

はじめに:Cursor 2.0の新機能を3つに絞って徹底解説
2025年10月29日、ついにCursor 2.0がリリースされました。
エージェント活用に最適な開発環境としてのCursorをさらに強化する大型アップデートです。初のコーディングモデル「Composer」と、多数のエージェントを並行して扱える新しいインターフェースが追加されています。
従来のAIコーディングツールの課題
これまでのAIコーディングツール(Cursor含む)では、以下のような課題を抱えていました:
時間をかけてエラー修正を依頼しても直らないが、モデルを変更したらすんなり直った
次の依頼も投げておきたいのに、1つのタスクが終わるまで待機しなければならない
デザイン案など、複数のモデルに競わせて比較したいが、1つずつしか試せない
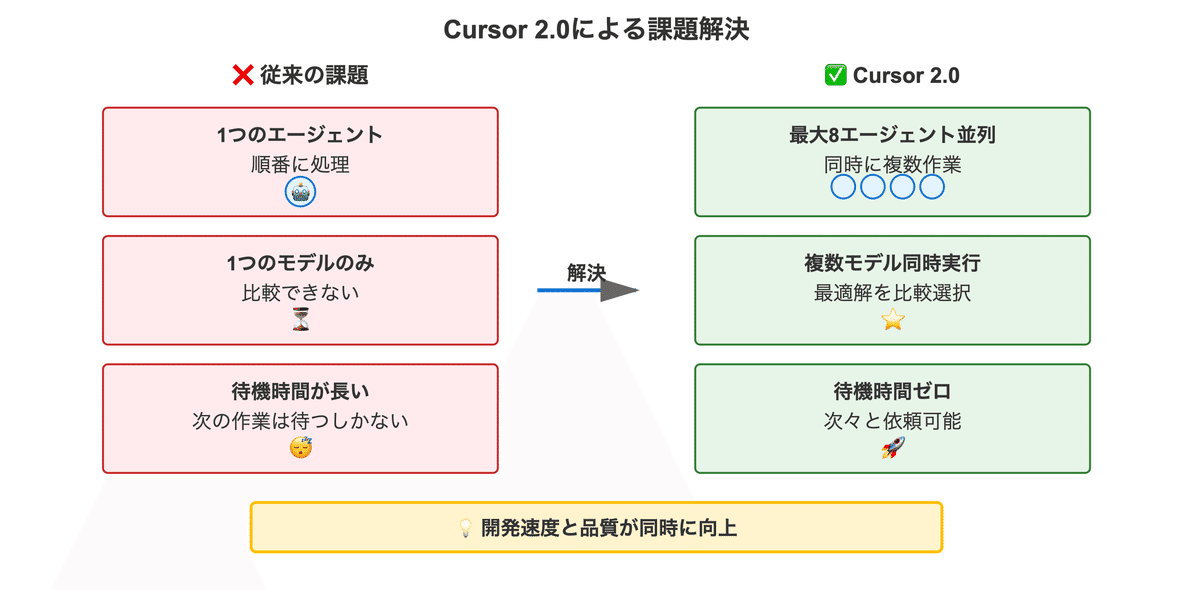
Cursor 2.0によって、こうした多くの課題が解決できるようになりました。
最大8つのエージェントが同時に作業し、複数の解決策を比較できるようになったためです。
この記事で解説する3つの機能
Cursor 2.0の変更点は多岐に渡りますが、今回は以下の3つの機能に絞って解説します:
(1) 新モデルComposer - 30秒未満で完了する4倍速モデル
(2) 並列エージェント(Multi-Agents) - 同じタスクを8つ同時実行して最良を選ぶ
(3) ブラウザツール(Browser) - AIが自分でテストして修正を繰り返す
それぞれの機能がどのような場面で役立つのか、実際にどう使うのか、従来と何が違うのかを、具体的な使用例とともに徹底解説していきます。
【機能(1)】Composer:4倍速の新モデル
Composerとは?
Composerは、Cursor初の独自コーディングモデルです。なお、以前は「エージェント」機能そのものを「composer」と呼んでいました。
「composer」という語は、「複数の要素やプロセスを統合し、まとまりのある成果物を生み出す」ことを象徴しています。機能名からモデル名への継承も含め、Cursorの一貫した思想がこのネーミングから読み取れます。
同等の知能レベルのモデルと比較して4倍高速という圧倒的なスピードを実現。
Cursorにおける低レイテンシのエージェント型コーディング向けに特別に設計され、ほとんどのターンを30秒未満で完了します。
初期テスターからも、モデルと素早く反復できる点が高く評価されており、複数ステップのコーディングタスクでも信頼性が高いと報告されています。
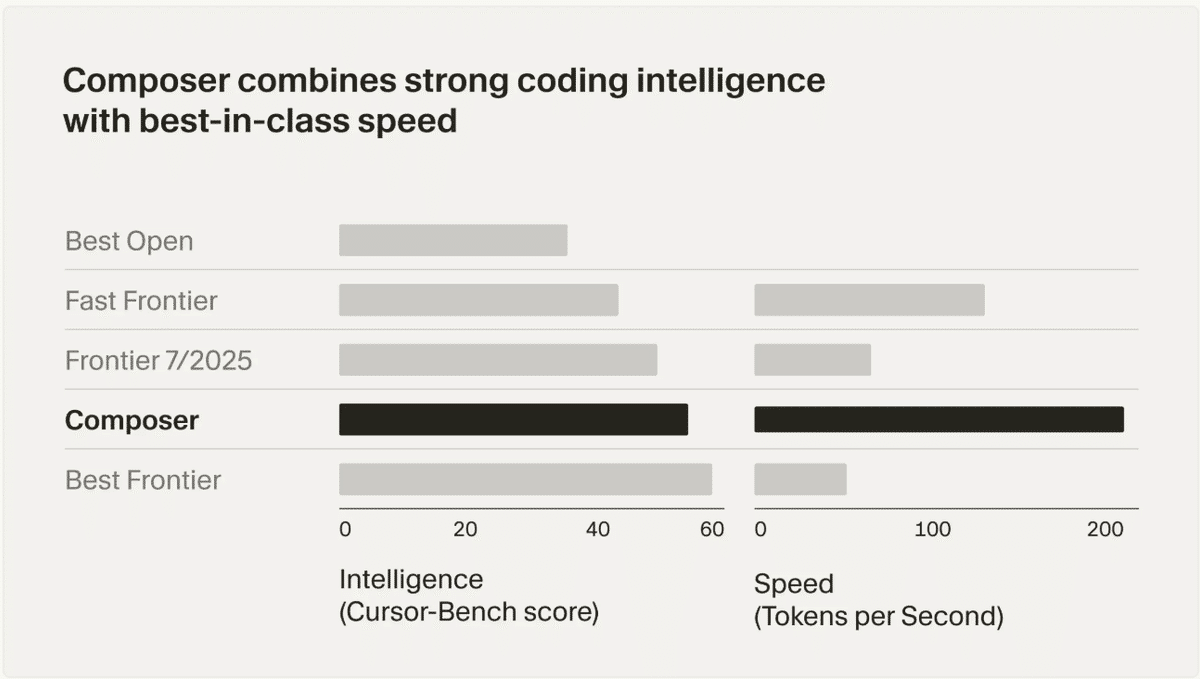
上のグラフは、Composerのベンチマーク結果を示しています。
Cursor Bench(Cursorの内部ベンチマーク)において、ComposerはSonnet 4.5やGPT-5といった現在のベストフロンティアモデルに迫る性能を維持。
その上で、速度は約4倍(200+ tokens/sec)を実現しました。
グラフからわかるように、Composerは以下のモデルと比較して優れたバランスを実現しています。
Best Frontier(Sonnet 4.5、GPT-5):性能はComposerをわずかに上回るが、速度は約50 tokens/secと大幅に遅い
Fast Frontier(Haiku 4.5、Gemini Flash 2.5など):速度は速いが、性能はComposerに及ばない
Best Open(Qwen Coder、GLM 4.6など):オープンソースモデルの中では最良だが、性能・速度ともにComposerに劣る
技術的特徴
Composerの主な技術的特徴は以下の通りです:
セマンティック検索対応:コードベース全体にわたるセマンティック検索を含む強力なツール群で学習されており、大規模なコードベースの理解と作業が格段に得意です
エージェント型コーディング専用設計:Cursorのエージェント機能に最適化された設計
低レイテンシ:待ち時間が短く、テンポよく反復開発が可能
実際の使い方
Composerの使い方は非常にシンプルです。チャット欄のモデル選択ドロップダウンから「Composer 1」を選択するだけです。
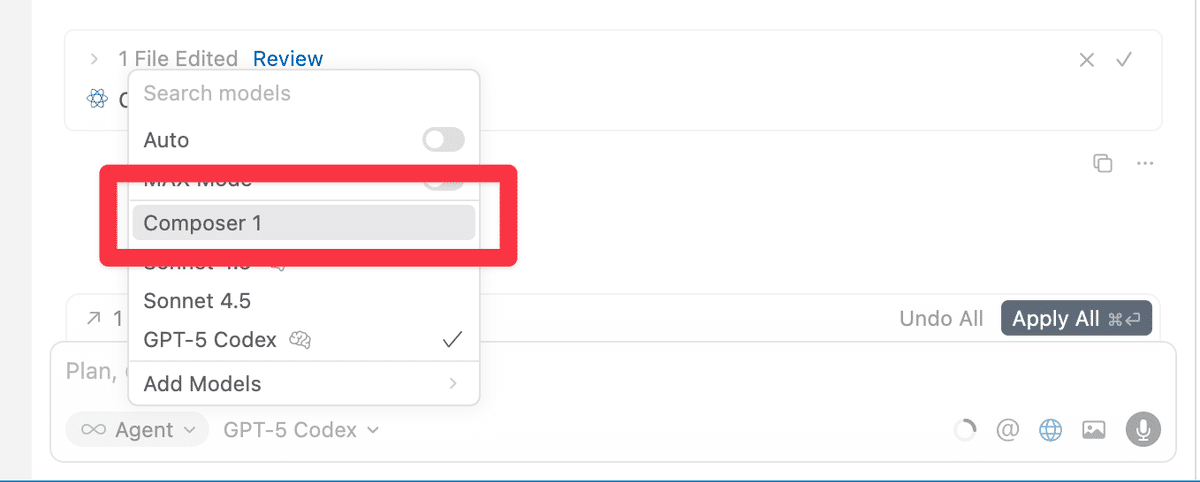
モデルを選択したら、通常通りにプロンプトを入力するだけで、Composerが高速かつ高精度でコーディング作業を支援してくれます。エージェントモードでも、通常のチャットモードでも利用可能です。
【機能(2)】並列エージェント:8つのAIが同時に働く時代
並列エージェントとは?
Cursor 2.0の並列エージェント機能は、複数のAIエージェントが同時に異なる作業を進められる仕組みです。
並列エージェントの2つの使い方
並列エージェント機能には、大きく分けて2つの活用方法があります:
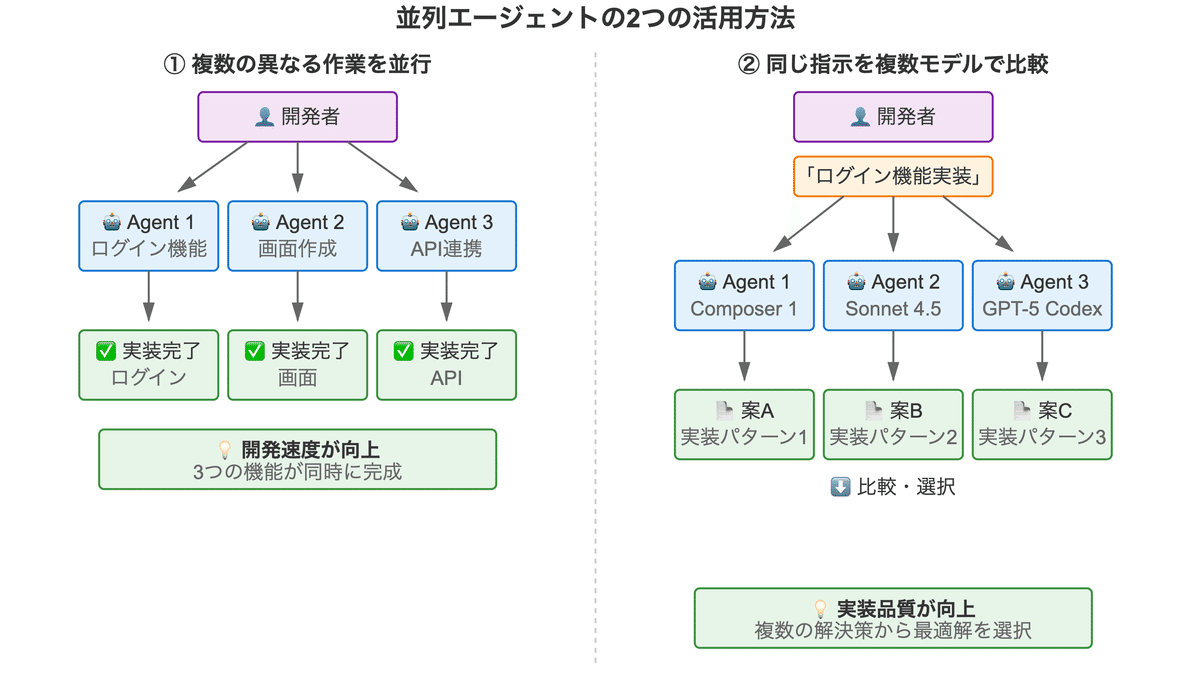
(1) 複数の異なる作業を並行して依頼する
それぞれ異なるタスクを同時に依頼し、開発速度を向上させます。各エージェントが独立したgit worktreeで作業するため、互いに干渉しません。
(2) 1つの指示を複数のモデルに同時に依頼して比較する
同じタスクを異なるAIモデルに依頼し、最も高品質な実装を採用できます。
git worktreeとは?
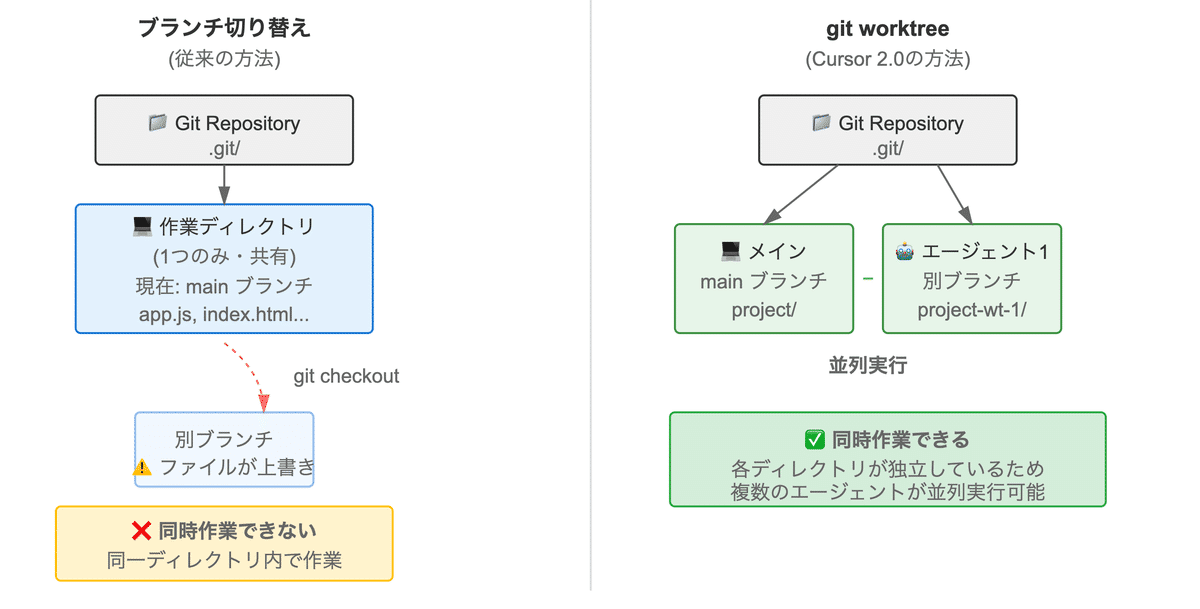
ローカル環境で並列開発を行う場合は、git worktreeという技術が使われています。 git worktreeは、一言で言うとディレクトリのコピーです。
1つのリポジトリから複数の作業ディレクトリを作成できるGitの機能です。通常のブランチ切り替えとは異なり、物理的に別々のディレクトリを用意することで、各エージェントが互いに干渉せずに作業できます。
ブランチ切り替えとの違い
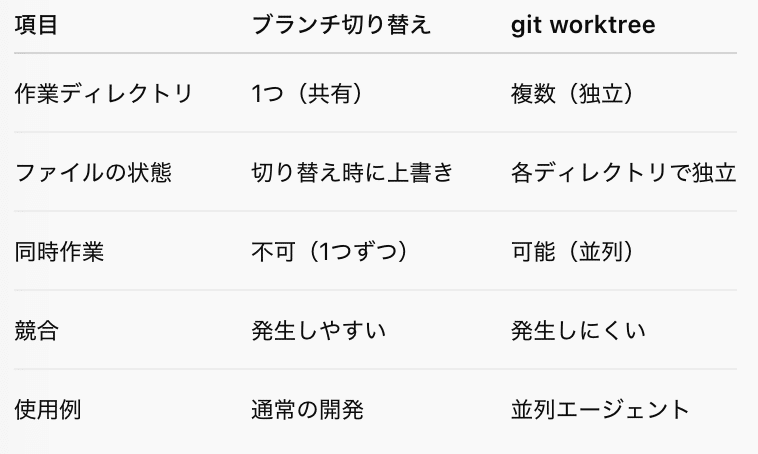
通常のブランチ切り替えでは、git checkoutで別ブランチに移動すると、同じディレクトリ内のファイルが書き換わります。そのため、複数の作業を同時に進めることはできません。
一方、git worktreeを使うと、ブランチごとに独立したディレクトリが作成されます。例えば:
project/ # メインの作業ディレクトリ(main)
project-worktree-1/ # エージェント1用(feature-a)
project-worktree-2/ # エージェント2用(feature-b)
project-worktree-3/ # エージェント3用(feature-c)
各ディレクトリは独立しているため、エージェント1がfeature-aで作業している間、エージェント2はfeature-bで、エージェント3はfeature-cで同時に作業できます。ファイルの競合を気にする必要がありません。





