

2025年4月17日(日本時間)、OpenAIは新たなモデル「OpenAI o3」および「OpenAI o4-mini」を発表しました。これらは、応答前により長く思考するように訓練された「oシリーズ」の最新版であり、同社史上最も賢く、高機能なモデルと位置づけられています。
最大の特徴は、応答前に長い内部的な思考連鎖(Chain of Thought)を実行する「Reasoningモデル」である点です。これにより、複雑な問題解決能力が飛躍的に向上しました。
さらに、今回初めて、これらのモデルがChatGPT内の全てのツール(Web検索、Pythonコード実行、ファイル分析、画像生成など)を自律的に連携させ、よりエージェント的なタスク実行が可能になったとまとめられています。
また、画像や図表などを深く理解し、内部プロセスで画像を操作しながら思考する「Thinking with images」機能も搭載。
これにより、マルチモーダル性能も大幅に向上し、各種ベンチマークで新たな最高水準(SOTA)を達成しています。特にコーディング、数学、科学、視覚認識の分野で顕著な性能を示しており、AIの能力を新たな次元へと引き上げました。
同時に、開発者向けにAPIや、ターミナル上で動作するオープンソースのコーディングエージェント「Codex CLI」も発表されています。
OpenAIの新モデル「o3」「o4-mini」登場
今回発表されたモデルは以下の2種類です。
OpenAI o3: OpenAI史上最も強力なReasoningモデルとされ、コーディング、数学、科学、視覚認識など、フロンティアを押し広げる性能を持つと説明されています。
複雑なクエリや多面的な分析、即座に答えが出ないような問題に適しており、特に画像、チャート、グラフィックの分析など視覚タスクに強いとのことです。外部専門家による評価では、困難な実世界タスクにおいて、前モデルo1と比較して重大なエラーが20%削減されたと報告されています。OpenAI o4-mini: 高速かつコスト効率に最適化された小型のReasoningモデルです。サイズとコストに対して驚異的なパフォーマンスを発揮するとされ、特に数学、コーディング、視覚タスクで優れているとのこと。
AIME 2024および2025といった数学ベンチマークで最高の性能を記録したと報告されています。o3よりも大幅に高い利用制限が設けられており、推論が有効な質問に対して、大量・高スループットな利用に適していると位置づけられています。

両モデルともに、前モデル(o1, o3-mini)と比較して指示追従性が向上し、より有用で検証可能な応答を提供するようになったと評価されています。また、記憶(Memory)や過去の会話を参照することで、より自然でパーソナライズされた会話が可能になったとのことです。
主な特徴
思考するモデル(Reasoning Models)
o3およびo4-miniの核心は、ユーザーに応答を返す前に、内部で長い「思考の連鎖(Chain of Thought)」を実行する点にあります。この内部プロセスでは「Reasoning Tokens」と呼ばれる、最終的な出力には現れないトークンが消費されます。
これにより、複雑な問題に対して段階的に推論を進め、より深く、精度の高い回答を導き出すことを目指しています。
OpenAIは、このReasoningプロセスに大規模な強化学習(RL)を適用することで、GPTシリーズの事前学習で見られた「より多くの計算量=より良い性能」というスケーリング則が、RLにおいても有効であることを確認したとしています。
つまり、モデルに思考時間(=内部的な計算リソース)を与えるほど、性能が向上し続ける傾向が見られたということです。
API経由でこれらのモデルを利用する場合、このReasoning Tokensの存在はコストやコンテキストウィンドウの管理に影響を与えます。Reasoning TokensはAPI応答には直接含まれませんが、出力トークンとして課金され、コンテキスト長も消費します。
開発者は、APIリクエスト時に reasoning.effort パラメータ(low, medium, high)を指定することで、思考の深さ(≒Reasoning Tokensの消費量と応答精度・速度のトレードオフ)をある程度制御できるようです。
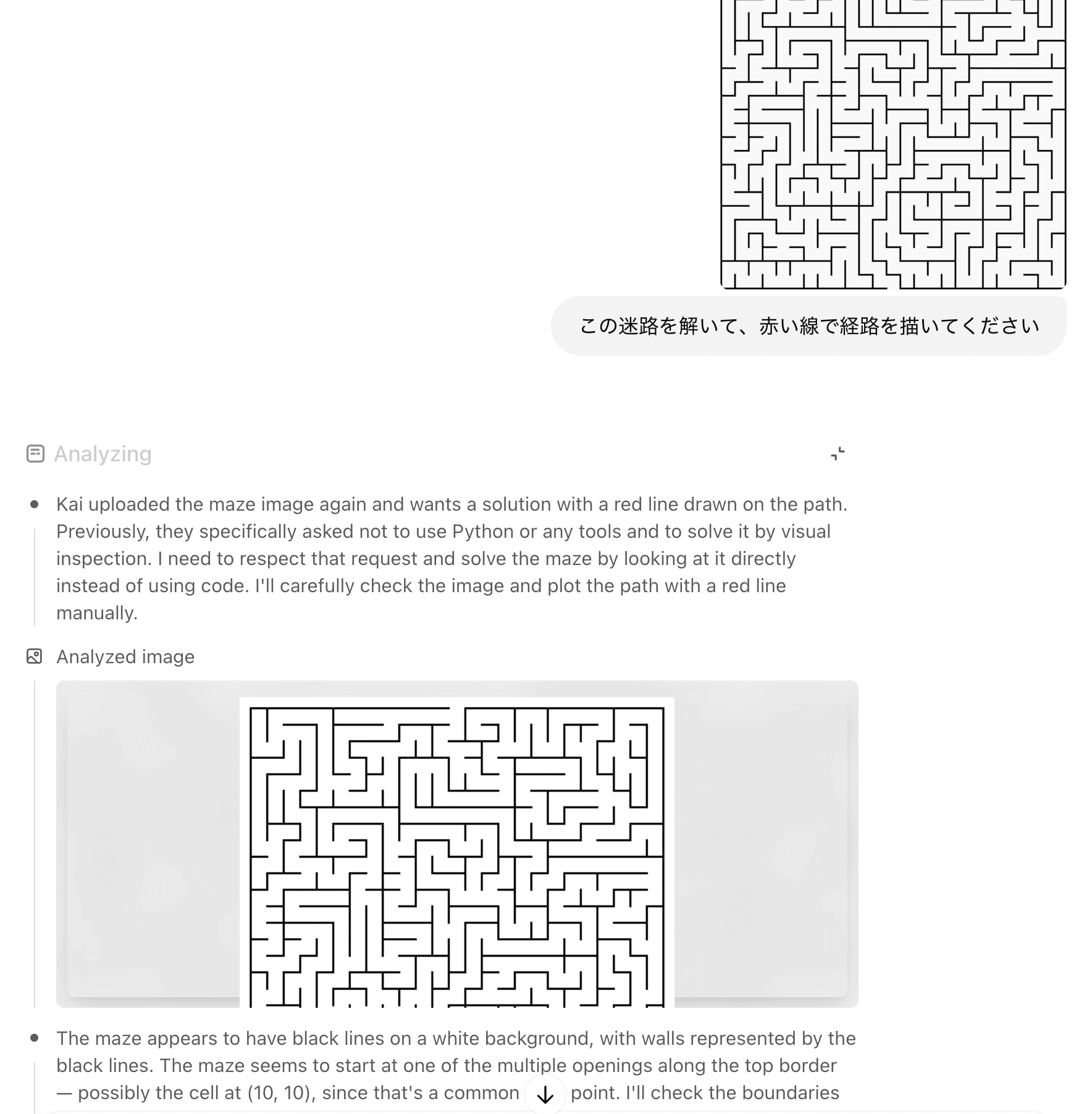
画像と共に思考する(Thinking with images)
o3とo4-miniは、単に画像を「見る」だけでなく、その画像を思考プロセスに直接統合する能力を獲得しました。ユーザーがアップロードしたホワイトボードの写真、教科書の図、手書きのスケッチなどを解釈するだけでなく、さらに内部的にツールを使って画像を操作(回転、ズーム、切り抜き、変換など)しながら推論を進めることが可能になったとしています。
これにより、視覚情報と言語情報をシームレスに融合させた、新しいクラスの問題解決が可能となり、マルチモーダルベンチマークでSOTAを達成する大きな要因となっているようです。たとえ画像が不鮮明だったり、反転していたり、低品質であっても、高度な分析が可能になったと強調されています。
紙になんて書かれてますか?
o3に提供した画像:

出力:



最終出力:

合っていますね。

エージェント的なツール連携(Agentic Tool Use)
今回初めて、o3とo4-miniはChatGPT内で利用可能な全てのツール(Web検索、Pythonによるデータ分析・ファイル操作、画像生成、ファイル検索、Memoryなど)にアクセスし、それらを自律的に組み合わせて使用する能力を獲得したと発表されました。API経由では、開発者が定義したカスタムツール(Function Calling)も同様に利用できます。
重要なのは、単にツールを呼び出せるだけでなく、与えられた問題を解決するために「いつ、どのツールを、どのように使うべきか」をモデル自身が状況に応じて判断し、戦略的に実行できる点にあるとされています。
例えば、以下の問いに対し、モデルはメモリーからユーザー情報を取得しWebで公的データを検索、Pythonコードを書いて、結果をグラフで可視化し、Canvasで説明する、といった一連のツール呼び出しを連鎖的に実行できます。
わたしについて知っていることをもとに、ニュースを読み、 わたしの興味のうち少なくとも2つに関連し、 かつおそらくわたしがまだ知らないような少しマニアックなテーマについて教えてください。 興味深い統計や関係性、データを示すグラフを1つ含めてください。 その内容をもとに、キャンバス用のブログ記事を下書きしてください(引用は使わないでください)。 グラフを挿入する位置にはプレースホルダーを入れてください。最終的に日本語でまとめてください。
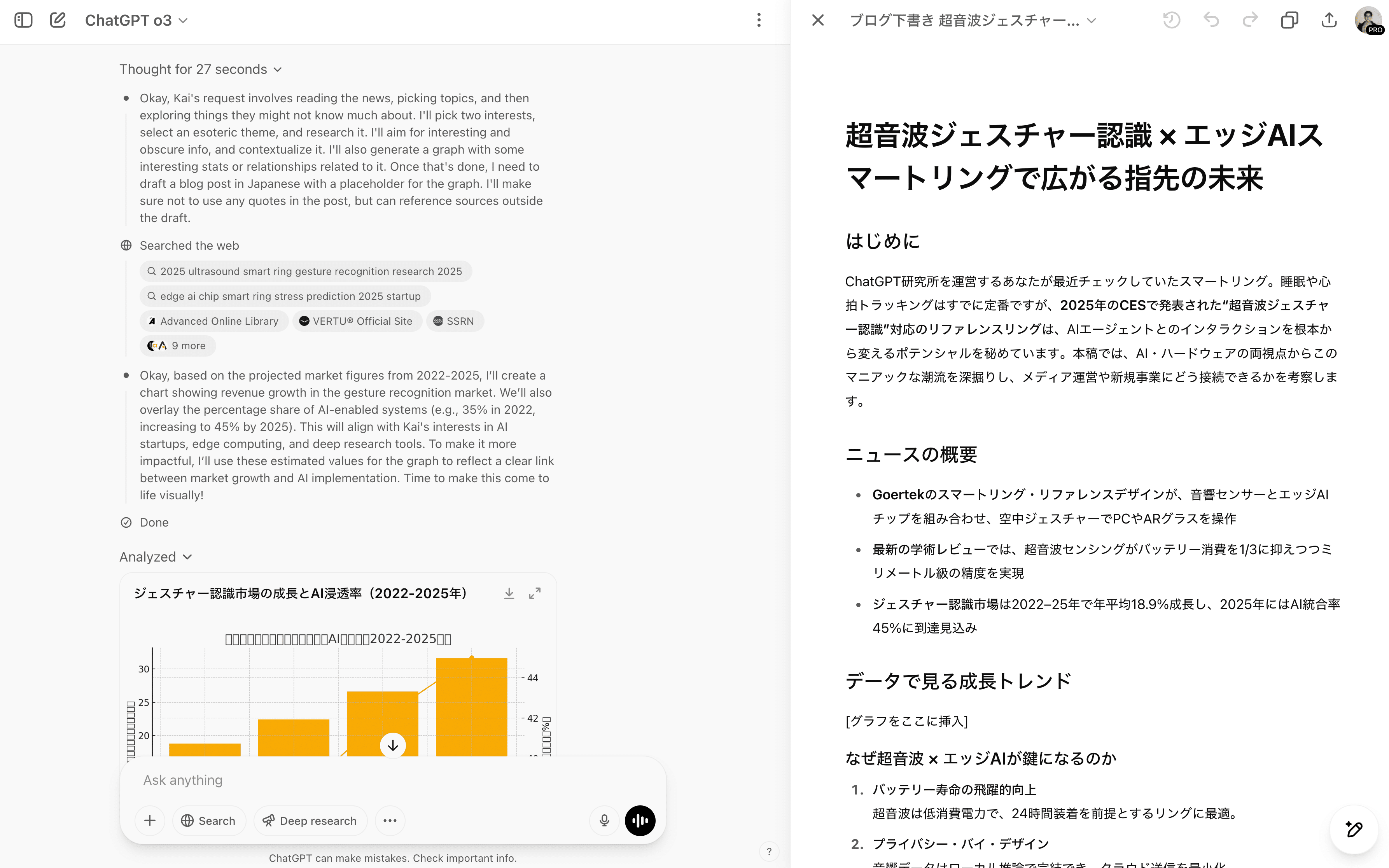

挙動を見ていると、途中で情報が不足していると判断すれば、再度Web検索を行うなど、柔軟な対応も可能そうです。これは、AIがより自律的なエージェントとして機能するための重要な一歩と言えそうです。
先ほどの会話の続きで、画像生成まで行い、それも含めたドキュメントの作成まで対応してくれました。

作成されたドキュメント:

他にも応用はいくらでもできそうです。
コスト効率の向上
o3とo4-miniは、性能向上と同時に、コスト効率の面でも改善が見られると報告されています。OpenAIが公開したコストパフォーマンス比較のグラフによると、AIME 2025(数学)やGPQA Pass@1(科学)といったベンチマークにおいて、o3はo1よりも、o4-miniはo3-miniよりも、特定のコストに対してより高い性能を発揮する、いわゆるコストパフォーマンスのフロンティアが改善されていることが示されています。
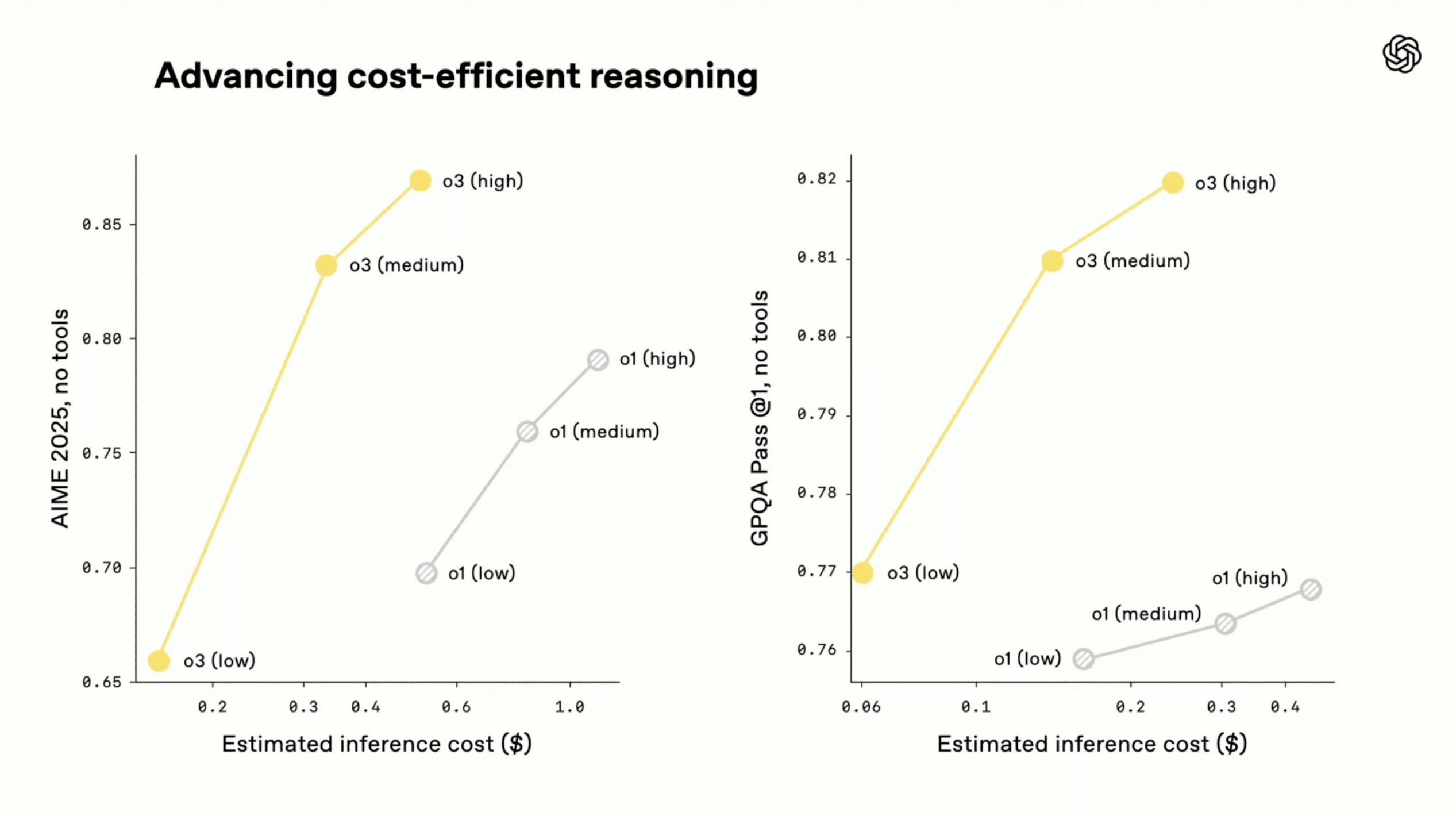
OpenAIは、多くの実世界のユースケースにおいて、o3はo1よりも、o4-miniはo3-miniよりも、結果的に「より賢く、かつ安価になる」だろうと予測しています。
性能評価(ベンチマーク結果)
OpenAIは、o3およびo4-miniの能力を示すため、多数の学術ベンチマークや実世界に近いタスクでの評価結果を公開しました。これらの評価の多くは、最高の性能を引き出すための "high reasoning effort" 設定で行われている点に注意が必要です。
学術・総合ベンチマーク
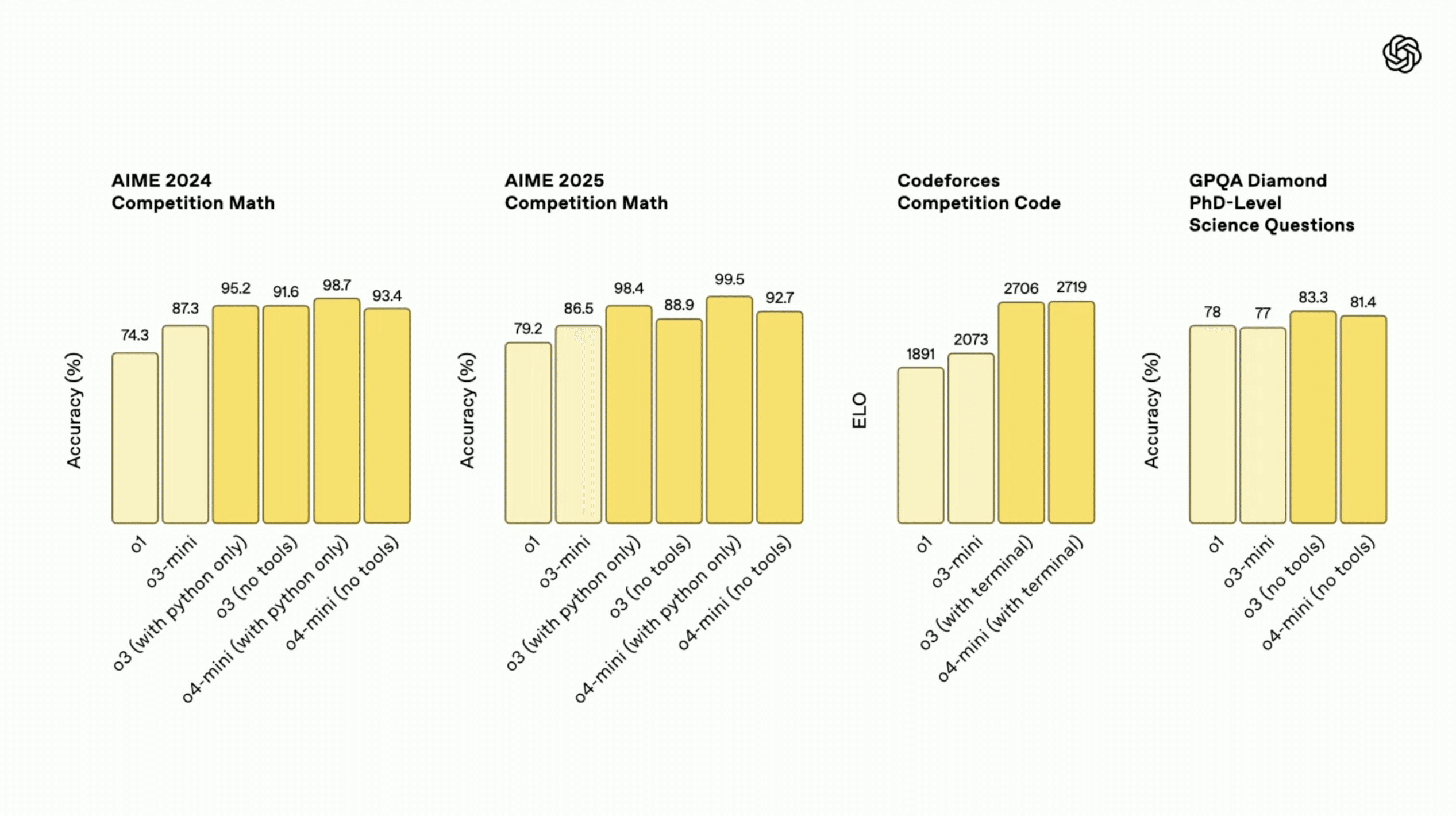
数学(AIME)、競技プログラミング(Codeforces)、科学知識(GPQA)、一般常識・推論(Humanity’s Last Exam)など、幅広い分野での評価が行われ、特に数学や科学における推論能力の高さが示唆されています。
マルチモーダル性能
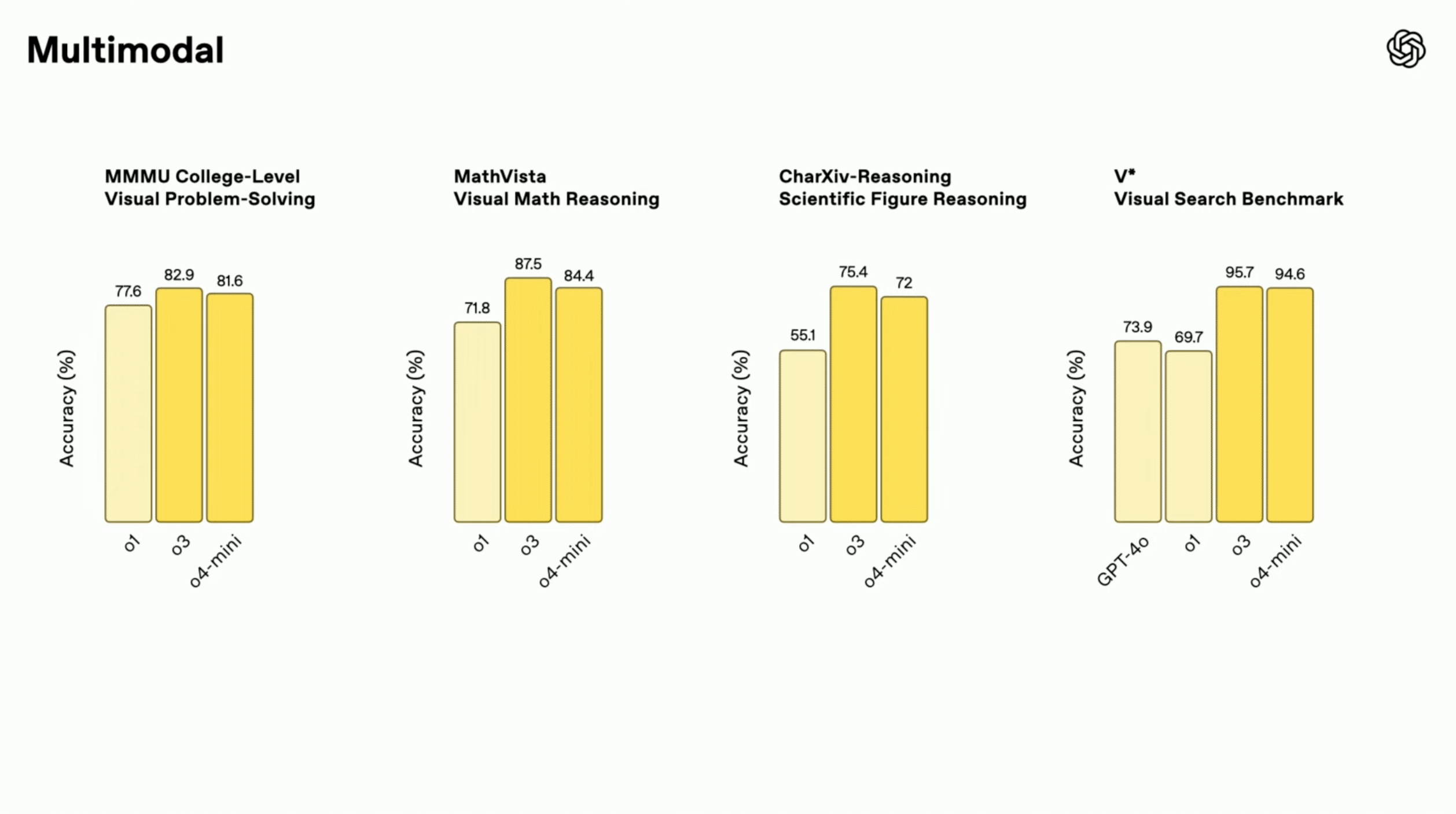
「Thinking with images」能力を反映し、大学レベルの視覚問題解決(MMMU)、視覚的な数学推論(MathVista)、科学図表の理解・推論(CharXiv-Reasoning)といったマルチモーダルベンチマークにおいて、従来モデルから大幅な性能向上が報告されています。
コーディング性能
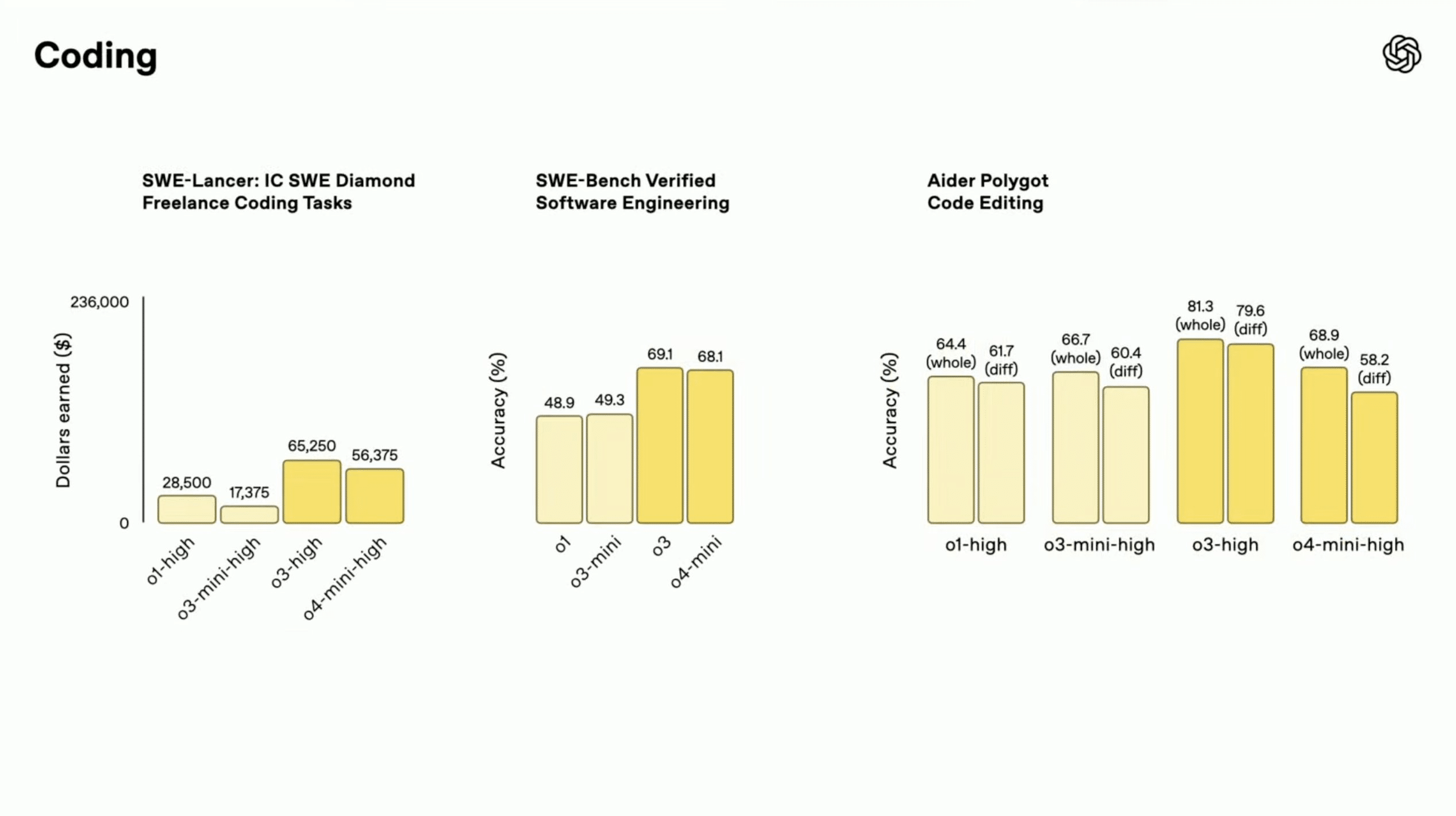
ソフトウェア開発課題(SWE-Bench Verified)やフリーランスのコーディングタスクシミュレーション(SWE-Lancer)、コード編集タスク(Aider Polyglot)など、コーディング関連のベンチマークでも高い性能を示しています。特にo3は、複雑なソフトウェアエンジニアリングタスクにおいて、既存のSOTAに匹敵するか、それを上回る結果を出しているようです。
指示追従・ツール利用性能
複数ターンにわたる複雑な指示への追従能力(Scale MultiChallenge)や、Webブラウジングを伴うタスク(BrowseComp)、APIのような関数呼び出し(Tau-bench)といった、エージェント的な能力を測るベンチマークでも評価が行われています。ツールを連携させる能力の向上が、これらのタスクにおける性能向上に寄与していると考えられます。
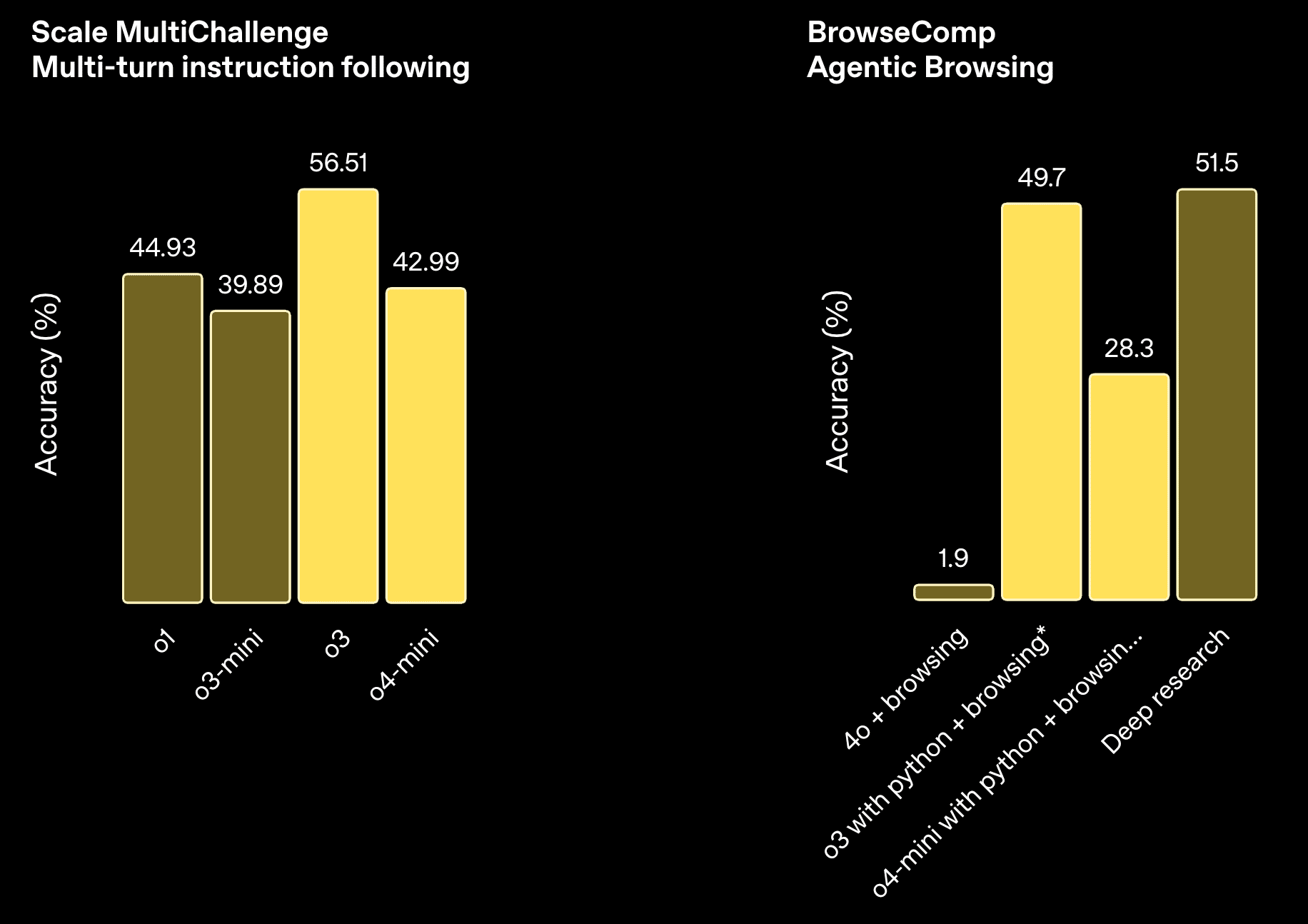
使い方・アクセス方法
新しく発表されたo3およびo4-miniモデルは、ChatGPTのインターフェースおよびAPIを通じて利用可能になります。
ChatGPTでの利用
ChatGPTのWebインターフェースおよびアプリでは、以下のプランのユーザーがo3とo4-miniを利用できます。
利用可能プラン: ChatGPT Plus, Pro, Team, Enterprise, Edu の各アカウント。
Freeユーザー: クエリ送信前に『Think』オプションを選択することで、o4-miniを限定的に試用可能とのことです。
モデル選択: ChatGPT画面上部のモデルセレクターから "o3" または "o4-mini" を選択します。
利用制限 (発表時点):
o3: Plus, Team, Enterprise で 週50メッセージ まで。
o4-mini: Plus, Team, Enterprise で 1日150メッセージ まで。
o4-mini-high: Plus, Team, Enterprise で 1日50メッセージ まで。(より高い推論設定のバリアント)
Proプラン: o3, o4-mini, 4o モデルに対し、利用規約の範囲内で ほぼ無制限 のアクセスが提供されるとのことです。ただし、自動抽出やアカウント共有、再販などは禁止されています。
今後の予定: o3-pro が、ツール連携を完全にサポートした形で 数週間以内にリリース される予定です。それまでの間、Proプランユーザーは既存の o1-pro を引き続き利用できるようです。
利用制限に達した場合、モデルセレクターから該当モデルが選択できなくなります。制限のリセットタイミングは、モデル名にカーソルを合わせることで確認できます。
API利用料金
今回発表されたo3およびo4-miniモデルのAPI利用料金も公開されています。
特に注意したいのは、これらのReasoningモデルでは、内部的な思考に使われる「Reasoning Tokens」が出力トークンとしてカウントされ、課金対象となる点です。
発表時点での料金は以下の通りです。

OpenAI o3 (o3-2025-04-16):
入力 (Input): $10.00 / 1M tokens
出力 (Output): $40.00 / 1M tokens (Reasoning Tokens含む)
キャッシュ入力 (Cached Input): $2.50 / 1M tokens
OpenAI o4-mini (o4-mini-2025-04-16):
入力 (Input): $1.10 / 1M tokens
出力 (Output): $4.40 / 1M tokens (Reasoning Tokens含む)
キャッシュ入力 (Cached Input): $0.275 / 1M tokens
APIの詳細はこちらのドキュメントをご参照ください。
新ツール「Codex CLI」
今回の発表では、開発者向けに新しい実験的なツール「Codex CLI」も公開されました。
ターミナル(コマンドラインインターフェース)から利用できる、軽量なコーディングエージェントです。
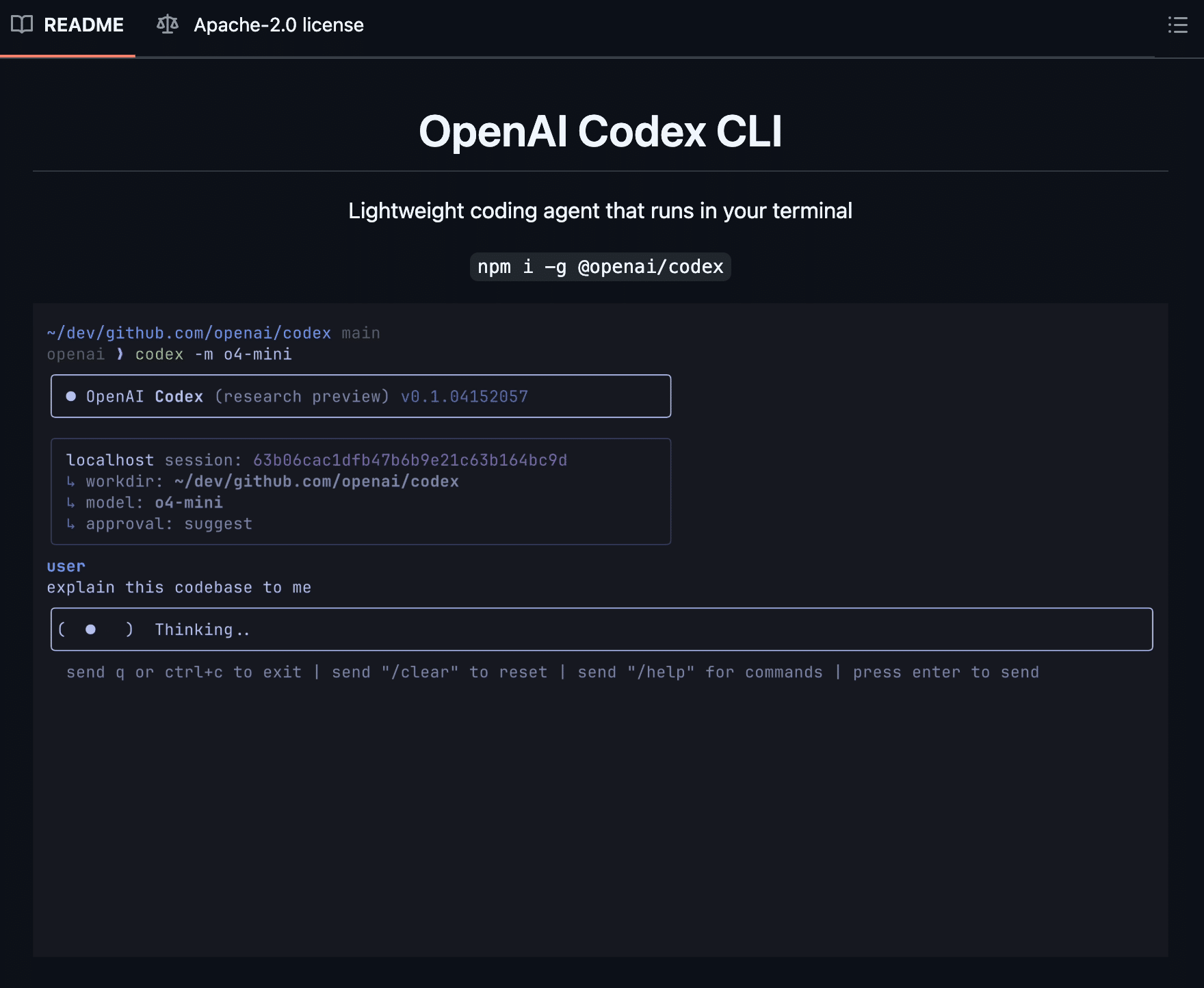
特徴:
ローカルコンピュータ上で直接動作します。
o3やo4-mini(将来的にはGPT-4.1などもサポート予定)の持つ高度な推論能力を、ターミナル環境から最大限に活用することを目指して設計されています。
コマンドラインからスクリーンショットや簡単なスケッチといったマルチモーダルな情報をモデルに渡し、ローカルのコードファイルに直接アクセスさせながら対話的にコーディング作業を進めることが可能です。
提供形態:
GitHubリポジトリでオープンソースとして公開されており、誰でも利用、改変、貢献が可能です。
助成金プログラム:
OpenAIは、Codex CLIとOpenAIモデルを活用する革新的なプロジェクトを支援するため、総額100万ドルのイニシアチブを発表しました。採択されたプロジェクトには、25,000ドル相当のAPIクレジットが付与されるとのことです。(応募フォームはこちら)
Codex CLIは、高度なAIモデルの推論能力を開発者の日常的なワークフローに、より深く統合するための新しいインターフェースとして期待されます。
まとめと今後の展望
公開されているベンチマークの数字を見る限り、今回登場した OpenAI o3 と o4-mini の能力は驚異的です。
個人的に面白いと感じたのは、画像の内容を理解するだけでなく、それを元に内部で考えを進めたり、Web検索やデータ分析といった様々なツールを状況に合わせて使いこなしたりする、そのエージェント的な振る舞いです。単に賢いだけでなく、より能動的に動けるAIの姿がより具体的になってきました。
開発者から見れば、新しいAPIやオープンソースのCodex CLIなどは注目です。どう使いこなすか、色々なアイデアが浮かんできそうです。
引き続き目が離せません。
参考情報





