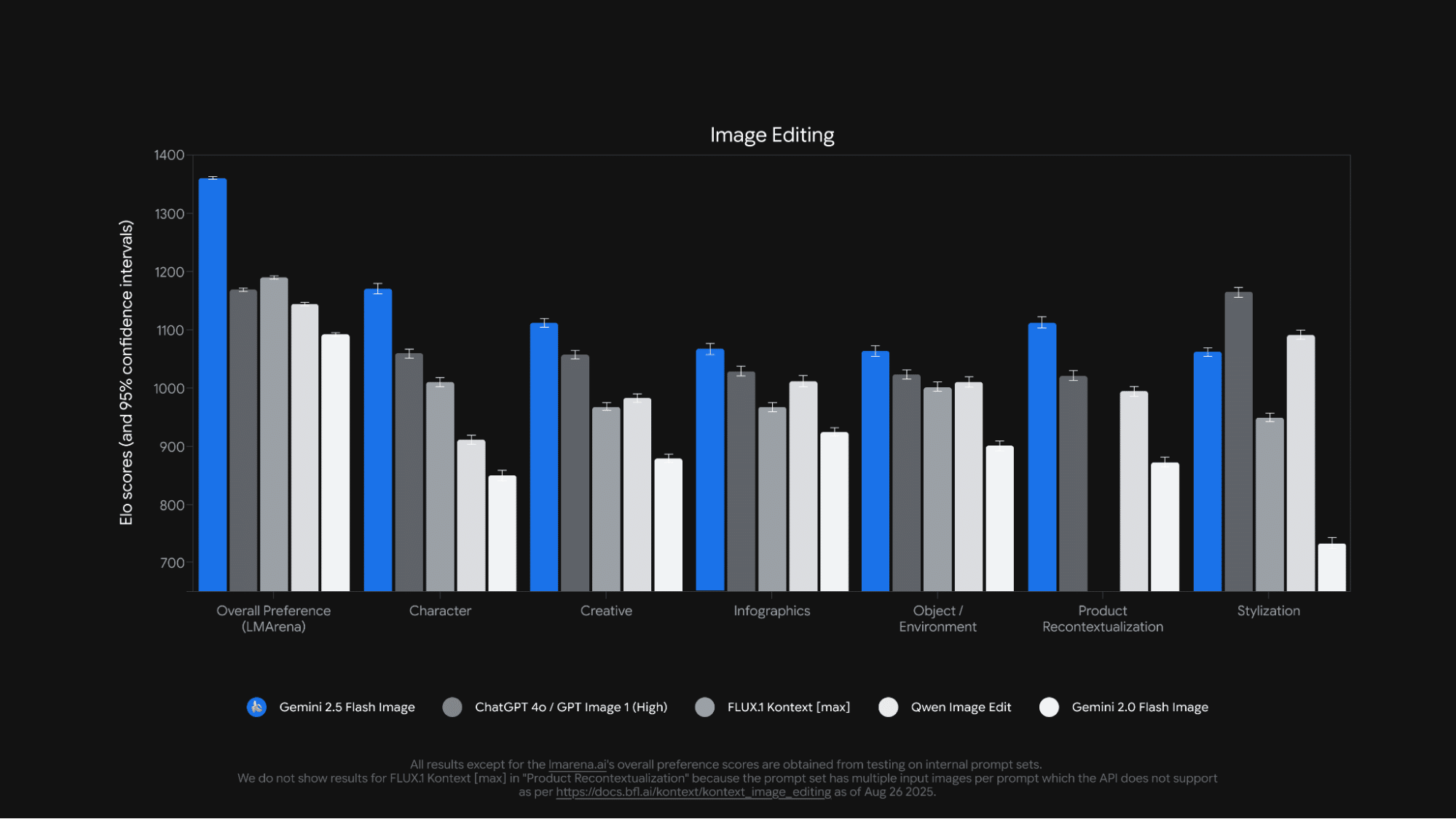
また、Googleが公開したベンチマーク結果によると、「キャラクターの一貫性」や「クリエイティブな編集」など多くの項目で、既存の主要な画像編集モデルを上回る性能を示しています。
特徴
今回のアップデートで実現した主な特徴は以下の通りです。
キャラクターの一貫性 (Character consistency): 同一のキャラクターやオブジェクトを、異なる背景、ポーズ、シーンで一貫性を保ったまま生成できます。

上記を生成するために用いたオリジナル画像:

プロンプトベースの画像編集: 自然言語の指示のみで、背景のぼかし、オブジェクトの除去・置換、被写体のポーズ変更、白黒写真のカラー化など、精密な局所的編集を実行できます。マスク指定なしで直感的な編集が可能です。

ネイティブな世界の知識 (Native world knowledge): Geminiモデルの広範なナレッジベースを活用し、手描きの図の意図を理解したり、画像に関する質問に回答したりするなど、対話的な利用ができます。
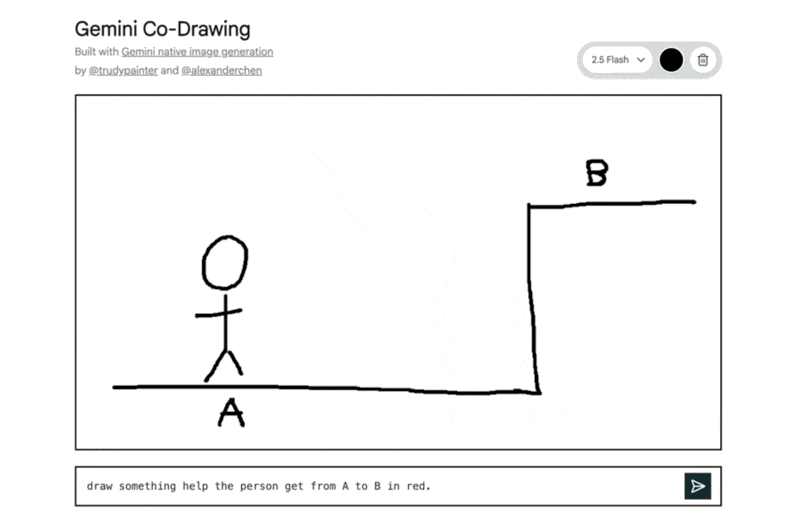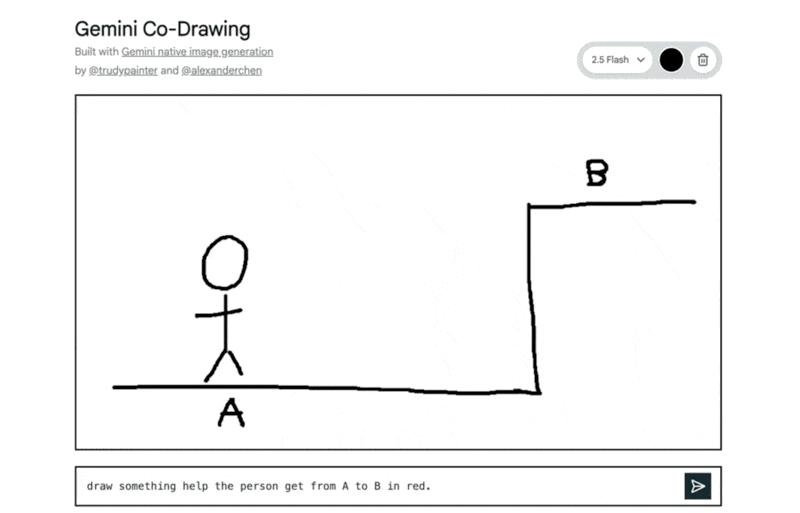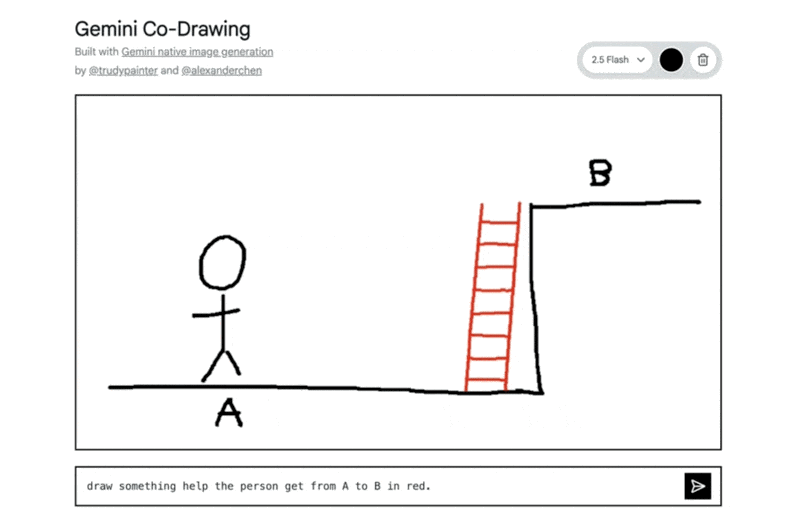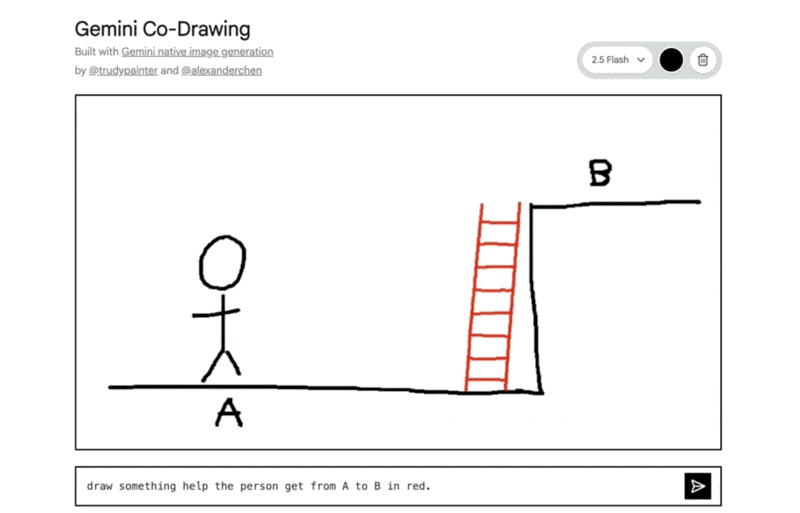
「AからBへ移動するのを助けるものを赤で描いて」という指示で、はしごが追加された例:
複数画像の融合 (Multi-image fusion): 複数の入力画像を理解し、自然な形で1枚のフォトリアルな画像に合成できます。例えば、ある3枚の写真をアップして、それらを違和感なく配置することが可能です。

活用例
今回のアップデートでは、具体的な目的に役立つ実用的な機能が強化されています。公式ブログで紹介されている主な活用例は以下の通りです。
一貫したキャラクターでのクリエイティブ制作: 同一人物の写真を元に、異なる時代設定の肖像写真や、スポーツ選手のトレーディングカードのような、多様なスタイルの画像を生成できます。ブランドアセットやストーリー制作への応用が期待されます。

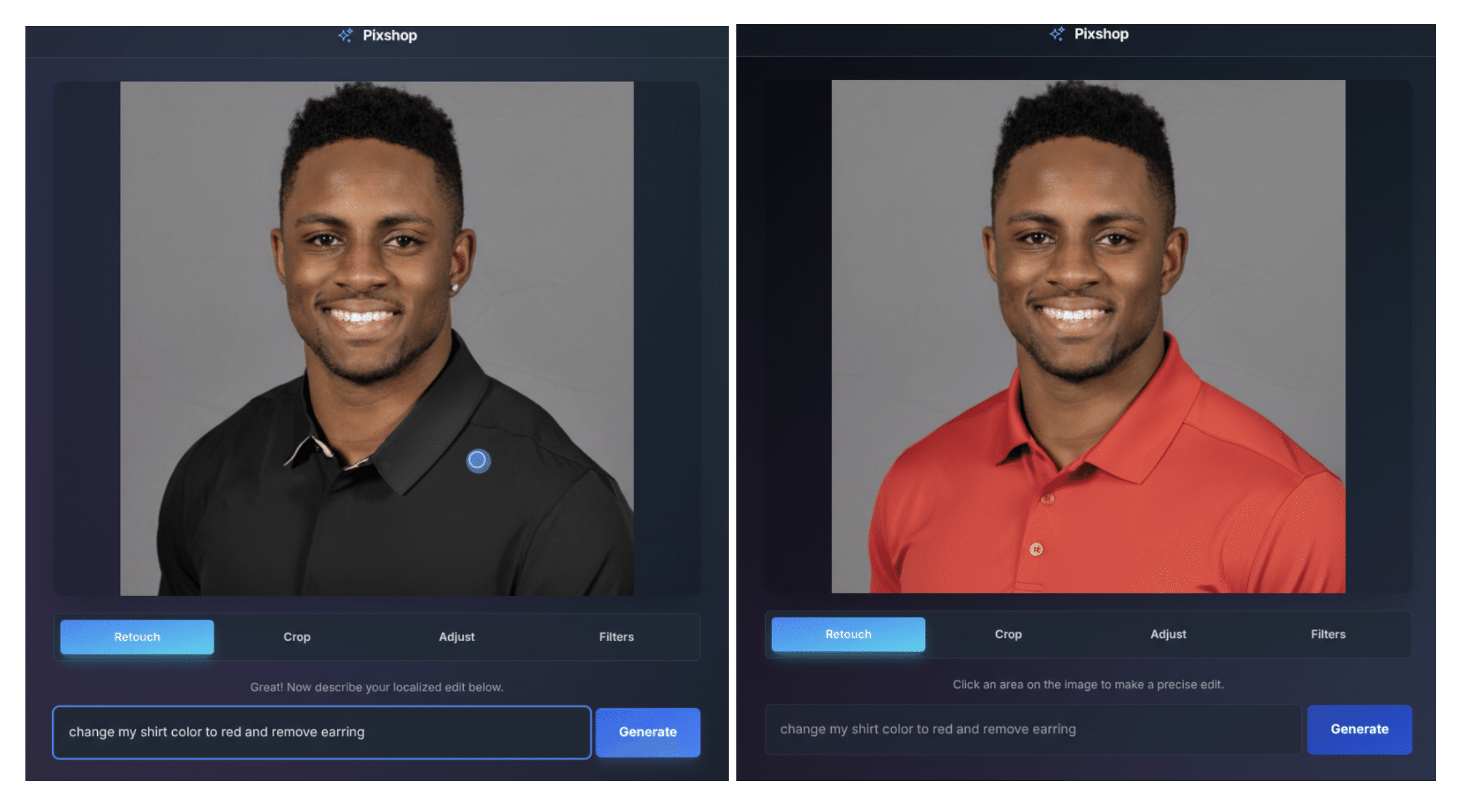
ECサイト向けの写真編集: プロンプトによる指示だけで、商品写真のシャツの色を変更したり、不要な部分を自然に除去したりするなど、迅速な画像修正が可能です。
プロンプト指示によるシャツの色変更例:
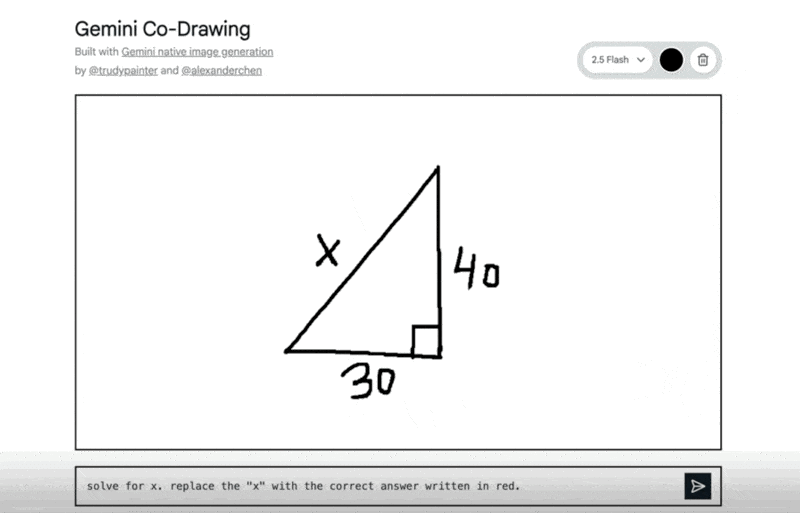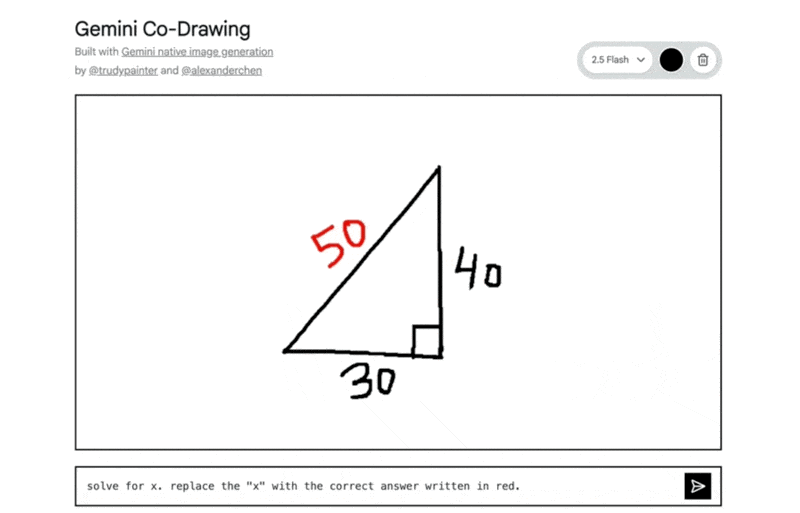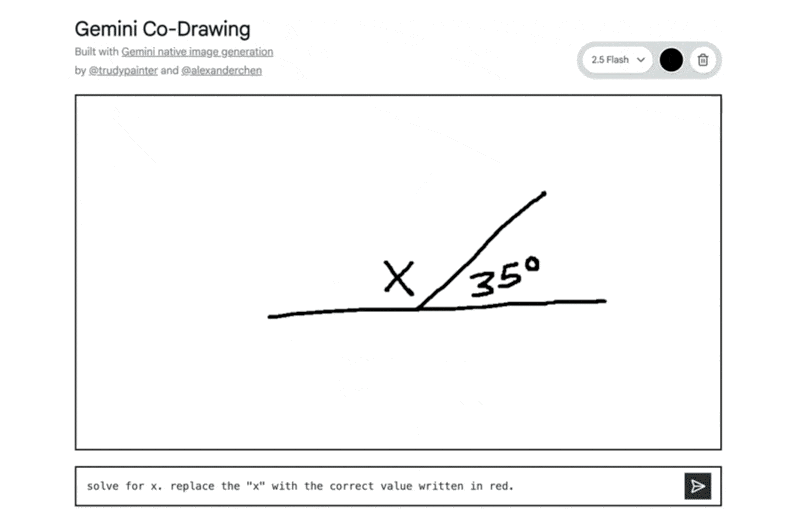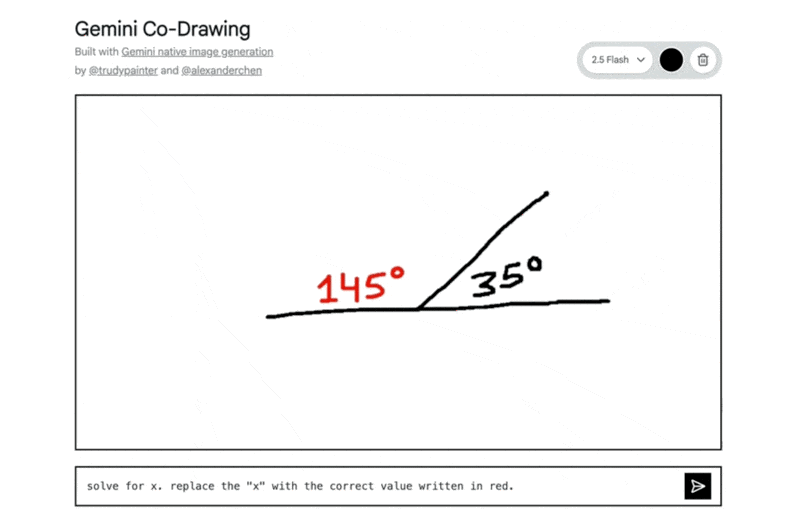
インタラクティブな教育コンテンツ: 手描きの図形問題をモデルが正確に理解し、解答を指示通りに書き込むなど、教育・学習分野での活用が見込まれます。
手描きの図形から三平方の定理を解き、指示通り赤色で解答した例:
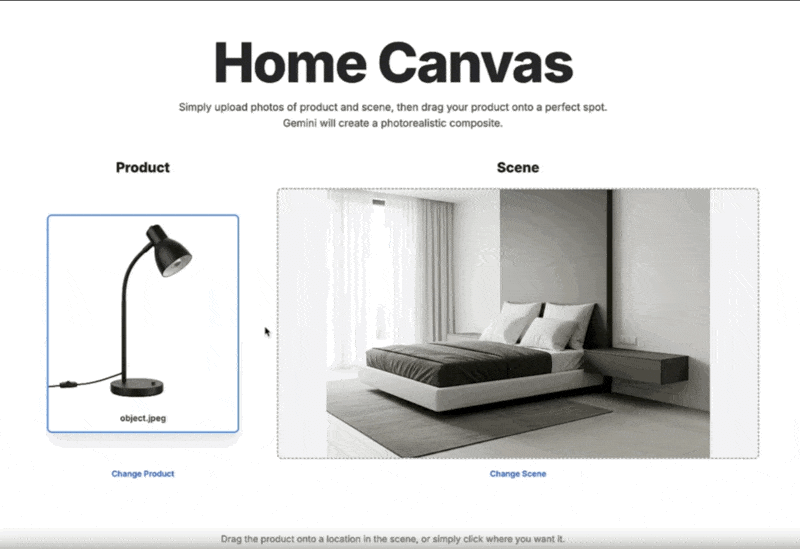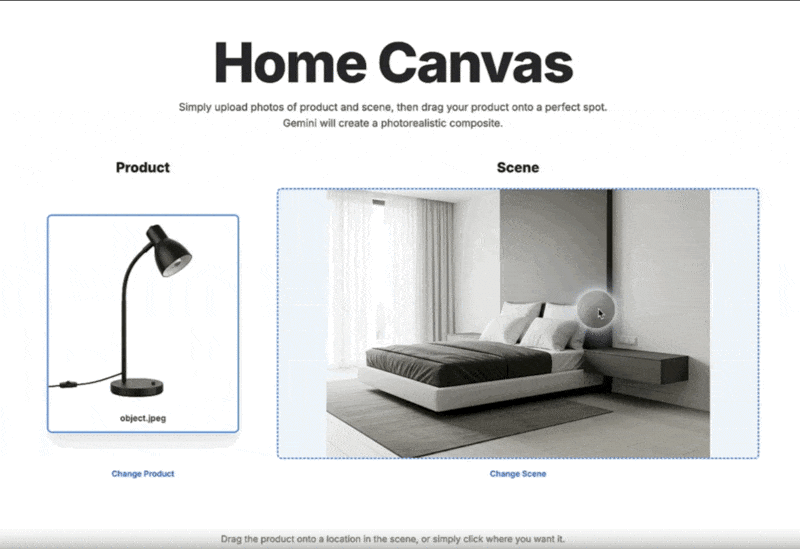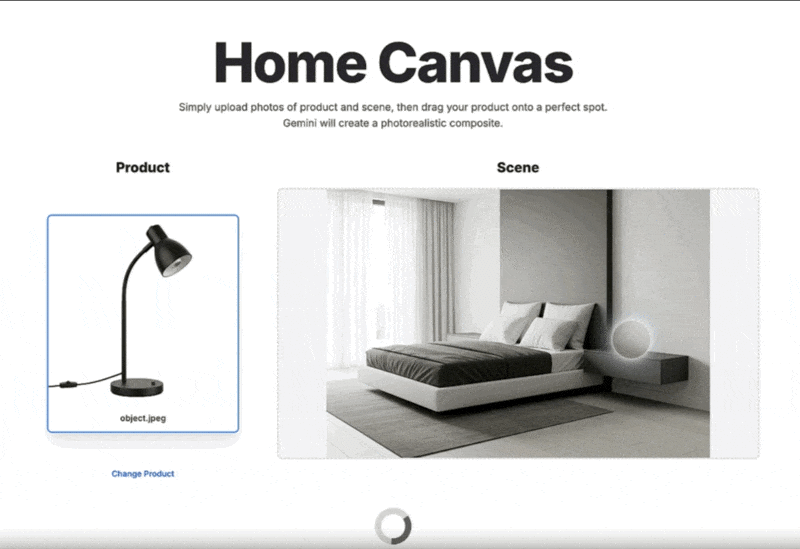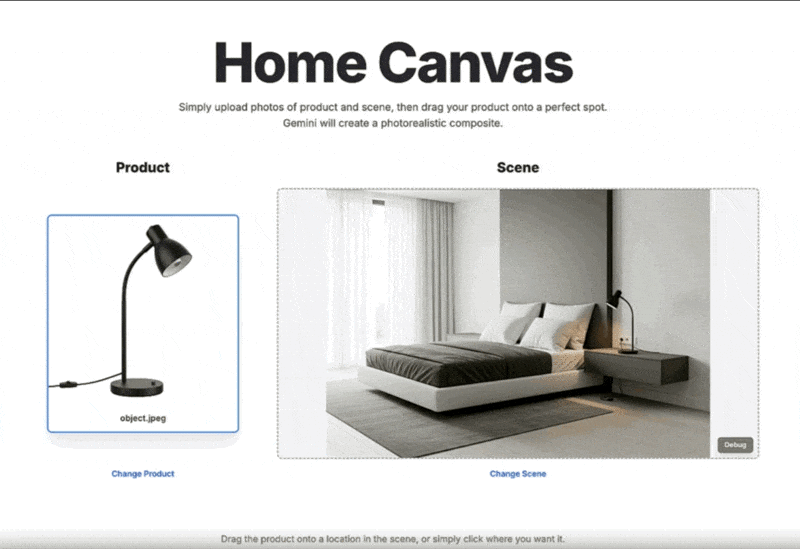
インテリアや商品配置のシミュレーション: 家具などの商品画像を、実際の部屋の風景写真にドラッグ&ドロップ操作で自然に合成し、配置後のイメージを即座に生成できます。
アクセスと使い方
Gemini 2.5 Flash Imageは、プレビュー版としてリリース当日から利用可能です。今後数週間以内に安定版へ移行する予定です。
提供開始と対象ユーザー
Gemini App
Google AI Studio (無料で試用可能)
Gemini API (開発者向け)
Vertex AI (エンタープライズ向け)
パートナープラットフォーム (OpenRouter.ai, fal.ai)
開発者向けAPI
開発者はGemini APIを通じて本機能を利用できます。料金は1画像あたり$0.039で、これは100万出力トークンあたり$30.00のレート(1画像=1290トークン)に基づいています。
利用方法
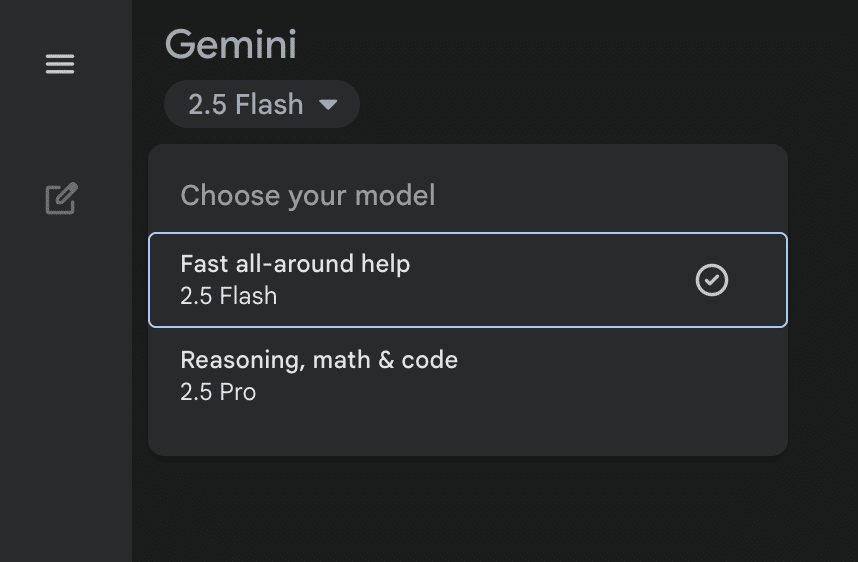
Gemini Appでの利用:
チャット画面左上のモデル選択メニューから「2.5 Flash」を選ぶことで、画像編集機能が利用できます。画像をアップロードし、プロンプトで編集指示を入力するだけで、自然な画像編集が可能です。
Google AI Studioでの利用:
Google AI Studioでは、2つの方法で利用できます。
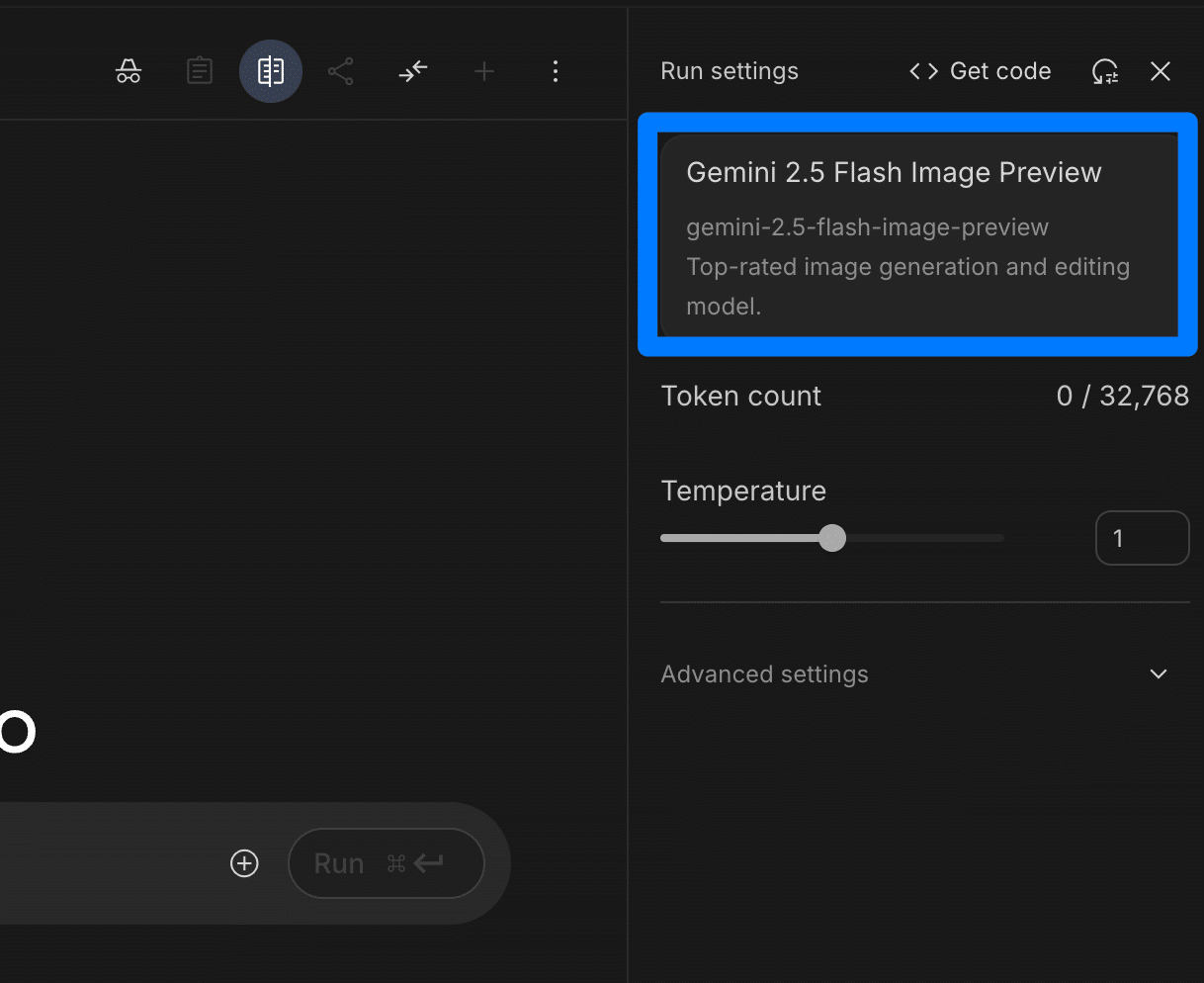
①チャット形式での利用:
画面右側の設定(スライダーアイコン)をクリックし、表示されるモデル一覧から「Gemini 2.5 Flash Image Preview」を選択します。
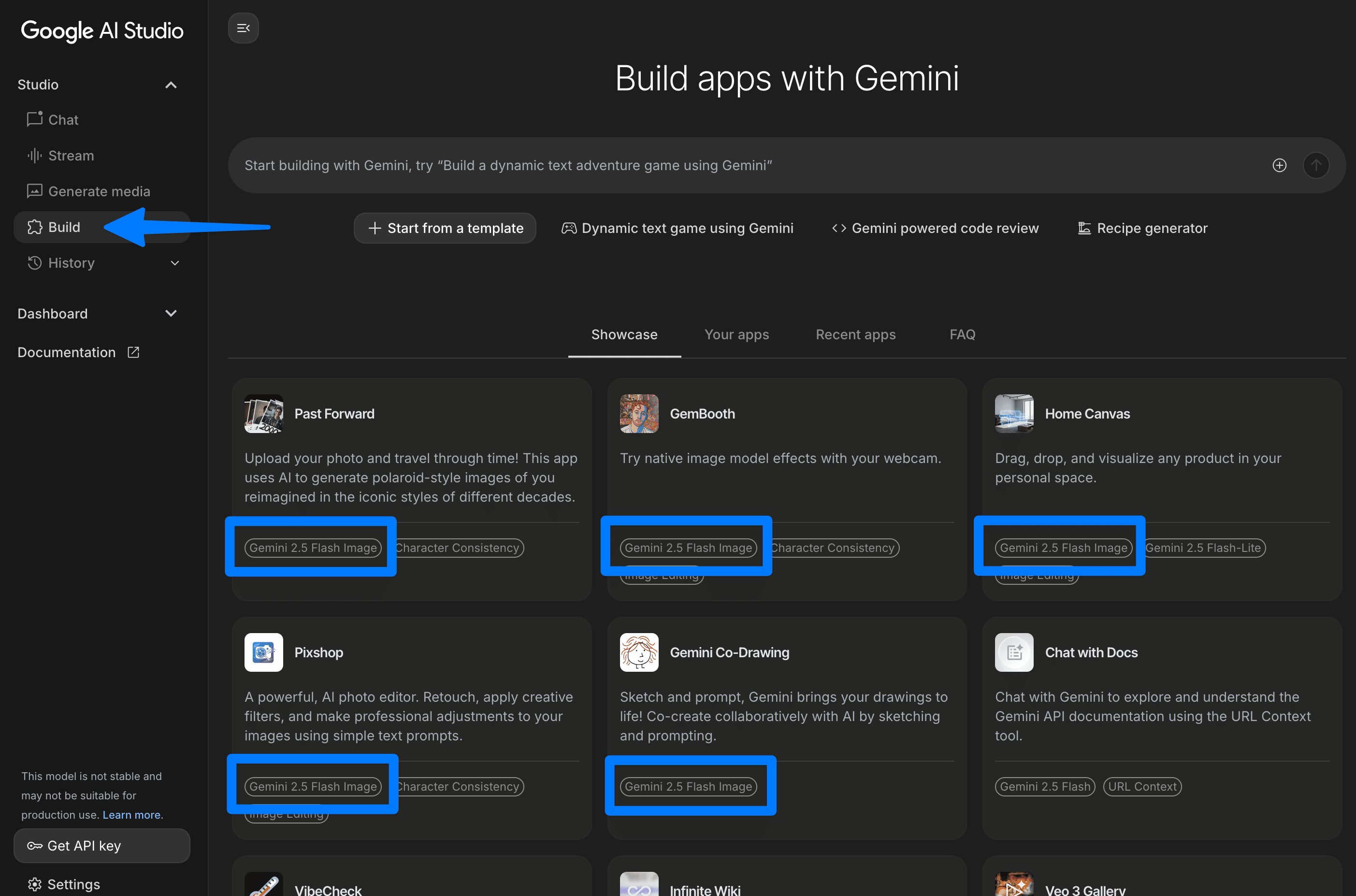
②Buildモードでの利用:
左サイドバーの「Build」メニューから、公式ブログでも紹介されている「Past Forward」や「Home Canvas」といったテンプレートアプリを選択し、各機能を試したり、カスタマイズしたりできます。
APIでの利用:
APIを利用する場合、以下のPythonのサンプルコードのように genai.Client() を通じて、gemini-2.5-flash-image-previewモデルを呼び出すことで利用可能です。
from google import genai
from PIL import Image
from io import BytesIO
client = genai.Client()
prompt = "Create a picture of my cat eating a nano-banana in a fancy restaurant under the gemini constellation"
image = Image.open('/path/to/image.png')
response = client.models.generate_content(
model="gemini-2.5-flash-image-preview",
contents=[prompt, image],
)
for part in response.candidates[0].content.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = Image.open(BytesIO(part.inline_data.data))
image.save("generated_image.png")既知の限界と今後の改善点
Googleは、Gemini 2.5 Flash Imageにもいくつかの改善点があるとしており、今後のモデルアップデートを通じて対処していく方針です。
主な課題:
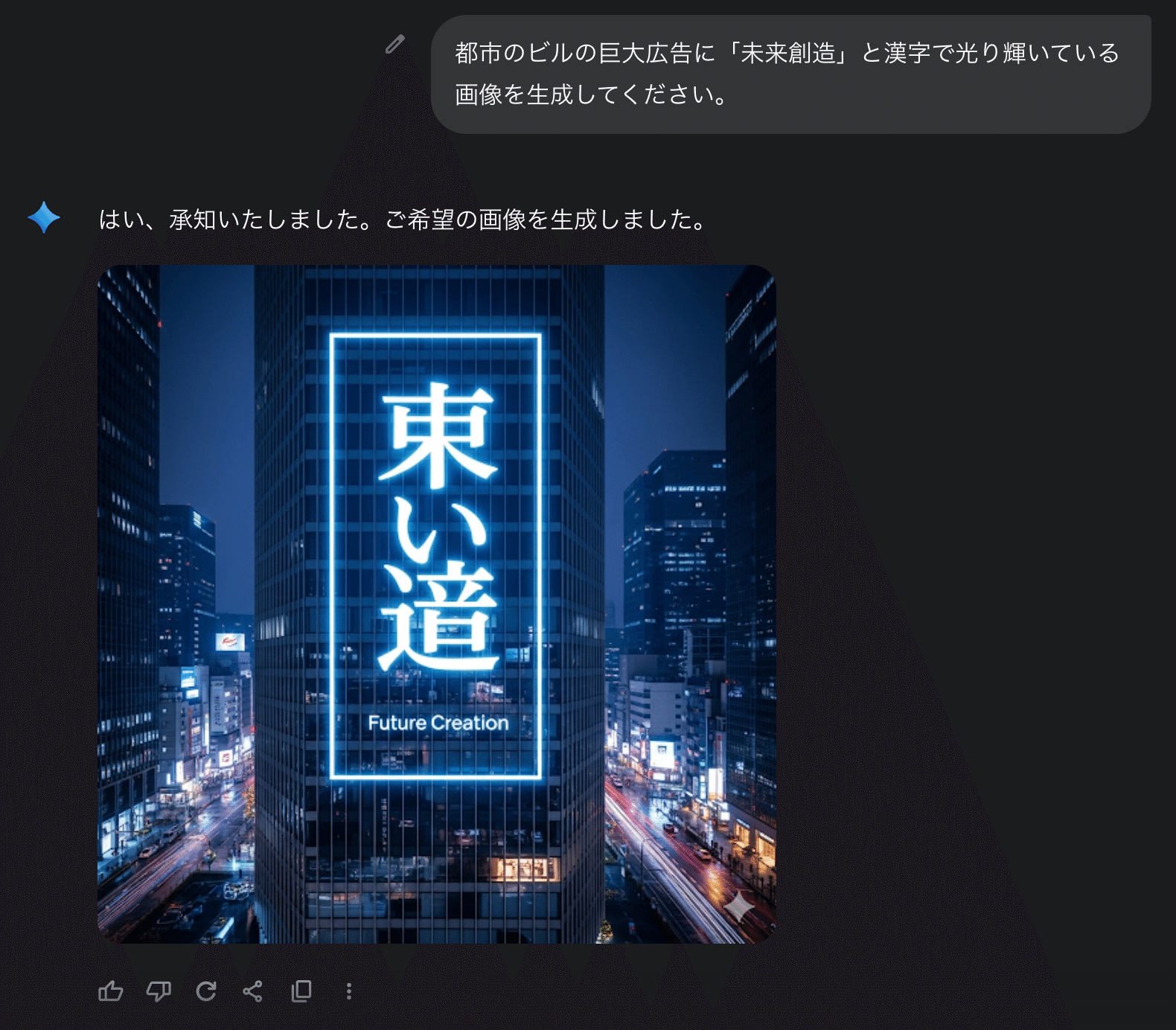
長文テキストのレンダリング精度: 画像内に長い文章を正確に描画する能力。
キャラクター一貫性の信頼性: 複数画像にわたるキャラクターの一貫性を、さらに安定させること。
細部の事実表現: 画像内の微細なディテールを、事実に基づいて正確に表現すること。
特にテキストレンダリング、中でも日本語の描画精度は、画像生成モデル共通の課題です。現状、この領域ではOpenAIのGPT-4oなどが比較的得意とする場面も見られ、今後の改善が期待されるポイントです。
安全性への取り組み
今回のアップデートでは、出所の透明性に関する取り組みも発表されています。
生成・編集されたすべての画像には、目に見えない電子透かし「SynthID」が自動的に付与されます。これにより、コンテンツがAIによって生成・編集されたものであることを識別可能にし、透明性を確保するとしています。
まとめ
今回のGemini 2.5 Flash Imageのリリースは、特に画像編集の領域において、これまでの生成モデルとは一線を画す大きな進化を感じさせるアップデートです。公開されているベンチマークスコアからも、その性能の高さが示されています。
加えて、1画像あたり$0.039という価格設定は、品質によって変動するOpenAIのGPT Image 1(目安: 約$0.04〜$0.17/枚)と比較しても競争力が高く、画像活用のコストパフォーマンスを大きく引き上げています。
自然言語でここまで精密な編集が可能になると、クリエイティブ制作からビジネスユースまで、応用の幅が一気に広がりそうです。その実用性の高さから、研究所でも引き続き、詳細な検証記事をお届けする予定です。
参考
https://developers.googleblog.com/en/introducing-gemini-2-5-flash-image/





