

プロンプトエンジニアリングの分野は日々進化しています。今回は、GPT-3.5を活用した求人情報の分類の最適化をテーマとしたケーススタディを元に、プロンプトエンジニアリングの実用性とその課題を明らかにした論文をご紹介します。
参照論文情報
タイトル: Large Language Models in the Workplace: A Case Study on Prompt Engineering for Job Type Classification
著者:Benjamin Clavié, Alexandru Ciceu, Frederick Naylor, Guillaume Soulié, Thomas Brightwell
URL:[2303.07142] Large Language Models in the Workplace: A Case Study on Prompt Engineering for Job Type Classification (arxiv.org)
プロンプトエンジニアリングとは?

大規模言語モデル(LLM)を最大限に活用するためには、プロンプトの工夫が必要です。最近では、自社のアプリケーションにLLMを導入したい場合、モデルの微調整に加えて、「プロンプトエンジニアリング」という適切な自然言語プロンプトの設計も重視されています。これにより、訓練済みのモデルからの正確な推論と高い性能が期待できます。
ケーススタディの紹介
本研究で挑んだのは、難解なテキスト分類課題です。
「エントリーレベル」と表記されている求人の中で、実は35%以上が数年の経験を求めているとのデータが出ています。求職者のため、著者たちは新卒に最適な求人か、それとも経験が必要か、を自動で判別するAIを開発を目指しました。
求人が本当に適切かの判断は微細で、良い機会を逃さないためにも誤評価は極力避ける必要がありました。
プロンプトエンジニアリングがLLMの潜在能力を引き出す
著者たちは、10,000件のラベル付き求人データを使い、いくつかの機械学習手法を試しました:
伝統的な手法:SVM
事前学習モデル:ULMFiT、DeBERTa
大規模言語モデル:GPT-3、GPT-3.5
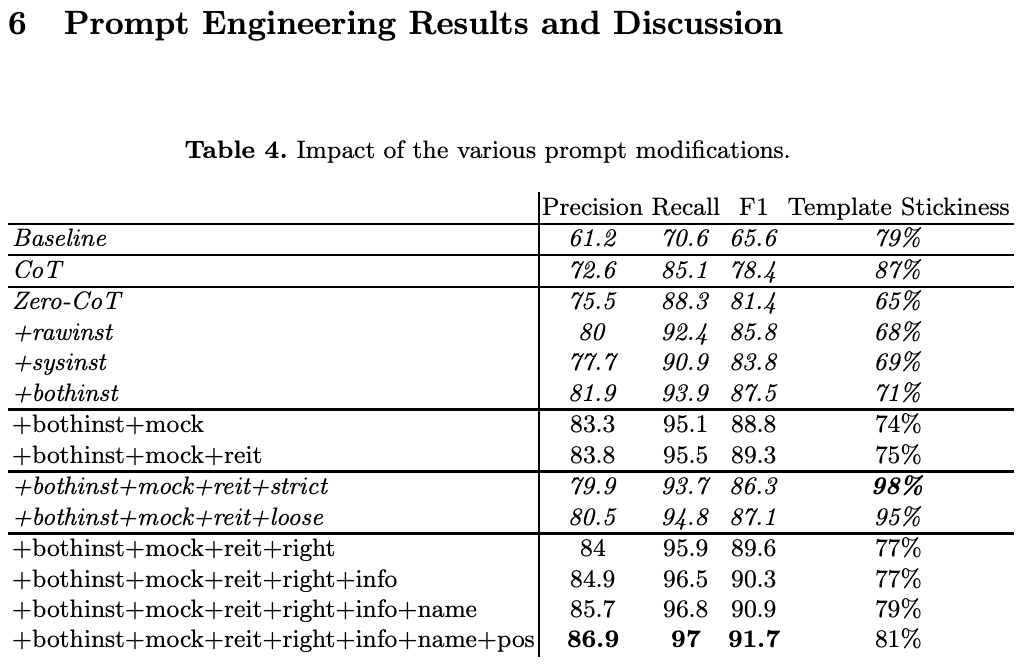
適切なプロンプトエンジニアリングを活用することで、GPT-3.5は95%のリコールと86.9%の精度を示し、他のモデルを凌ぐ結果を出しました。
最終的なプロンプトの工夫としては:
求人情報の明確な指示
推論をステップバイステップで行うこと
「フレデリック」と名付けたアシスタントへのポジティブなフィードバック
想定しないケースへ対応させる指示
これらの工夫により、GPT-3.5は豊富な訓練データを駆使し、求人情報が新卒向けかどうかを判断する微細な言語的手がかりを捉えました。
プロンプトエンジニアリングの具体的な例
具体的なプロンプトの例は以下のようなものがあります:
LLMからの推論の引き出し
ゼロショットのプロンプト
最もベーシックな方法
事前の説明や例の提示なしに、モデルに質問が提示される。
例:
For the given job: {job_posting}
Is this job (A) a job fit for a recent graduate, or (B) a job requiring more professional experience. Answer:
Few-ショットの連鎖思考プロンプト (CoT)
モデルに成功した分類の例を事前に提供する。
gpt-3.5のチャットモデルを利用し、ユーザーとアシスタントの間の会話を模倣した内容を提示する。
アシスタントに答えに至る前に、その理由を詳しく述べるように指示する。
例:
user message 1 = """For the given job:
{job posting}
---------
Is this job (A) a job fit for a recent graduate, or (B) a job
requiring more professional experience."""
assistant message 1 = "This job appears to be a senior position,
as it mentions requiring experience interacting with C-level
stakeholder in intense environments and [...]. Therefore,
this is (B) a job requiring more professional experience
user message 2 = [...]
ゼロショットの連鎖思考 (Zero-CoT)
モデルに事前の例を提供せずに推論を引き出す。
モデルに段階的に考えるように指示するアプローチ。
例:
For the given job: {job_posting}
-------
Is this job (A) a job fit for a recent graduate, or (B) a job requiring more professional experience.
Answer: Let's think step by step...
指示の提供
システムプロンプトの設定
指示について、役割に関するシステムプロンプトを設定:
role = """You are an AI expert in career advice. You are tasked with sorting through jobs by analyzing their content and deciding whether they would be a good fit for a recent graduate or not."""
タスクに関する詳細な説明
タスクの詳細に関するユーザーメッセージを提供:
task = """A job is fit for a graduate if it's a junior-level position that does not require extensive prior professional experience. I will give you a job posting and you will analyse it, to know whether or not it describes a position fit for a graduate."""
Mock
また、アシスタントが指示を確認するやりとりを模倣したものを提供:
user_message_1 = """A job is fit for a graduate [...] Got it?"""
assistant message 1 = "Yes, I understand. I am ready to analyze ֒→ your job posting."
明確な指示は、大幅な精度の向上につながりました。
微調整の影響
以下のような微調整を試みた結果も紹介されています。これらの調整もモデルの精度を向上させています。:
アシスタントの名前を「Frederick」とする
「Great!」のような肯定的なフィードバックを提供する
「正しい結論」を出力するように求める
誤った推論を防ぐための指示を明確にする
最も優れたパフォーマンスを出した最終的なプロンプト:
本研究で最も優れたパフォーマンスを出したプロンプトは以下の通りです。
system = "You are Frederick, an AI expert in career advice. You are tasked with sorting through jobs by analysing their content and deciding whether they would be a good fit for a recent graduate or not.",
user 1 = """A job is fit for a graduate if it's a junior-level position that does not require extensive prior professional experience. When analysing the experience required, take into account that requiring internships is still fit for a graduate. I will give you a job posting and you will analyse it, step-by-step, to know whether or not it describes a position fit for a graduate. Got it?"""
assistant 1 = "Yes, I understand. I am Frederick, and I will analyse your job posting.",
user 2 = """Great! Let's begin then :)
For the given job:
{job_posting}
---------
実験結果の概要
研究では、適切なプロンプトの使用により、LLMが専門的なモデルを超越することが確認されました。
主要な点:
プロンプトの適切な言葉遣いの影響: 一見些細な言葉の選び方が、モデルのパフォーマンスに大きく影響する。
単純な指示の追加だけで、F1スコアが5.9ポイント向上。
推論を促進する指示により、リコール率が95%を達成。
「ポジティブなフィードバックをする」などの小さな調整によって、全体の出力精度が向上。
制約の影響: 出力形式を制約する回答テンプレートを提示することで、出力の構造は整うが、パフォーマンスの低下が見られた。
結論
いかがだったでしょうか?推論の誘導、明確な指示、微調整などのプロンプトエンジニアリング手法を用いることで、GPT-3.5は高い精度を達成した一方で、プロンプトの言葉遣いにパフォーマンスが非常に敏感であることも分かりました。
プロンプトエンジニアリングには繊細なバランス調整が求められ、十分な研究とテストが必要不可欠です。今後、プロンプトエンジニアリングの技術が進歩すれば、LLMがより複雑な言語タスクをこなせる可能性があります。
これからも継続的に ChatGPT/AI 関連の情報について発信していきますので、フォロー (@ctgptlb)よろしくお願いします。この革命的なテクノロジーの最前線に立つ機会をお見逃しなく!





