

OpenAIの12日間連続の発表の最中、GoogleもGeminiモデルをアップデートしてGemini 2.0 flashなどを発表しました。
そんなGoogleの最新モデルを無料で利用できるプラットフォームとして提供されているのがGoogle AI Studioです。
そこで今回はGoogle AI Studio徹底解説として基本の使い方から、最近できるようになった機能の使い方まで網羅的に解説していきます。
Googleのアップデートの内容はこちらの記事で解説しています。
https://agi-labo.com/articles/n3ae6db505bc9
Google AI Studioとは
Google AI Studioは、Googleが提供するウェブベースのAI開発プラットフォームです。
開発者やデータサイエンティストは、Google AI Studioを通じて、GeminiをはじめとするGoogleの最新AIモデルにアクセスすることができます。
Google AI Studioは、直感的なインターフェースと豊富な機能を備えており、AI開発の経験が少ないユーザーでも容易に利用できます。
また、無料プランが用意されているため、気軽に最新のAIモデルを試すことができます。
Gemini との関係性
Google AI Studioは、Googleの最新AIモデルであるGeminiを活用するための主要なプラットフォームの一つです。
Geminiは、テキスト、コード、画像、音声、動画など、様々な種類の情報を理解し、処理することができるマルチモーダルAIモデルです。Google AI Studioを通じて、GeminiのAPIにアクセスし、その能力を最大限に引き出すことができます。
Google AI Studioでは、Geminiの最新モデルの利用が可能で、モデル選択も自由にできます。
Google AI Studioで利用可能なモデル
2024年12月25日時点で、Google AI Studioで利用可能なモデルは以下の通りです。
Geminiの中でも複数のモデルが利用可能ですが、最新モデルはGemini2.0 flashシリーズとなっています。

Gemmaは、Googleが開発した軽量で最先端のオープンソースモデルでGoogle AI studioで利用可能です。
【基礎編】Google AI Studioの使い方
ログイン
Google AI Studioには以下からログインします。
https://ai.google.dev/aistudio
「Sign in to Google AI Studio」のボタンを押して、Googleアカウントを選択することでログイン可能です。

利用規約に同意して、「続行」をクリックすることで利用できます。

通常チャットモード
「Create Prompt」をクリックすることで、通常のチャットができるモードの画面が立ち上がります。
プロンプト入力欄にテキストを入力して、「Run」を押すことで回答が生成されます。
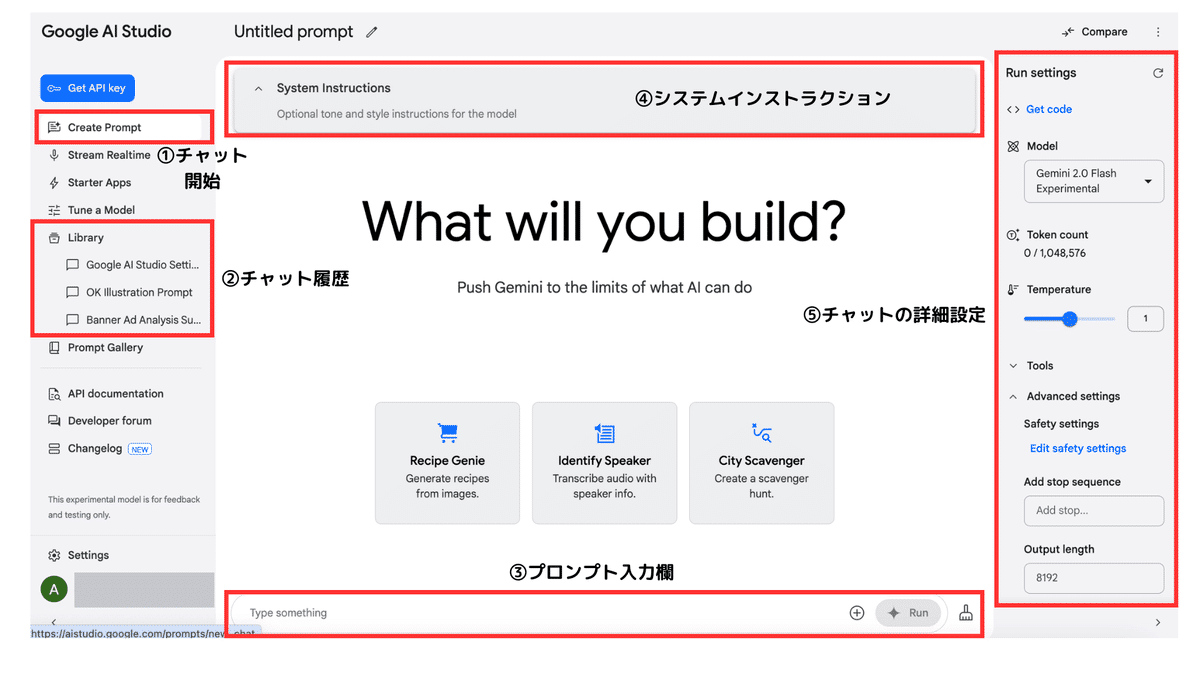
チャット上部の「System Instruction」では、チャット内で必ず守ってほしい指示を入力することが可能です。
ChatGPTのカスタムインストラクションのような形で使うことができます。
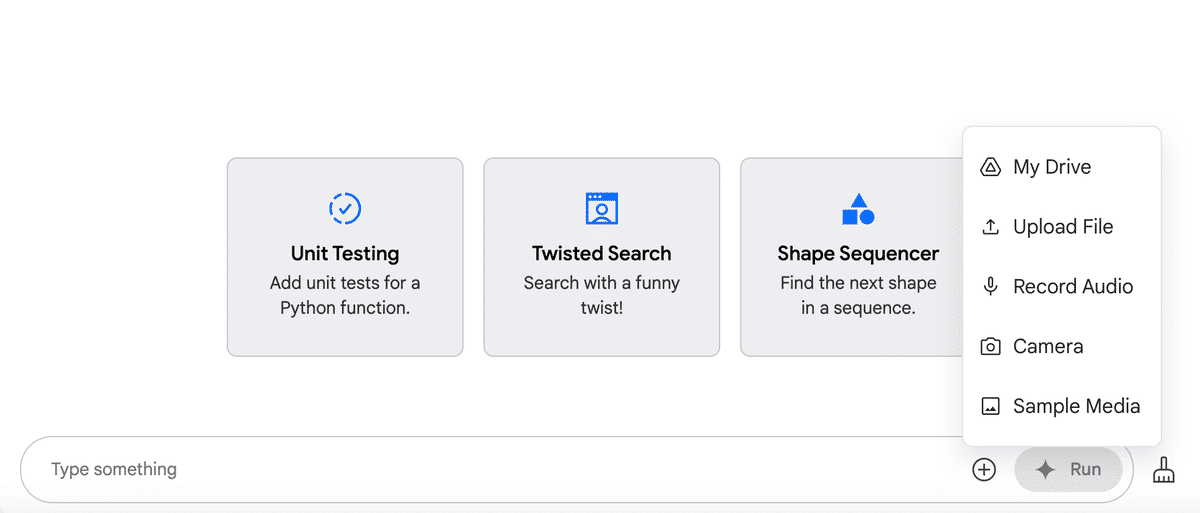
テキスト入力の右の「プラスボタン」でファイルアップロードが可能です。
Geminiはマルチモーダルモデルなので、音声、画像、動画、ファイルをアップロードが可能です。
My Driveとの連携をしておくと、ドライブ内のファイルを選択することもできます。
出力されたテキストをコピーするには、出力結果の右上の「More optins」をクリックします。
Copy text、Copy markdownでコピーすることができます。

チャットの左側の「Library」では、チャット履歴を確認することが可能です。
チャットの右側の「Run settings」では、細かいチューニング設定ができるようになっています。
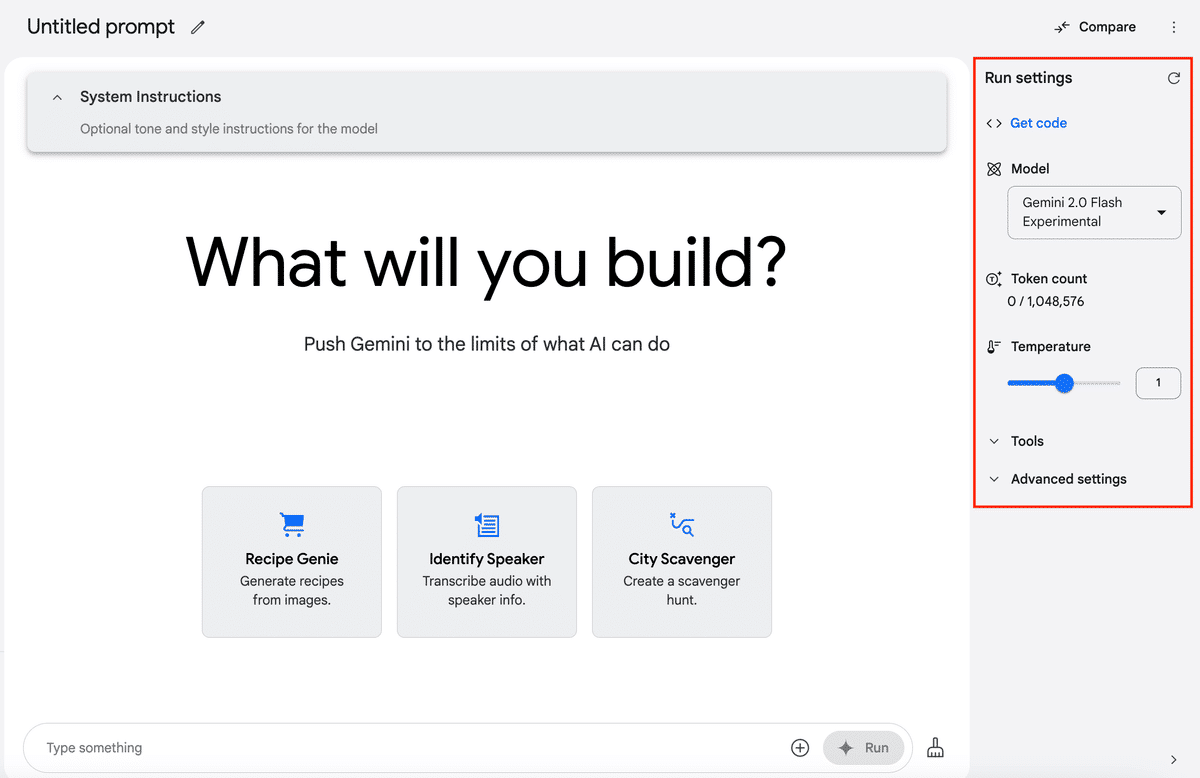
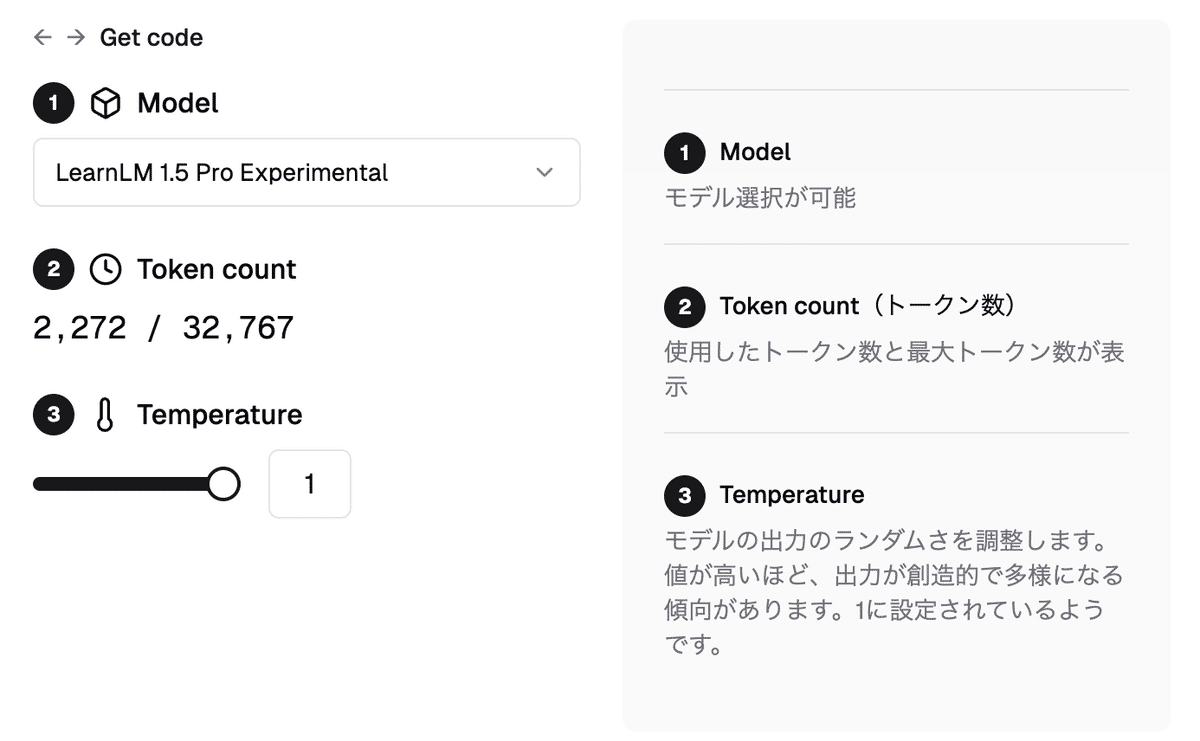
①Model、Token count、Temperatureの設定
モデルは前述したGeminiのモデルとGemmaのモデルの中からチャットごとに自由に選択できます。
②Toolsの設定
Toolsでは出力形式やコードの実行、ファンクションコーリングの設定をオンにすることができます。
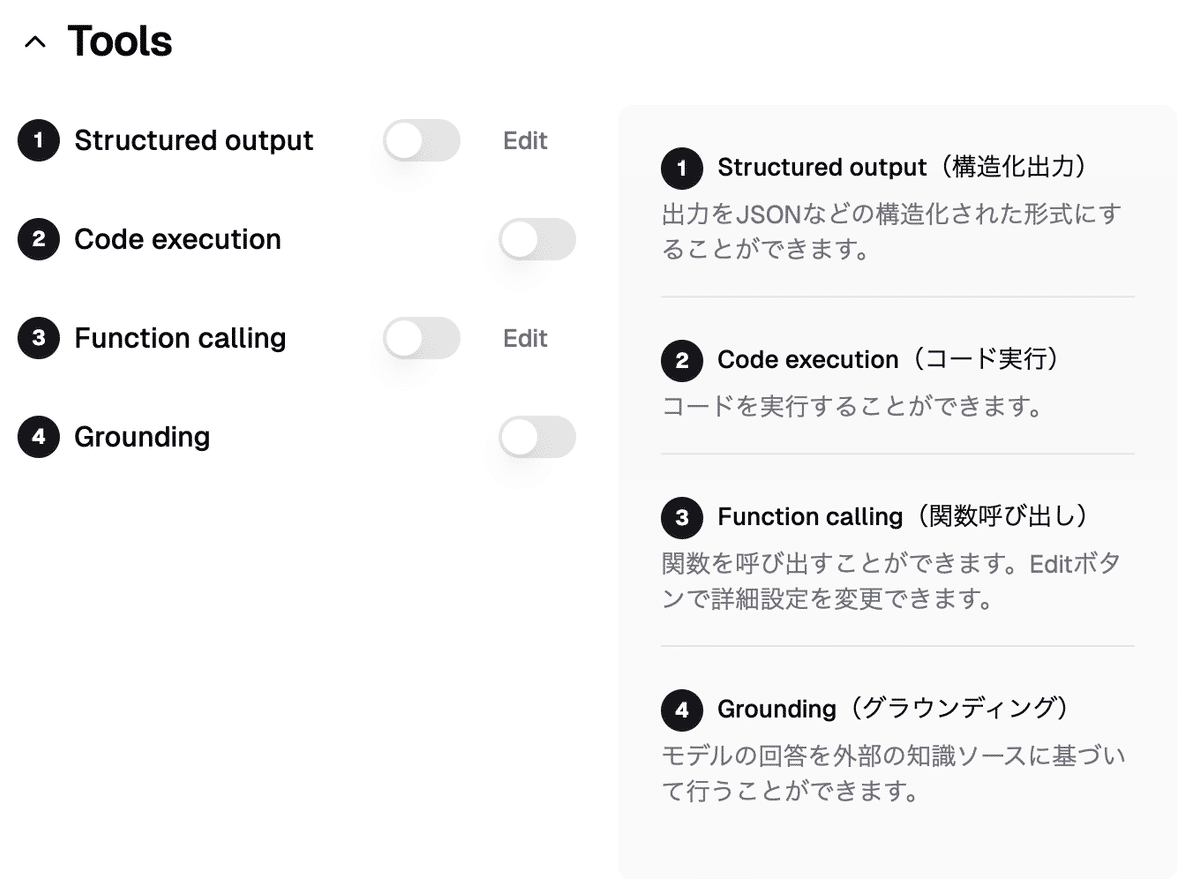
グラウディングをオンにすることで、Google検索を使って情報を検索した上で回答を生成するブラウジング機能が利用可能になります。

③Advanced settingsの設定
Advanced settingsでは、ストップシークエンスの設定や出力の長さの設定が可能です。
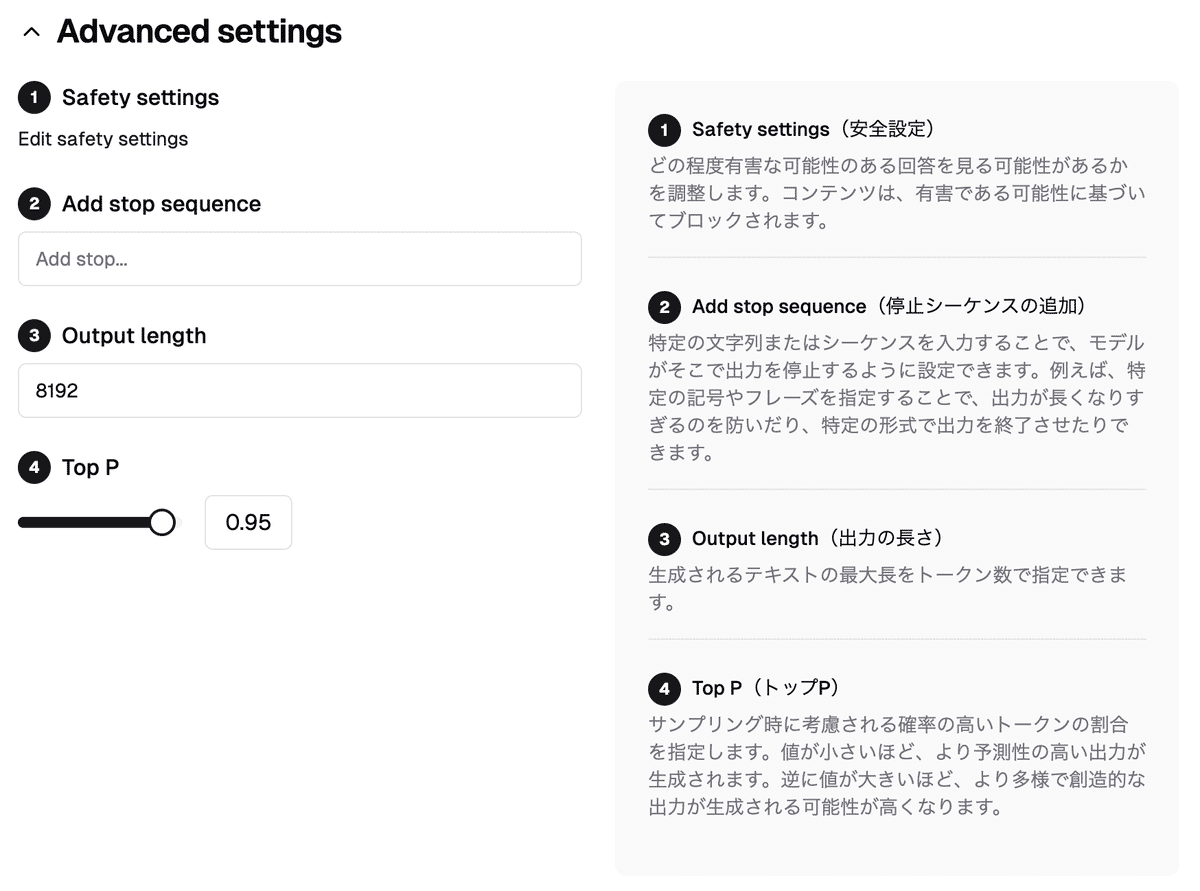
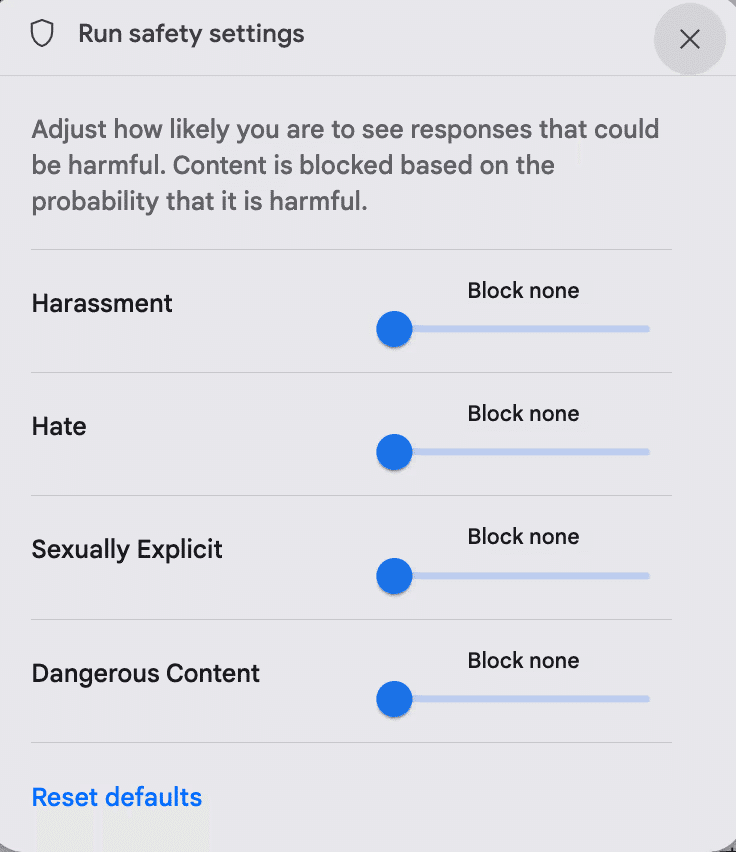
「Safety settings」では、ハラスメント、憎悪表現、性的な表現、危険なコンテンツの4つの項目のブロック度合いを設定することができます。
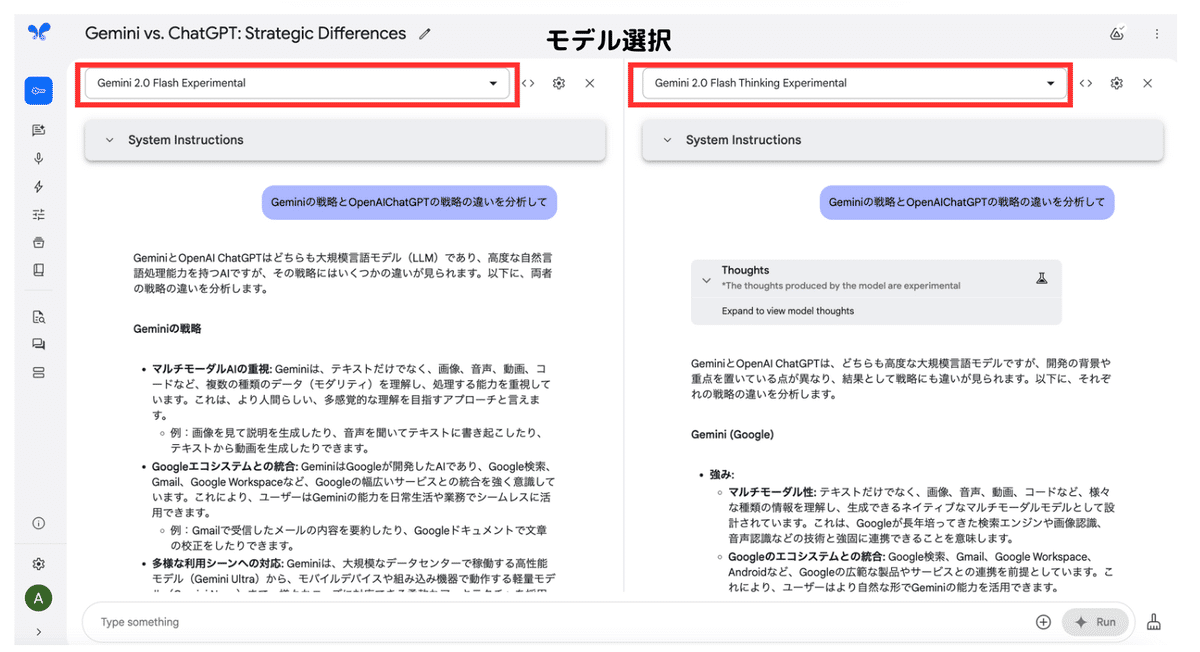
④モデル比較機能
チャットの右上にある「Compare」をクリックすると、モデルの出力結果の比較ができます。
④GoogleDrive保存機能
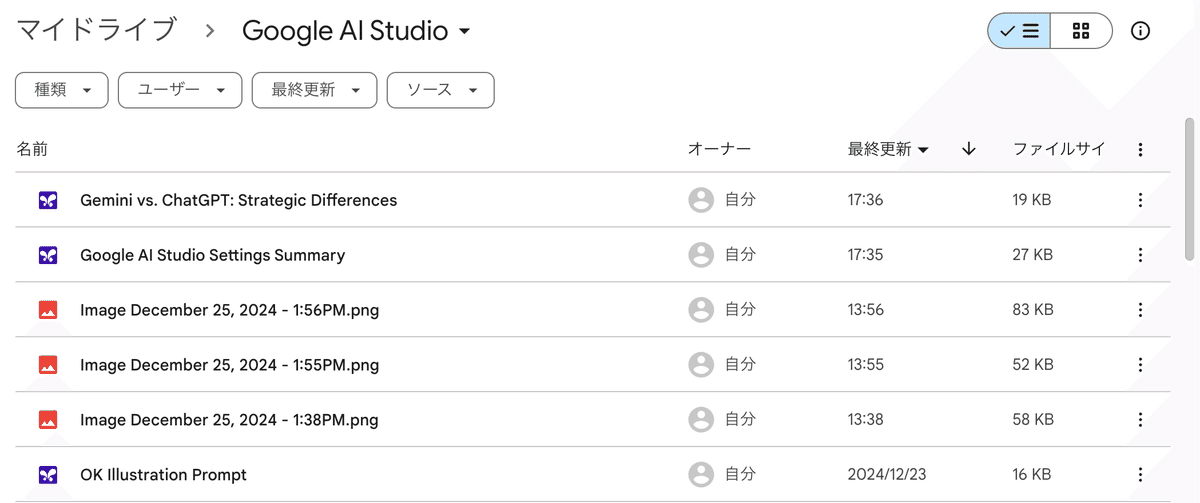
チャットの右上の「Enable Autosave」でGoogleアカウントと連携することでチャット履歴をDrive上に自動保存ができます。

連携するとGoogleDrive上に「Google AI Studio」フォルダが作成され、以下のようにチャット履歴とアップロードした画像・ファイルなどがフォルダに自動保存されます。
Prompt Gallery
Libraryの下にある「Prompt Gallery」では、プロンプトの事例とそのプロンプトでの出力結果を見ることができます。
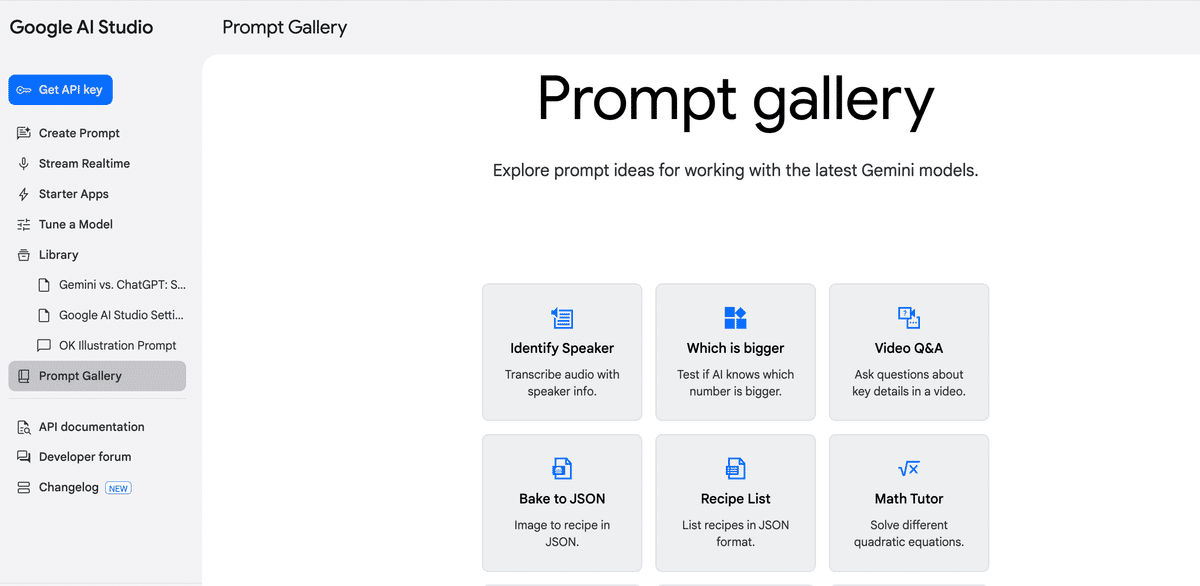
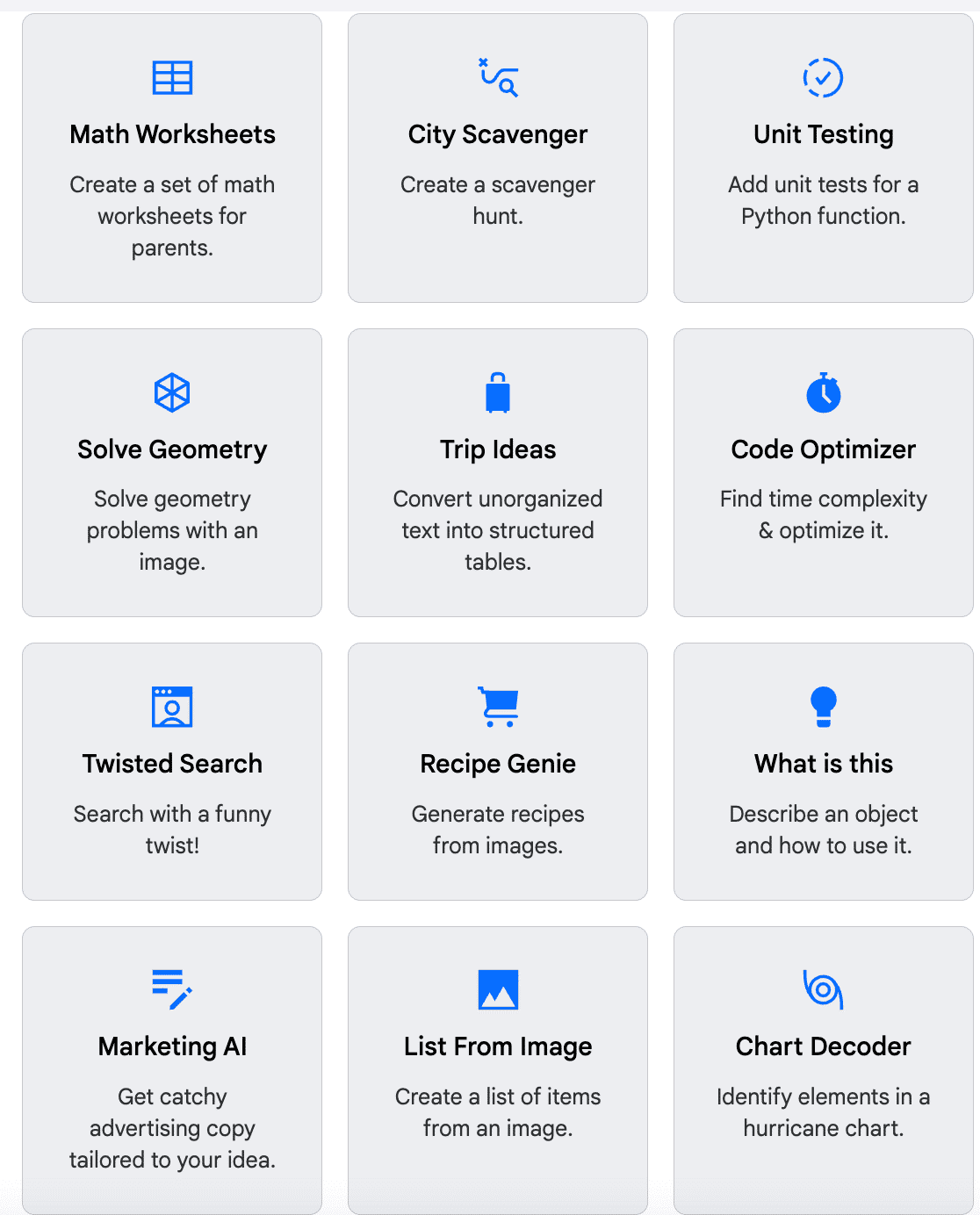
Geminiをどのように活用できるかの一例を見ることができます。
【応用編】Multimodal Live API
Multimodal Live APIとは
Multimodal Live APIは、Gemini 2.0 Flashで利用可能な、リアルタイムの音声・動画ストリーミングを処理するAPIです。
このAPIを使用することで、ユーザーの音声や動画入力に対して、AIモデルがリアルタイムに反応するアプリケーションを開発できます。
例えば、会話型AIエージェント、インタラクティブなゲーム、リアルタイム翻訳など、様々なアプリケーションに活用できます。人間と人間のコミュニケーションは、音声、視覚的な合図、リアルタイムの調整など、マルチモーダルなものです。
Multimodal Live APIの特徴
特徴としては、以下が挙げられます。
低レイテンシ: 最初のトークンを600ミリ秒で出力するなど、人間が期待する反応時間に合わせた低レイテンシを実現。
双方向ストリーミング: テキスト、音声、動画データを同時に送受信可能。
音声認識: 人間のような音声インタラクションをサポートし、音声アクティビティ検出などの機能を搭載。
動画理解: 動画入力を処理・理解し、音声と動画の両方のコンテキストを組み合わせて、より的確な応答を生成。
ツール統合: 関数呼び出し、コード実行、検索グラウンディングなどのツールを単一のAPI呼び出しに統合可能。





