

はじめに
2025年3月11日にOpenAIが発表した新しい開発ツール群の中で、特に注目を集めているのがAgents SDKです。 従来のAIシステムでは、一つの大規模言語モデル(LLM)がすべてのタスクを処理することが一般的でした。しかし、複雑な問題に直面したとき、人間社会が専門家のチームを編成するように、AIシステムも複数のエージェントに分割して協力させることで、より効果的な問題解決が可能になります。
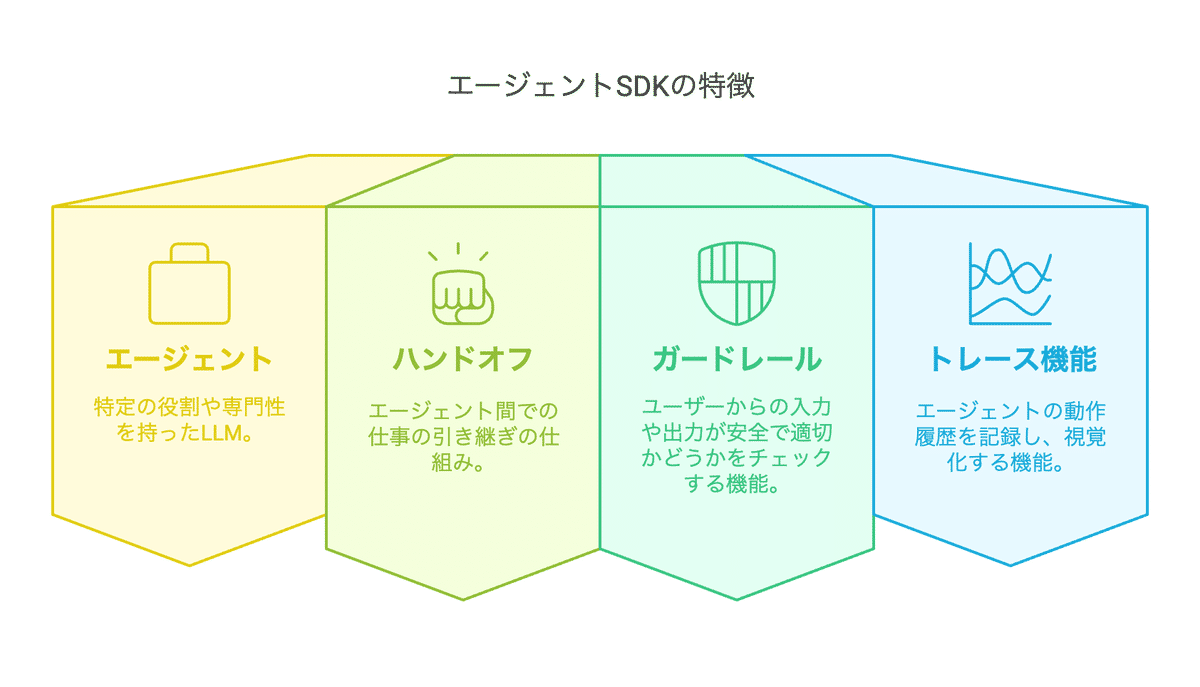
OpenAIの発表によると、Agents SDKには以下のような特徴があります:
エージェント:特定の役割や専門性を持ったLLM。
ハンドオフ:エージェント間での仕事の引き継ぎの仕組み。
ガードレール:ユーザーからの入力や出力が安全で適切かどうかをチェックする機能。悪意のある指示や不適切な内容を検出し、システムを保護します。
トレース機能:エージェントの動作履歴を記録し、視覚化する機能。
本ドキュメントでは、単一エージェントと複数エージェントのアプローチを比較し、どのような状況でマルチエージェントが真の価値を発揮するのかを探り、その上で、OpenAI Agents SDKの基本的な利用方法を紹介していきます。
シングルエージェントvsマルチエージェント:AIシステム設計の選択
昨今では、gpt-4.5やclaude 3.7-sonnetなどの大規模言語モデルの性能が著しく向上し、単一のモデルでも多くの複雑なタスクをこなせるようになりました。
「モデル自体の性能が十分に高ければ、シングルエージェントでも問題ないのでは?」と考える方も多いでしょう。確かに、多くのユースケースではシングルエージェントで十分な場合もあります。
ここでは、どのような場合にマルチエージェントが適しているのか、その具体的なシナリオと利点を解説します。
マルチエージェントの実際の価値
現代の高性能言語モデルは単体でも多くのタスクを処理できますが、複数のエージェントに分割することで以下のような本質的な価値が生まれます:
1. 複雑な問題の分割統治
大規模で複雑な問題においては、異なる側面を専門エージェントに担当させることで、より効率的な問題解決が可能になります。これはシステム設計の「単一責任の原則」に沿ったアプローチで、各エージェントが特定の領域に集中することで全体としての処理能力が向上します。
2. 透明性とデバッグのしやすさ
マルチエージェントアプローチの重要な利点は、システムの透明性とデバッグのしやすさです。各エージェントが明確な役割と責任を持つことで、問題発生時の原因特定が容易になります。
関心の分離: 各エージェントは特定の機能や領域に集中するため、問題が発生した場合に影響範囲が限定されます。
エラーの局所化: 複雑なタスクの実行中に問題が発生した場合、どのエージェントの判断に問題があったのかを特定しやすくなります。
監査可能性の向上: 各エージェントの判断と行動を個別に記録・分析できるため、システム全体の動作を監査しやすくなります。
なお、Agents SDKのトレース機能により各エージェントの動きが格段に把握しやすくなりました。
3. 作業記憶とコンテキスト管理
マルチエージェントアプローチの最も重要なシステム的利点は、作業記憶とコンテキスト管理の効率化です。これはLLMシステムの根本的な制約を克服するための効果的な戦略となります。
コンテキストウィンドウの効率的な使用: LLMには入力として処理できるトークン数に制限があります。マルチエージェントでは各エージェントが関連する情報だけを保持できるため、単一エージェントではトークン制限に達してしまうような大量の情報でも効率的に処理できます。
並列処理と情報の選択的共有: 複数のエージェントが同時に異なる側面を処理し、必要な情報だけを選択的に共有することで、全体的な処理効率が向上します。例えば、データ分析エージェントは生データの詳細ではなく、分析結果の要約だけをレポート生成エージェントに渡すことができます。
このように、マルチエージェントアプローチは単なる機能の分散ではなく、LLMシステムの根本的な制約を克服するための効果的な戦略となります。特に大規模で複雑なタスクを処理する場合、これらの利点は顕著になります。
マルチエージェントの落とし穴
マルチエージェントアプローチには多くの利点がありますが、実装する際に注意すべき重要な落とし穴もあります。特に同モデル(例えばgpt-4oなど)を使用する場合、単に異なる指示を与えるだけでは、期待するほどの効果が得られない可能性が高いです。
「あなたは特許法の専門家です」
「あなたは契約法の専門家です」
「あなたは雇用法の専門家です」
このようにプロンプトを変えるだけでは、以下のような問題が生じます。
知識の分断は表面的: 基本的な知識ベースは同一のままであるため、真の専門性の違いは生まれません
「専門家の演技」に過ぎない: モデルは指示に従って振る舞いを変えるだけで、実際の専門知識が増えるわけではありません
同一の限界を共有: すべてのエージェントは同じ訓練データに基づいているため、一つのエージェントが答えられない質問は他のエージェントも答えられない可能性が高いです
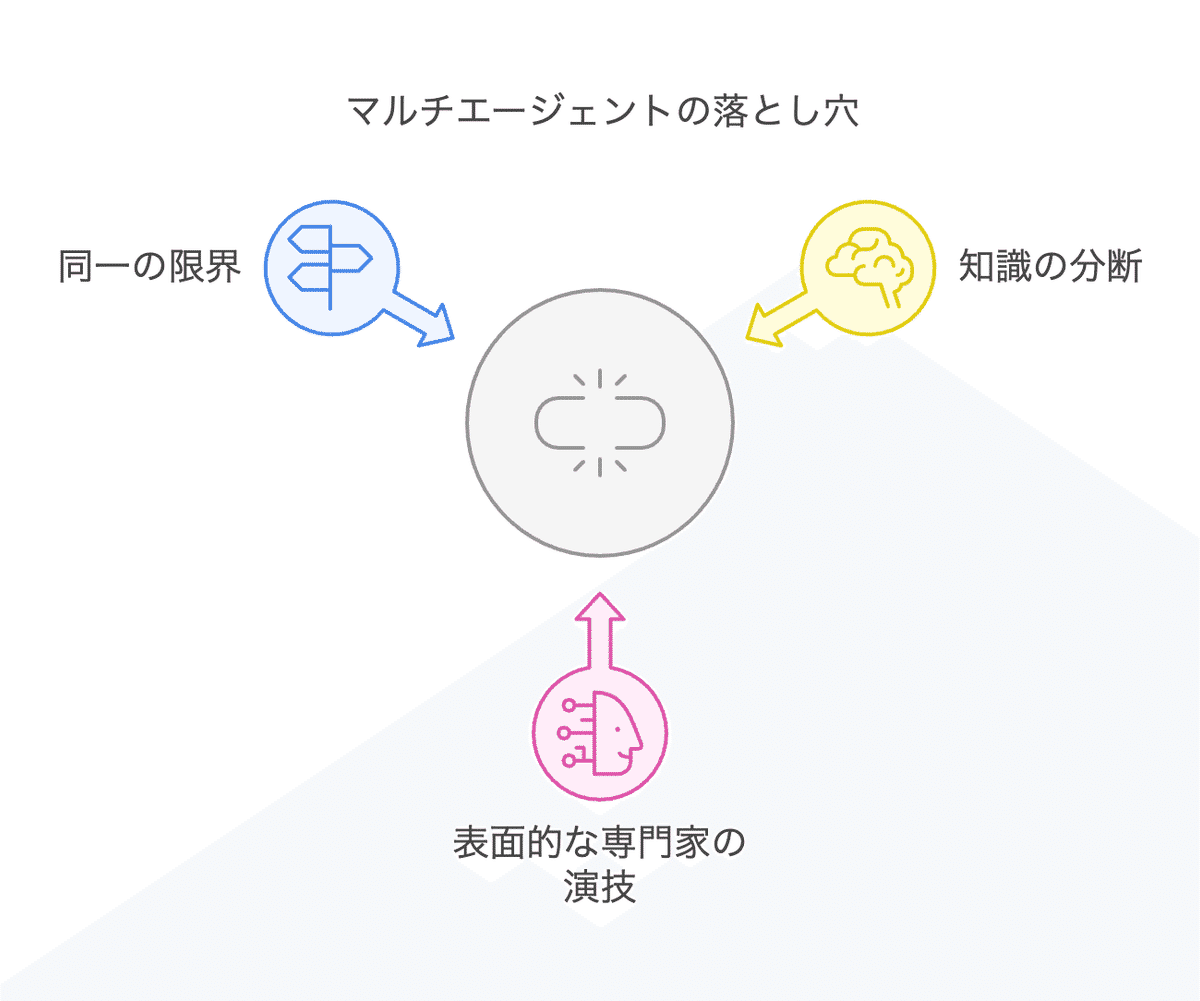
マルチエージェントアプローチを効果的に実装するには、これらの落とし穴を認識し、次のセクションで説明するような対策を講じる必要があります。
マルチエージェントアプローチを価値あるものにするには
マルチエージェントの真価を発揮するためには、単なる指示の違いを超えた工夫が必要です:
1. 特化したツールや知識ベースの統合
各エージェントに異なるツールや知識源へのアクセス権を与えることで、真の専門性の違いを作り出せます。
実例:法律アドバイスシステムの強化
特許法エージェント:
特許データベース(例:Google Patents API)へのアクセス権を付与
特許検索と比較分析が可能
契約法エージェント:
契約テンプレートライブラリへのアクセス権を付与
過去の判例データベースへのアクセス権を付与
雇用法エージェント:
労働法規制のデータベースへのアクセス権を付与
最新の雇用関連判例へのアクセス権を付与
効果:
同じ基盤モデルでも、アクセスできる情報源が異なるため実質的に異なる専門知識を持つ
例:「特許侵害の可能性について調査したい」という質問に対し、特許法エージェントは特許データベースを検索して類似特許を見つけ出し、具体的な比較分析を提供可能
時間の経過とともに、各専門エージェントは人間の専門家からのフィードバックを蓄積し、分野特有の微妙な判断が可能になる
実装の流れ
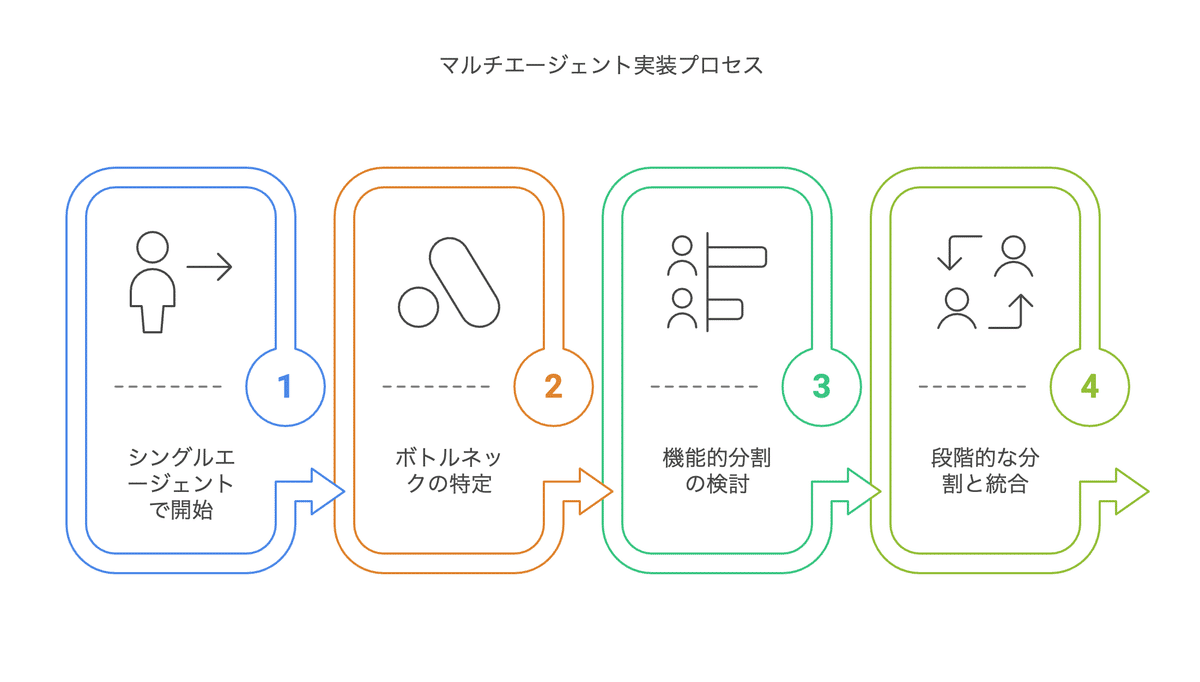
実際の開発では、以下のように構築すると良いでしょう:
まずはシングルエージェントで開始: シンプルなアプローチから始め、要件をより深く理解します
↓
ボトルネックの特定: 単一エージェントでの限界や課題を特定します
↓
機能的分割の検討: 明確な責任の分離ができる部分を特定します
↓
段階的な分割と統合: 徐々にエージェントを分割し、効果的な連携の仕組
↓
結論:マルチエージェントアプローチの選択
マルチエージェントアプローチは「できるから使う」のではなく、明確な価値を生み出す場合に採用すべきです。
適切に設計されたマルチエージェントシステムは複雑な問題を解決する強力なツールとなりますが、単純な問題にこのアプローチを適用することは、不必要な複雑さとコストを招く可能性があります。





