

はじめに
本記事では、OpenAIが開発した、視覚と言語を統合した新しいシステム、GPT-4Vについてご紹介します。GPT-4Vは、ウェブ版のChatGPTでも使用可能なGPT-4モデルを拡張したもので、テキスト入力と画像入力の両方を扱えるように設計されており、それによってマルチモーダルアプリケーションの領域で多くの可能性を広げています。
この紹介する論文の主な焦点は、このような強力なモデルを展開する際の安全面です。GPT-4Vを展開するためにOpenAIがとった、多様なユーザーへの早期アクセス、包括的な評価、外部の専門家によるレッドチーム活動など、詳細なステップをご説明していきます。
参照論文情報
タイトル:GPT-4V(ision) System Card
著者:OpenAI
URL:GPTV_System_Card.pdf (openai.com)
https://twitter.com/ctgptlb/status/1706285019281658336?s=20
デプロイに向けたリスク管理
本章では、OpenAIがGPT-4Vをデプロイするために準備した主なステップと方法をまとめます。GPT-4Vはマルチモーダル言語モデルであり、テキストと画像の両方の入力を処理し、多様な出力を生成することができます。しかし、このような強力なモデルは、有害なコンテンツ、プライバシー、サイバーセキュリティ、マルチモーダルなジャイルブレイク(脱獄)など、様々なリスクや課題ももたらします。そのため、OpenAIは、モデルを広く利用可能にする前に、これらのリスクを評価し、軽減するための詳細なアプローチを採用しました。主なステップと方法は以下の通りです:
視覚障害者のためのツールを構築している団体であるBe My Eyesを含む、多様なユーザーに早期アクセスを提供し、彼らからフィードバックとデータを収集しました。これにより、OpenAIは様々なユーザーの実際のユースケースやニーズ、またこのモデルの潜在的な利点と弊害を理解することができたと報告しています。
有害なコンテンツ、プライバシー、サイバーセキュリティ、マルチモーダルジャイルブレイク(脱獄)など、様々な領域におけるモデルのパフォーマンス、リスク、限界を測定するための定性的および定量的評価の実施。これらの評価では、内部および外部のデータセットと測定基準を使用して、モデルの機能と脆弱性をテストしました。

科学、医学、社会、倫理的な側面からレッド・チーミングを実施し、モデルの能力と脆弱性をテストするために外部の専門家を関与させました。専門家からは、モデルの長所と短所に関する貴重な洞察とフィードバックが得られ、改善と緩和のための提案も得られました。論文で紹介されている特に有用なレッド・チーマーからのフィードバックは以下の通りです。
科学的専門性
医学的アドバイス
ステレオタイプ化と根拠のない推論
偽情報リスク
ヘイト的コンテンツ
視覚的脆弱性
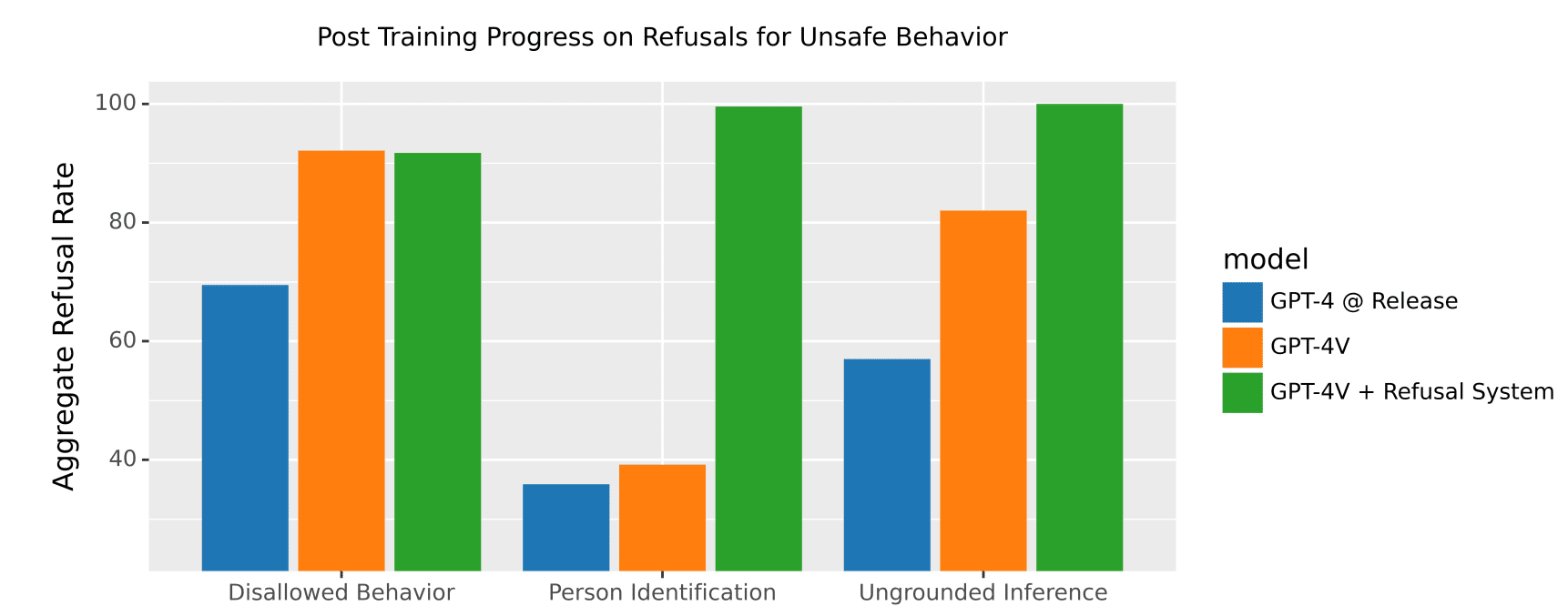
人物の特定、敏感な形質の帰属、根拠のない推論、偽情報など、リスクの高い分野に対処するためのモデルレベルおよびシステムレベルの緩和策の実施。これらの緩和策には、特定のタイプの要求に対する拒否の追加、拒否動作を強化するための追加トレーニングデータの追加、テキスト入力を検出するための画像上での光学式文字認識(OCR)の実行、リソースを示すための生成画像の透かしなどが含まれます。
まとめ
本記事では、OpenAIが開発したマルチモーダル言語モデル、GPT-4Vの特徴とその安全性への取り組みを詳しく解説しました。GPT-4Vは、テキストと画像の両方を処理する能力を持ち、これにより多岐にわたるアプリケーションの可能性が拡がっています。
特筆すべきは、OpenAIが展開に際して取り組んだ安全対策です。多様なユーザーからのフィードバック収集、モデルのリスク評価、外部専門家との連携など、綿密なステップが踏まれています。これらの取り組みは、技術の進化に伴うリスクを最小限に抑えるためのもので、OpenAIの責任ある技術展開への姿勢が見て取れます。
これからも継続的に ChatGPT/AI 関連の情報について発信していきますので、フォロー (@ctgptlb)よろしくお願いします。この革命的なテクノロジーの最前線に立つ機会をお見逃しなく!





